



基礎知識
NVIDIA AI Enterpriseとは?:導入のメリットからアーキテクチャとライセンス・運用設計のポイントまで解説
2026.04.13

GPUエンジニア
生成AIチャットやRAG、AIエージェントなど、企業におけるAI活用は急速に広がっています。一方で現場からは、「小規模な検証のたびに技術スタックが分断される」「クラウドとオンプレミスで運用設計が統一できない」「モデル更新やセキュリティ、ガバナンスの責任分界が曖昧になる」といった課題も多く聞かれます。
NVIDIA Enterpriseは、クラウド/オンプレミス/エッジといった異なる実行環境においても、同一の前提・同一の運用思想で開発するためのソフトウェアスタックを提供する企業向けプラットフォームです。
なお、NVIDIA Enterpriseでは、生成AI/AIエージェント開発を高速化する NVIDIA AI Enterprise と、デジタルツインや3Dワークフロー分野の開発を支援する NVIDIA Omniverse Enterprise といったソフトウェア群を提供しています。本記事では、主に NVIDIA AI Enterprise に焦点を当てて解説します。
【目次】
- NVIDIA AI Enterpriseとは?企業向けAIプラットフォームの全体像
- なぜNVIDIA AI Enterpriseを導入するのか:企業が得られるメリット
2-1. PoCから本番までを同じ前提で進めやすい
2-2. サポート・セキュリティ・安定性を前提に運用しやすい
2-3. NIMや対応ソフトウェアを活用し、立ち上がりを早めやすい - NVIDIA AI Enterpriseのアーキテクチャと主要コンポーネント
3-1. 実行基盤(GPU/仮想化/Kubernetes)
3-2. 開発・推論基盤(CUDA-X/NIM/NeMo/Triton)
3-3. 運用レイヤー(配布/セキュリティ/サポート) - NVIDIA AI Enterpriseが支える導入初期から本番運用までの開発プロセス
4-1. フェーズ別の設計ポイント
4-2. 導入から本番までを「1本でつなぐ」ために必要なこと - NVIDIA AI Enterpriseの展開パターン:GPUサーバー・クラウド・エッジの使い分け
5-1. 展開パターン(オンプレミス/クラウド/エッジ) - NVIDIA AI Enterpriseのライセンス形態とトライアル手段
6-1. ライセンスの提供形態
6-2. 評価・トライアルの進め方 - まとめ
1. NVIDIA AI Enterpriseとは?企業向けAIプラットフォームの全体像
社内でAI活用を進めようとすると、一般に次のような要素を整理する必要があります。
- AIモデル(GPT系、Llama など)
- ハードウェア(オンプレミスGPU、クラウドGPU など)
- AI基盤ソフトウェア(GPUドライバー、AIフレームワーク、推論・学習ランタイム など)
- 運用・保守(障害対応、バージョン管理、監視、更新計画 など)
このうち、NVIDIA AI Enterpriseが主に該当するのは、AI基盤ソフトウェアのレイヤーです。
NVIDIA AI Enterpriseでは、NVIDIA GPU上でAIを本番運用するための、標準化された、AIソフトウェア/システムを構築するための開発者向けツールが提供されます。
NVIDIA GPU Cloudにおける定義でも、AI Enterpriseは「NVIDIA AIプラットフォームのソフトウェア層」と位置づけられており、定期的なセキュリティレビュー、APIの安定性保証、サポートSLA(Service Level Agreement)など、企業利用を前提とした要素が含まれます。
AI Enterpriseには、CUDA-X、RAPIDS、NeMo、NIMなど、AI開発および推論で用いられる主要コンポーネントが含まれています。これらを検証・配布・運用条件まで含めて統一的に提供することで、クラウド・オンプレミス・ワークステーションを横断した共通AI基盤を設計しやすくすることが主な目的です。そのため企業視点では、クラウドごとに異なるAIサービスを個別利用する製品ではなく、「環境をまたいでも同一のソフトウェア層とサポート前提を維持するための基盤レイヤー」として整理できるでしょう。
なお、GPUリソースの割り当てや統合管理自体はKubernetesや仮想化基盤などの運用設計に依存します。あらかじめ「自社標準のAIスタック」として定義しておくことで、検証ごとにAI環境が増殖する状況を避け、チャットAIやRAGに加え、エージェントAIを含むユースケースについても、導入初期から本番、クラウドからオンプレミスまで同一前提で進めやすくなります。
では、こうした共通AI基盤をあらかじめ持つことで、企業は具体的にどのようなメリットを得られるのでしょうか。次章では、NVIDIA AI Enterpriseを導入する意義を、PoCから本番運用までの実務視点で整理します。
2. なぜNVIDIA AI Enterpriseを導入するのか:企業が得られるメリット
NVIDIA AI Enterpriseの価値は、企業がAIを本番で活用していくうえで、導入から運用までを進めやすくする点にあります。
2-1. PoCから本番までを同じ前提で進めやすい
AI導入の現場では、「試すための環境」と「本番のための環境」が分かれてしまい、PoCでは動いたのに本番移行で手戻りが発生することがよくあります。
NVIDIA AI Enterpriseを活用すると、PoCと本番で使うソフトウェア層や運用の前提をそろえやすくなるため、環境差による設計変更や再検証の負担を抑えやすくなります。
開発環境では問題なく動作していても、本番環境ではスケーラビリティや運用性の確保が課題になることがありますが、NVIDIA AI Enterpriseは、こうしたPoCと本番のギャップを小さくできる基盤として位置づけられます。
2-2. サポート・セキュリティ・安定性を前提に運用しやすい
もう一つ大きいのが、企業で安心して運用しやすいことです。
AIを本番で動かすときは、性能だけでなく、「問題が起きたときにどこに相談できるか」「アップデートで急に動かなくならないか」「脆弱性が見つかったときにどう対応するか」といった運用面が重要になります。
NVIDIA AI Enterpriseは、エンタープライズ向けサポート、セキュリティ更新、保守アップデートを前提に提供されており、企業が本番運用を進めやすい形になっています。
OSSを個別に組み合わせて使う場合、便利な一方で、問題が起きたときの切り分けや、更新時の確認、脆弱性対応を自社で広く見なければならないことがあります。
その点、NVIDIA AI Enterpriseでは、サポート対象のソフトウェアや更新の考え方が整理されているため、運用時の不安を減らしやすくなります。
特に本番運用向けの提供形態では、安定して使うことを重視したソフトウェア提供と、脆弱性に対する定期的な更新が行われるとされています。
2-3. NIMや対応ソフトウェアを活用し、立ち上がりを早めやすい
NVIDIA AI Enterpriseのメリットとしてさらに挙げられるのが、AI環境を一から細かく組み上げなくても、立ち上げを進めやすいことです。
企業でAIを導入するときは、モデルだけでなく、推論エンジンや依存ライブラリ、実行環境の整合など、周辺の準備にも時間がかかります。NVIDIA AI Enterpriseでは、NVIDIAがサポート対象として整理したソフトウェア群を利用できるため、必要な部品を選びやすくなります。
特に、生成AIや推論の立ち上げで重要になるのがNVIDIA NIMです。
NIMは、AIモデルを動かすために必要な推論エンジンや依存関係をまとめたマイクロサービスとして提供されており、標準的なAPIで利用しやすい形に整理されています。
そのため、企業にとっては、検証済み・サポート対象の部品を活用しながら、PoCや初期導入をより早く立ち上げやすい点が大きな利点になります。
このように、NVIDIA AI Enterpriseの価値は、PoCから本番へのつながり、サポートとセキュリティ、立ち上がりの速さを通じて、企業のAI基盤を整備しやすくすることにあります。
3. NVIDIA AI Enterpriseのアーキテクチャと主要コンポーネント
NVIDIA AI Enterpriseのソフトウェアスタックは、「実行基盤+AI実行・開発スタック+運用レイヤー」をまとめたソフトウェアスイート(複数の独立したソフトウェアを連携しパッケージ化したもの)として整理できます。
- 実行基盤(Infrastructure)
- AI実行・開発スタック(AI Runtime / Tooling)
- 運用レイヤー(Enterprise Operations)
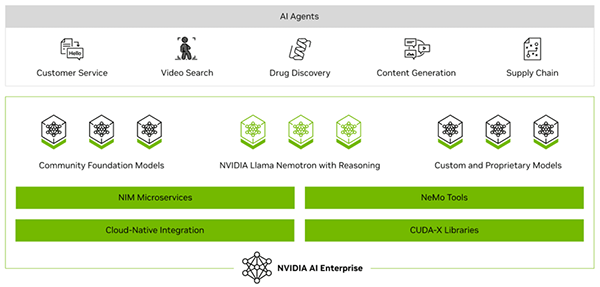
この後、この構造を前提に各レイヤーの役割を順に見ていきます。
3-1. 実行基盤(GPU/仮想化/Kubernetes)
最下層に位置するのが、AIを実際に動かすための実行基盤です。
NVIDIA AI Enterprise自体はソフトウェアスイートであり、実行環境としては次のような構成と組み合わせて利用されます。
- NVIDIA GPUを搭載したサーバー/ワークステーション
- 仮想化基盤(VMware vSphere など)
- Kubernetes などのコンテナ基盤
どの構成を採用するかは、既存のインフラ方針や運用体制に依存します。重要なのは、このレイヤーでは環境差があっても、上位のAIスタックを共通化できる設計にしておくことです。
NVIDIA AI Enterpriseは、GPUの割り当てやクラスタ管理そのものを担うわけではありませんが、「その上に載せるAIの実行環境を標準化する」ことで、クラウド/オンプレミスといった環境差を吸収しやすくします。
3-2. 開発・推論基盤(CUDA-X/NIM/NeMo/Triton)
実行基盤の上に載るのが、AIの開発・推論を実際に担うソフトウェアスタックです。
NVIDIA AI Enterpriseに含まれる主要コンポーネントは、役割別に整理すると次のようになります。
| レイヤー | 主要コンポーネント | 役割 |
|---|---|---|
| GPU最適化 | CUDA-X、RAPIDS | データ処理・従来型ML・DL学習をGPU上で高速化 |
| 推論基盤 | TensorRT、Triton Inference Server | モデル最適化とスケーラブルな推論配信の土台 |
| 生成AI | NeMo / Guardrails など | LLM学習・微調整、RAGパイプライン、安全性制御 |
| NIM | NVIDIA NIM inference microservices | 事前学習済み/カスタムモデルの推論をコンテナ化したマイクロサービスとして提供 |
この中でも NVIDIA NIM(NVIDIA Inference Microservices)は、生成AI向けの中核となる推論基盤として位置づけられます。NIMは「推論マイクロサービスを自己ホストするためのコンテナ」として提供され、クラウド/データセンター/RTX AI PC・ワークステーションなどに展開できます。コンテナ内部にはモデルと推論エンジン、依存ライブラリがあらかじめ組み込まれており、HTTPベースの標準的なAPIを通じてアプリケーションから利用できる構成です。
推論エンジンとしては、TensorRT / TensorRT-LLMを中心に、vLLMやSGLangなどコミュニティ側の実装も含めた形で整理されています。環境やワークロードの特性に応じて適切なエンジンを選択できるようにしている点が特徴です。
3-3. 運用レイヤー(配布/セキュリティ/サポート)
企業の本番運用では、機能そのもの以上に運用前提が重要になります。NVIDIA AI Enterpriseは、次のようなエンタープライズ要件もカバーします。
- 検証・配布の前提
NGC Catalog 上で「AI Enterprise向け」「Supported」などが明示され、利用可能なソフトウェアとサポート範囲が整理されています。 - セキュリティ
CVE などの脆弱性スキャンを前提とした配布・更新が行われます。 - サポート
AI Enterpriseライセンスに紐づくエンタープライズ向けサポートが提供され、必要に応じて上位サポートへの拡張も可能です。
「GPUにOSSを自由に積んだ環境」と比べると、責任分界とサポート範囲が明確になる点が、運用フェーズでは大きな違いになります。
4. NVIDIA AI Enterpriseが支える導入初期から本番運用までの開発プロセス

AIプロジェクトは、本来「小さく試して、そのまま大きく育てる」のが理想です。しかし現実には、導入初期の検証では手軽なクラウドサービス、本番運用はオンプレミスGPU、そして運用段階では仕様や環境の見直しが必要となるケースも多く、フェーズごとに技術スタックが切り替わってしまうことが、移行コストや手戻りの大きな原因となっています。
ここで有効なのが NVIDIA AI Enterprise です。ここでは、導入から本番までの各フェーズで「どのようにNVIDIA AI Enterpriseが効いてくるか」を整理します。
4-1. フェーズ別の設計ポイント
各フェーズで押さえておきたいポイントを、NVIDIA AI Enterpriseの観点から整理します。
- 技術検証フェーズ
導入初期では、「技術的に実現可能か」「価値があるか」を確認することが目的です。ここで、検証専用のクラウドサービスや単一ツールに寄せすぎると、本番環境(オンプレミスGPUなど)への移行時に、アーキテクチャを大きく変えざるを得ないケースがあります。可能であれば、最初から「NVIDIA AI Enterprise+Kubernetes」など、本番側と親和性の高いスタック上で初期の検証を行うことで、実装資産や運用ノウハウをそのまま次フェーズに持ち越しやすくなります。 - パイロットフェーズ
単一ノードで動く小規模な検証環境から、複数ノードのクラスタ構成に広げるときに、「NIMでモデル提供インターフェースを揃える」「Kubernetes上で水平展開」といった設計にしておくと、拡張の見通しが立てやすくなります。ログ・メトリクス・トレースなどの運用監視の設計も、このフェーズで固めておくと、本番展開に向けた準備が大幅にスムーズになります。 - 本番運用・横展開フェーズ
実際に運用を開始すると、重要になるのがログ・監査・アラート、モデル更新時の検証フロー、責任分担など、「運用設計とガバナンス」が中心テーマになります。NVIDIA AI Enterpriseは、セキュリティスキャン済みのソフトウェア配布、LTSB(Long Term Support Branch)などの運用方針、エンタープライズサポート(Business Standard / Critical)を備えており、AI基盤を「社内共通サービス」として提供できる状態を作りやすい構成になっています。
4-2. 導入から本番までを「1本でつなぐ」ために必要なこと
NVIDIA AI Enterpriseを軸にすることで、次の3点で導入プロセスが一気通貫になります。
- インフラレイヤーの共通化
クラウドでもオンプレミスでも「Kubernetes+NVIDIA AI Enterprise」で構成を統一すれば、GPUの見え方や運用方式を標準化できます。 - モデル提供のインターフェース統一
NIMマイクロサービスのエンドポイントをアプリケーション側の標準にすることで、モデルの入れ替え・最適化を基盤側で完結でき、アプリケーション改修を最小限に抑えられます。 - 運用・ガバナンスのテンプレート化
サポート前提の配布物+明確なブランチ構成(FB/PB/LTSB)に基づく設計で、ログ/監査/更新フローをテンプレート化できます。
結果として、「検証専用スタック」と「本番専用スタック」が分かれるのではなく、最初から本番を見据えたスタック上で"小さく始めて大きくする"進め方を取りやすくなるのが、NVIDIA AI Enterpriseの大きな価値だといえるでしょう。
5. NVIDIA AI Enterpriseの展開パターン:GPUサーバー・クラウド・エッジの使い分け
次に、インフラ側の視点から見たときに、NVIDIA AI Enterpriseがどのような構成パターンで展開されるかを整理します。
5-1. 展開パターン(オンプレミス/クラウド/エッジ)
NVIDIA AI Enterpriseは、「どこで動かすか」によって構成パターンが変わりますが、大枠としては次の3パターンを押さえておくと整理しやすくなります。
| 構成パターン | 用途 | 主な構成要素 |
|---|---|---|
| オンプレミスGPUサーバー | 機密データ・低レイテンシワークロード | NVIDIA Certified Systems + vSphere/K8s + NVIDIA AI Enterprise |
| クラウド・ハイブリッド | 小規模評価・バースト負荷対応 | AWS / Azure / Google Cloud など + マーケットプレイス or BYOL |
| ワークステーション・エッジ | プロトタイピング・リアルタイム推論(小規模) | RTX搭載ワークステーション / Jetsonなど(用途により異なる) |
オンプレミスGPUサーバー中心の構成では、NVIDIA Certified SystemsとNVIDIA AI Enterpriseをベースに、部門横断の共通AI基盤として運用するケースが想定されます。クラウド・ハイブリッド構成では、本番や機密データ系の処理はオンプレミスGPUサーバー側に寄せつつ、短期的な評価や一時的に高まる負荷への対応をクラウド側で行う、といった役割分担が取りやすくなります。ワークステーション・エッジ構成では、開発者向けのRTX搭載ワークステーション上に小規模な環境を用意し、プロトタイピングやリアルタイム推論を手元で回す使い方が中心になります。その上で、負荷や運用要件に応じて、サーバー/クラウド環境への展開を検討する流れになります。
一方で、Jetsonのような組み込み系エッジはJetPack中心の運用になることが多く、AI Enterpriseと同一スタックで統一する場合は、アーキテクチャ差分(OS/アーキテクチャ、運用方式、配布形態など)を事前に切り分けて設計する必要があるでしょう。
6. NVIDIA AI Enterpriseのライセンス形態とトライアル手段
NVIDIA AI Enterpriseのライセンスは、基本的にGPU単位(per-GPU)で整理されています。サーバーやワークステーションに搭載されているGPUの本数に応じて必要なライセンス数が決まり、複数GPU構成ではその分だけライセンスが増加します。
6-1. ライセンスの提供形態
提供形態としては、年間サブスクリプションや永続ライセンスなどが用意されています。
価格や個別の条件は、GPU構成や契約期間、サポートレベル、購入チャネルなどによって変動するため、詳細やお見積もりについてはNTTPCまでお気軽にお問い合わせください。
6-2. 評価・トライアルの進め方
NVIDIA AI EnterpriseやNIM/NeMoを本格導入する前に、利用感や運用イメージを掴むためのトライアル手段も用意されています。
代表的な手段は、次の3つです。
| 手段 | 位置づけ | 確認できる内容の例 |
|---|---|---|
| NVIDIA API Catalog | NVIDIAがホストするNIM APIをオンラインで呼び出せるカタログ。ブラウザや簡単なスクリプトから試すことができる | APIとしての呼び出し方、レスポンス特性、提供されているモデルの種類 |
| NVIDIA LaunchPad | 評価用の環境とハンズオンコンテンツをセットで提供するプログラム。事前構成済みのクラウド環境で操作できる | 一連のワークフロー、管理コンソールの操作感、基本的なパフォーマンスやスケーリングのイメージ |
| 評価ライセンス (例:90日間) |
自社のオンプレミスGPUサーバーやクラウド環境にNVIDIA AI Enterpriseを導入し、一定期間試用するためのライセンス | 自社ネットワーク/セキュリティ要件との整合性、既存Kubernetes/仮想化基盤との相性、社内運用手順 |
どの手段を使うかは、「APIレベルの挙動を確認したいのか」「運用担当も含めてワークフロー全体を体験したいのか」「本番に近い自社環境で制約条件まで洗い出したいのか」といった目的によって変わります。評価のゴールを先に決め、そのうえで適切な組み合わせを選ぶと良いでしょう。
各トライアル手段の詳細や比較については、NTTPCのNVIDIA Enterpriseページをご覧ください。
7. まとめ
NVIDIA AI Enterpriseは、NVIDIA GPU上にAIスタックと配布・セキュリティ・サポートの前提をまとめて提供する「企業向けAIプラットフォーム」です。個別案件ごとに異なるスタックを積み上げるのではなく、NVIDIA AI Enterpriseを用いて「自社の標準AIスタック」を定義することで、導入初期から本番運用、さらには全社展開までの道筋を描きやすくなります。特に、GPUサーバーやクラウド環境をすでに保有している企業ほど、インフラレイヤーとAIスタックを一体で設計する効果は大きくなります。
一方で、自社にとって最適なAI基盤の構成や、NVIDIA AI Enterpriseをどこまで標準スタックとして組み込むかは、既存インフラや想定ユースケースによって変わります。GPUサーバーやクラウド環境の選定とあわせて、検証・評価用の初期構成から本番クラスタ構成までをあらかじめマッピングしておくことで、投資計画や更改サイクルの整理もしやすくなります。
NTTPCは、NVIDIA エリートパートナーとして、NVIDIA AI Enterpriseの導入やライセンス検討、GPUクラスタ環境への展開をご支援します。具体的な構成やお見積もり、評価環境の検討など、お気軽にお問い合わせください。
▶︎ お問い合わせはこちら
※本記事の内容は2026年2月時点の公開情報をもとに作成しています。
※「NVIDIA」、「NVIDIA AI Enterprise」、「CUDA」、「RAPIDS」、「NeMo」、「NIM」、「TensorRT」、「Triton Inference Server」、「Jetson」、「Base Command」、「JetPack」は、NVIDIA Corporationの商標または登録商標です。その他記載の会社名、商品名は、各社の商標または登録商標です。