



基礎知識
企業のRAG導入とGPU活用のメリットと構築フローを解説
2025.03.21

GPUエンジニア

生成AIの活用が進む中、多くの企業がオンプレミス環境やローカル環境でのRAG(検索拡張生成)導入や、クラウド依存を減らしたAI運用を検討しています。
しかし、RAGの検索フェーズや大規模言語モデル(LLM)の推論処理には、膨大な計算リソースが必要であり、適切なインフラ選定が欠かせません。
特にGPUは、検索精度の向上や推論の高速化を実現する重要な要素であり、ローカル環境やオンプレミスでのRAG運用には不可欠な技術です。
本記事では、RAGとGPUの関係の詳細、企業がローカル環境でRAGを活用する際のポイントについて、わかりやすく紹介します。オンプレミスとクラウドの選択に悩んでいる企業や、GPUの導入を検討している開発者の方は、ぜひ参考にしてください。
目次:
- RAGとは
- LLMの弱点を補うRAGとGPUの関係
- 生成AIとGPUの関係
3.1 学習フェーズ
3.2 検索フェーズ
3.3 推論フェーズ
3.4 その他:運用コストと消費電力 - オンプレミス環境でRAGを活用するメリット
4.1 主なメリット一覧 - RAG運用環境におけるクラウドとオンプレミス環境の比較
5.1 オンプレミスとクラウド環境の比較表 - 実際の導入ステップ:RAG×GPUの構築フロー
6.1 要件定義・PoC(概念実証)
6.2 システム環境設計
6.3 GPU導入設計
6.4 RAGモデル設計・最適化
6.5 運用・保守 - RAGを用いた生成AI活用事例
7.1 主な活用分野 - まとめ
はじめに
近年、ChatGPTをはじめとするLLMの普及が進み、多くの業界で活用されています。その中で、RAGは、LLMが外部データを活用し、より正確で信頼性の高い回答を生成する技術として注目されています。
このRAGの処理にはGPUが重要な役割を果たしています。GPUを活用することで、検索・推論処理が高速化され、膨大な社内データを基にした素早く正確な回答が可能になります。
では、そもそもRAGとはどのようなものでしょうか。それぞれの概要を説明します。
RAGとは
RAG(Retrieval-Augmented Generation:検索拡張生成)は、LLMと外部データベースや文書検索を組み合わせることによって、より正確な情報を回答する手法です。LLM単体の文書生成では、リアルタイムのデータや社内の独自情報を取得することはできません。そこで、RAGを活用することによって、LLMが知らないような最新の情報や社内のデータベースを基にした回答が可能になります。
GPUはもともと画像処理のために設計されたハードウェアですが、並列処理能力の高さ から、LLMの学習や推論処理に適した計算リソースとして活用されています。
LLMの弱点を補うRAGとGPUの関係
生成AIの活用が進む一方で、LLMには学習データの更新頻度の制約があり、リアルタイムの最新情報を扱うことが難しいという課題があります。この課題を解決する手法として、RAGが注目されています。
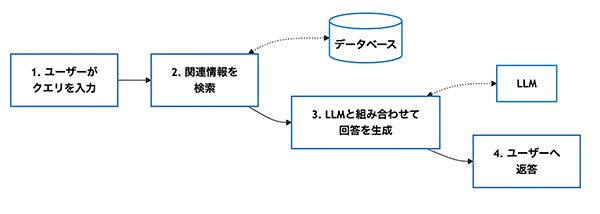
図1. RAGの仕組みイメージ
次のような手順でRAGの処理は行われます。
1. ユーザーがクエリ(質問)を入力
ユーザーが質問を入力すると、RAGの処理が開始されます。
2. データベースから関連情報を検索
- クエリをもとに、関連するデータを検索するため、Embedding(単語や文章をベクトル化する手法) が用いられます。
- ベクトル検索を行い、類似性の高い情報を取得します。
- 小規模データではCPUでも処理可能ですが、大規模データの検索ではGPUを活用することで検索速度を向上できます。
3. LLMと組み合わせて回答を生成
- 検索された情報をもとに、LLMが適した形で回答を作成します。
- LLMの推論には大量の計算が必要なため、GPUによる高速処理が不可欠です。
- 活用例:GPTシリーズ、Claude、Gemini、Llama などのモデル推論
4. ユーザーへ返答
生成された回答をユーザーに提供します。
RAGを導入することで、AIの回答精度が向上し、より実用的な形でビジネスに活用できるでしょう。
生成AIとGPUの関係
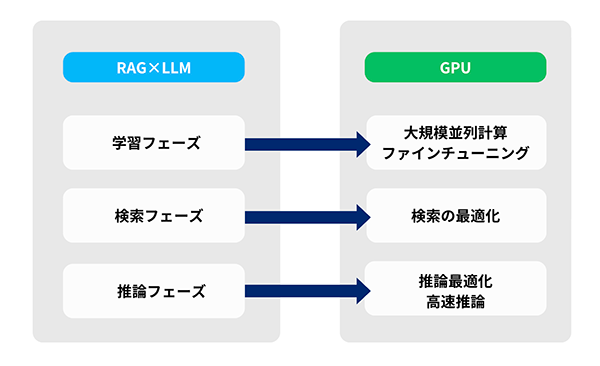
図2. RAG×LLMとGPUの関係イメージ
RAG×LLMの性能向上には、GPUが重要な役割を果たします。では、GPUはどのような場面で活用され、どのような利点をもたらすのでしょうか?
次のとおり、RAG×LLMにおけるGPUの活用領域をまとめました。
| 活用領域 | GPUの利点 |
|---|---|
| 学習フェーズ | 大規模データの学習時間を短縮し、ファインチューニングを効率化 |
| 検索フェーズ | ベクトル検索・類似検索を高速化し、RAGの応答速度を向上 |
| 推論フェーズ | LLMの推論速度を向上させ、リアルタイム処理のレイテンシを削減 |
1. 学習フェーズ
- LLMは、大量のテキストデータを学習する必要があり、この学習には膨大な行列演算が発生します。
- GPUの並列処理能力を活用することで、学習時間を短縮し、ファインチューニングを効率化できます。
2. 検索フェーズ
- RAGでは、クエリと文書をベクトル化し、それらの類似度に基づいて検索を行うため、大量のデータを効率的に処理する必要があります。
- GPUを活用することで、このベクトル演算を並列処理し、大規模データの検索速度を向上させることができます。
3. 推論フェーズ
- LLMを実際に動作させる際も、大量の計算が必要となります。
- GPUを活用することで、ユーザーの入力に対して高速に応答を生成でき、レイテンシ(遅延時間)を大幅に改善できます。
- 特に、リアルタイムの対話や文章生成を行うシステムでは、CPUのみの処理では速度が不足しがちなため、GPUによる並列計算が重要になります。
4. その他:運用コストと消費電力
- 生成AIの学習や推論には膨大な電力と計算リソースが必要であり、GPUの効率的な活用が求められます。
- クラウドベースのGPUインスタンス(Azure、AWS、Google Cloudなど)は、初期投資を抑えつつ、高性能な計算リソースを利用できます。
- 一方で、機密データ(顧客情報、個人情報、ライセンス契約情報、開発データなど)を扱う企業や長期的な運用コストを抑えたい企業にとって、オンプレミス環境へのGPU導入が選択肢となるでしょう。
オンプレミス環境でRAGを活用するメリット
RAGと生成AIのパフォーマンスは、システムの応答速度や処理能力に大きく左右されます。業務の効率化を図るには、検索や推論をリアルタイムに近い速度で実行することが重要です。
特に、大量のデータを扱う企業や多くのユーザーが同時にアクセスするシステムでは、高い並列処理能力を持つハードウェアの導入がパフォーマンス向上の鍵となります。GPUを活用することで、大規模なデータ検索の高速化やLLMの推論速度の向上が可能になり、スムーズな処理を実現できます。
主なメリット一覧
| メリット | 説明 |
|---|---|
| 高速な検索・推論処理 | GPUの並列処理により、大規模データの検索・推論をリアルタイムに近い速度で実行可能 |
| 機密データの保護 | オンプレミス環境なら、クラウドを介さずにデータを処理でき、セキュリティリスクを低減できる |
| 長期的なコスト最適化 | クラウドのGPU利用コストと比較し、長期的にはオンプレミスのほうがコストを抑えやすい |
| システムの安定運用 | クラウドの通信遅延やサーバー負荷の影響を受けず、安定したレスポンスを維持可能 |
GPUの並列処理能力を活かせば、待機時間を短縮し、迅速な応答を実現できます。特に、機密データの保護、レスポンス速度の最適化、長期的な運用コストの削減といった課題を抱える企業にとっては、オンプレミス環境にGPUを導入し、RAGを運用することが有効な選択肢となるでしょう。
RAG運用環境におけるクラウドとオンプレミス環境の比較
オンプレミス環境では、GPUを活用することでRAGの検索・推論処理を最適化することができます。一方、クラウド環境ではスケーラビリティや初期コストの抑制がメリットとなります。
以下の表に、RAG運用環境におけるオンプレミスとクラウド環境の比較をまとめました。導入時の参考にしてください。
オンプレミスとクラウド環境の比較表
| 選択肢 | オンプレミス(自社運用) | クラウド環境(API利用) |
|---|---|---|
| スピード | 低遅延・リアルタイム処理が可能 | クラウド処理のため、場所によっては若干の遅延が生じる場合あり |
| コスト | 初期費用が発生するが、長期利用の場合は総コストを抑えられる | 初期費用を抑えられるが、長期利用の場合は総コストを高額になる可能性 |
| データの機密性 | 機密情報を社内で完結できる | クラウド環境へのデータアップロードが必要 |
| スケーラビリティ | 制限あり(GPUの増設が必要な場合がある) | 容易(GPUリソースの自動スケールが可能な場合が多い) |
| 運用負担 | 高(自社でメンテナンスが必要) | 低(クラウドベンダーが管理) |
NTTPCは、用途に合わせた適切なGPUの選定はもちろん、データセンターやネットワーク、ストレージも含めたAI基盤全体の設計、導入支援を行っています。 生成AIの学習・推論にGPUの活用を検討されている 企業のご担当者様はお気軽にご相談ください。
実際の導入ステップ:RAG×GPUの構築フロー
社内で活用したい場合、RAGと高性能なGPU環境はどのように構築するのが良いのでしょうか。RAG×GPUの導入プロセスを5つのステップに分けて解説します。

1. 要件定義・PoC(概念実証):まずは適用範囲を明確にする
導入の第一歩は、ビジネス課題の整理と適用範囲の特定です。
- 課題の明確化:AIを活用したい業務領域(カスタマーサポート、自動文書生成、データ検索など)を特定
- 必要なデータソースの確認:内部文書、FAQ、ナレッジベースなどRAGで参照するデータを整理
- 検索精度・生成品質の要件定義:RAGの精度、検索速度、応答時間の目標を決定
- PoC(概念実証)の実施:小規模なローカル環境でテストし、GPUの必要性や性能要件を検証
PoCの段階で生成品質や検索精度が業務要件を満たすかを見極めることが、スムーズな本番導入につながります。
2. システム環境設計:オンプレミス/クラウドの選択
GPUを導入する際は、セキュリティ、コスト、運用負荷などの観点から、まずオンプレミスとクラウドのどちらの環境を選択するか検討する必要があります。
- オンプレミスの特長
- セキュリティ:社内ネットワークで管理し、機密データの取り扱いに適する
- コスト:初期投資は高いが、長期的な運用では総コストを抑えられる可能性がある
- 性能:専用のGPU環境を構築でき、低レイテンシでの処理が可能
- クラウドの特長
- スケーラビリティ:必要に応じてGPUリソースを柔軟に増減できる
- コスト:初期投資を抑えつつ、使用量に応じた従量課金モデルを採用可能
- 運用負荷:ハードウェアの管理が不要で、システム運用の負担を軽減
それぞれの特長を踏まえ、自社のニーズや運用体制に適したGPU環境を選択しましょう。
GPUにかかるコスト試算
オンプレミスでGPUサーバーを導入する場合、どのくらいのコストが発生するのでしょうか?GPUサーバーのコストを把握するには、見積シミュレーションを活用すると便利です。NTTPCが提供するGPUサーバー見積シミュレーター※は、GPUの種類やサーバー構成を選択し、導入コストを簡単に試算できます。
※ 本シミュレーション金額は概算料金です。為替や市場在庫の状況により、料金は大きく変動する場合があります。また、本シミュレーターではSupermicro製品の価格を試算できます。その他メーカーの見積をご希望の方はお問い合わせください。詳しくはお問い合わせください。
3. GPU導入設計:処理負荷に応じた環境構築
PoCの結果をもとに、本番運用に必要なGPUサーバー環境を設計します。
- GPUの選定:メーカー、型番比較検討
- システム全体のアーキテクチャ設計:RAGの検索処理、LLMの推論、データ管理を最適化
GPU環境は、学習フェーズ・推論フェーズの負荷を見極めて適切に設計することが重要です。
4. RAGモデル設計・最適化:精度向上と推論効率の最適化
GPU環境を整えたら、RAG×生成AIのモデルを本番運用に向けてチューニングします。
- 適切なLLMの選定:用途に応じたモデル(GPT、Claude、Geminiなど)を選択
- ベクトル検索エンジンの導入:検索精度を向上
- ファインチューニングの実施:業務データを学習させ、企業独自のナレッジを活用
- GPUの最適化:量子化・スパース化を行い、推論速度とコストを最適化
特に、リアルタイム処理が求められる場合は、推論の最適化がGPUリソースの有効活用につながります。
5. 運用・保守:継続的な最適化とコスト管理
本番運用後も、継続的なチューニングと運用負荷の最適化が必要です。
- モデルの精度向上:RAGの検索精度、LLMの応答品質を定期的に検証
- GPUの負荷監視とコスト管理:クラウドGPUのスケーリング、オンプレGPUの適切な利用
- データ更新の自動化:最新の企業データを常に反映し、RAGの検索精度を維持
- 障害対策とスケールアップ対応:高負荷時のリソース調整、障害発生時の対応フローを構築
運用・保守はAIの精度とコストをバランスよく管理しながら、持続可能なシステム運用を実現することが鍵となります。
RAGを用いた生成AI活用事例
RAGは、社内の独自知識の活用や業務の効率化に貢献し、さまざまな業務領域で活用がされています。どのようなシーンで活用できるかその事例を紹介します。
主な活用分野
| 活用分野 | RAGの効果 | GPUの貢献 |
|---|---|---|
| カスタマーサポート | FAQデータベースや最新のマニュアルと連携し、顧客の問い合わせに即時かつ的確な回答を提供 | GPUの並列処理により、リアルタイムの検索と応答速度を向上 |
| 研究・開発部門 | 技術文書や特許情報を検索し、最適な知見を迅速に取得 | ベクトル検索をGPUで高速化し、大量の文書から関連情報を即座に抽出 |
| ナレッジマネジメント | 社内の膨大な情報をリアルタイムで検索・要約し、従業員の業務効率を向上 | LLMの推論をGPUで加速し、適切な回答を即座に生成 |
技術文書検索AIへの活用例
課題:社内の技術文書が膨大で、必要な情報を探すのに時間がかかる。
解決策:RAGを活用し、検索キーワードに基づいて技術文書から関連情報を抽出し、要約を提供する。
GPUの効果:ベクトル検索をGPUで並列処理し、大規模データの検索速度を向上させる。
カスタマーサポートの活用例
課題:問い合わせ件数が多く、オペレーターの負担が大きい。
解決策:FAQデータベースと連携したRAGチャットボットを導入し、即時対応を実現する。
GPUの効果:LLMの推論をGPUで高速化し、大量の問い合わせにもリアルタイムで対応可能にする。
研究などのナレッジ活用例
課題:専門的な論文や研究資料が多く、必要な情報を見つけるのに時間がかかる。
解決策:RAGを活用し、キーワードに関連する論文や研究成果を検索・要約する。
GPUの効果:複雑な文書検索と要約処理をGPUで並列処理し、研究者の情報収集を効率化する。
以上のように、GPUの活用がRAGを最大限に活かす鍵となるでしょう。
まとめ
RAGと生成AIの組み合わせにより、リアルタイムで最新情報を反映した高精度なAI活用が可能になり、ビジネスの変革が加速しています。しかし、大規模なデータ検索や高度な文章生成をリアルタイムで実行するには、高性能なGPUによる並列処理と高速計算が不可欠です。
NTTPCは、ミッションクリティカルな商用AIサービスから、高いパフォーマンスが求められる研究開発基盤に至るまで、用途・予算に合わせた適切なAI基盤の設計・構築が可能です。GPUの導入を検討されている企業の方は、お気軽にお問い合わせください。