



性能検証
Infinibandの性能ベンチマーク
~GPU Direct™を実行してみる~
2018.08.29

サービスクリエーション本部
GPUアーキテクト
山崎 智行
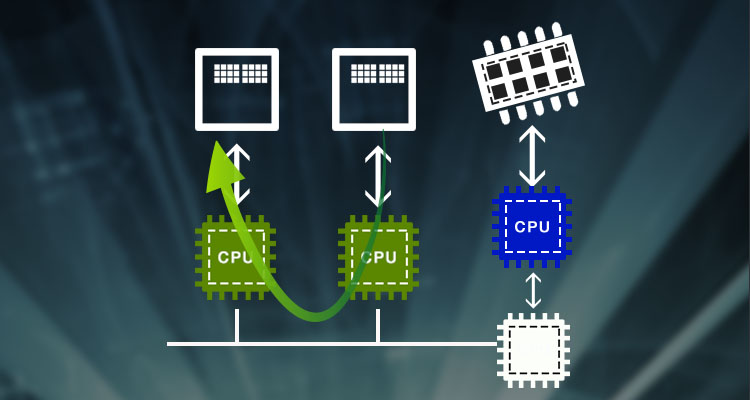
今回は、Infinibandの通信におけるベンチマーク方法を紹介します。
特に、Infiniband経由でGPU Direct™を実行した場合のパフォーマンスについて調査します!
内容がちょっとマニアックかも知れませんが、イメージだけでも掴んでもらえればと思います。
構成
サーバー
筐体 :Supermicro® SYS-4028GR-TRT2
GPU :NVIDIA® Tesla® V100 16GB
Infiniband HCA ( Host Channel Adapter ) :Mellanox MCX353A-FCBT ( Connect X-3 VPI )
OS / ソフトウェア
OS :Ubuntu 16.04.4 LTS
ベンチマークソフトウェア :OSU Micro-Benchmarks 5.4.3
MPI ( 並列コンピューティング実行環境 ) :OpenMPI 2.1.2
Infinibandドライバー :MLNX_OFED 4.3-1.0.1.0、nvidia-peer-memory 1.0-7
Infinibandスイッチ
:Mellanox MSX6012F
ネットワーク環境
:FDR ( 56Gbps )
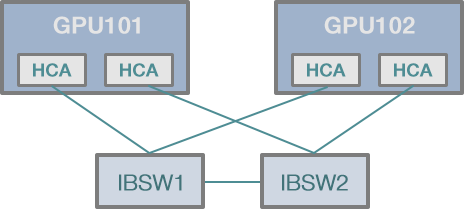
今回、Infinibandのベンチマークに使用するのは、オハイオ州立大学の「OSU Micro-Benchmarks 5.4.3 ( 以下OMB ) 」です。
並列処理環境を計測するベンチマークソフトウェアとしては結構古くからあり、Infiniband、Omni-Path、CUDA、OpenACCなどに対応しているので、この分野では定番と言えると思います。
このソフトウェアをインストール・実行するためにはMPIの環境も必要ですが、これらソフトウェアのインストール・設定方法については主題からそれますので今回は割愛します。
OMBにはいろいろなベンチマークツールが含まれますが、今回は帯域を計測するためにosu_bw、レイテンシを計測するために osu_latency を使用します。
ベンチマーク方法
「帯域幅」の計測
まず手始めにGPUを使用せず、CPU上のプロセス間でInfiniband間の帯域幅を計測してみます。
GPU101$ mpirun -np 2 -npernode 1 -mca btl_openib_if_include mlx4_1:1 -hostfile ./hosts.ip ./osu_bw # OSU MPI Bandwidth Test v5.4.3 # Size Bandwidth (MB/s) 1 1.83 2 3.68 4 7.39 8 14.60 16 30.10 32 44.84 64 116.13 128 229.98 256 416.97 512 905.53 1024 1404.07 2048 2880.97 4096 4871.18 8192 5269.23 16384 5491.58 32768 5752.56 65536 5866.21 131072 5905.44 262144 5799.75 524288 5890.98 1048576 5928.17 2097152 5920.43 4194304 5911.47
mpirunは、指定したプログラム ( ./osu_bw ) を複数サーバー上でそれぞれ同時に実行します。
mpirun の引数「 -np 2 」は全体のプロセス数、「-npernode 1」はサーバー1台あたりで実行されるプロセス数を表します。
今回はサーバーが2台なので全体のプロセス数を2とし、各サーバでosu_bwを1つずつ実行するようにしています。
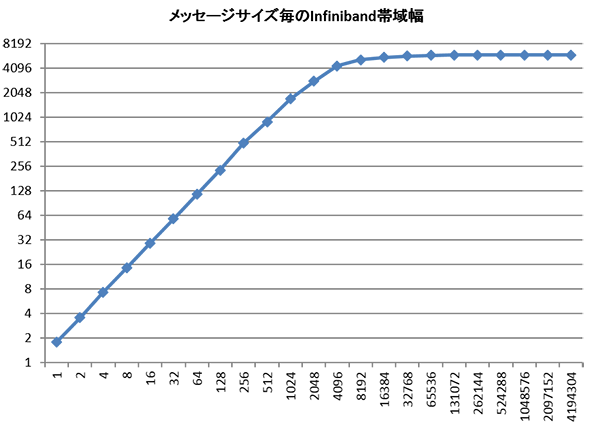
出力結果を見てみます。転送するメッセージサイズ ( 単位バイト ) が大きくなるにつれて帯域幅も良くなっていき、メッセージサイズが16Kバイトに達した時点で5,900Mバイト毎秒 ( ≒47Gbps ) に落ち着きます。
5回実行した平均値のグラフを示します。
縦軸が帯域幅、横軸がメッセージサイズです。メッセージサイズに比例して帯域幅もよくなっていき16,384バイトで上限に達することがわかります。
GPU Direct™を使用した際の帯域幅を測定していきますが、その前にサーバーの内部構成について説明します。
サーバ内部構成
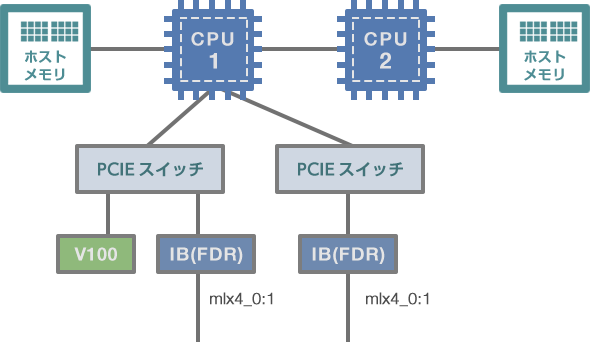
サーバー内にInfinibandアダプターを2つ用意し、一方はGPUカードと同じPCIeスイッチに接続 ( PIX ) 、他方はCPUをまたいだPCIeスイッチに接続 ( PHB ) しています。GPU Direct™の転送性能が2パターンの構成でどれだけ差が出るかも確認したいと思います。
なお、サーバーの内部構成は「nvidia-smi -m」を実行することで確認できます。計測のための実行コマンドは次の通りです。
# CPUプロセス間の計測 mpirun -np 2 -npernode 1 -mca btl_openib_if_include mlx4_0:1 -hostfile ./hosts.ip ./osu_bw # GPU間の計測(GPUDirectなし) mpirun -np 2 -npernode 1 -mca btl_openib_if_include mlx4_0:1 -hostfile ./hosts.ip ./osu_bw D D # GPUDirect(CPU跨ぎ、PHB) mpirun -np 2 -npernode 1 -mca btl_openib_if_include mlx4_1:1 -mca btl_openib_want_cuda_gdr 1 -hostfile ./hosts.ip ./osu_bw D D # GPUDirect(GPU-IB間直結、PIX) mpirun -np 2 -npernode 1 -mca btl_openib_if_include mlx4_0:1 -mca btl_openib_want_cuda_gdr 1 -hostfile ./hosts.ip ./osu_bw D D
osu_bwの引数として「D D」を指定することで、CUDAのGPUデバイスのメモリー間転送を計測できます。
mpirunの「-mca btl_openib_if_include」の引数でInfinibandアダプターを選択します。MPIを使った並列処理環境では、サーバーのハードウェア構成が一致していないと期待通りの動きになってくれないので注意が必要です。
また「-mca btl_openib_want_cuda_gdr 1」を指定しないとGPU Direct™は動きません ( CUDAのメモリー転送はCPUを介して行われる ) 。
4つのパターンで計測した結果を示します。それぞれ5回ずつ実行した平均値をとっています。
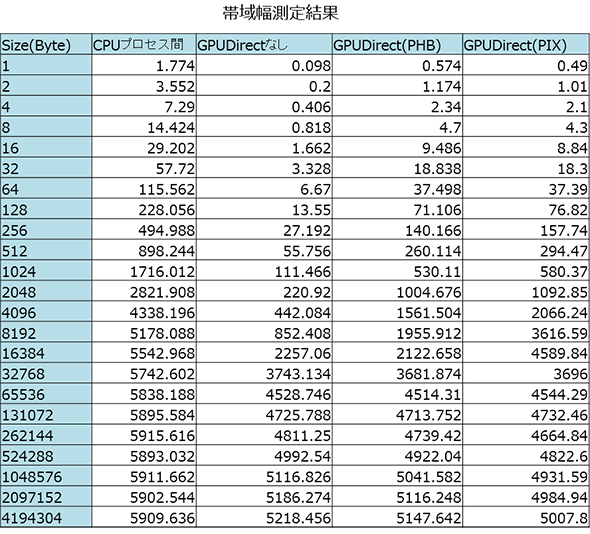
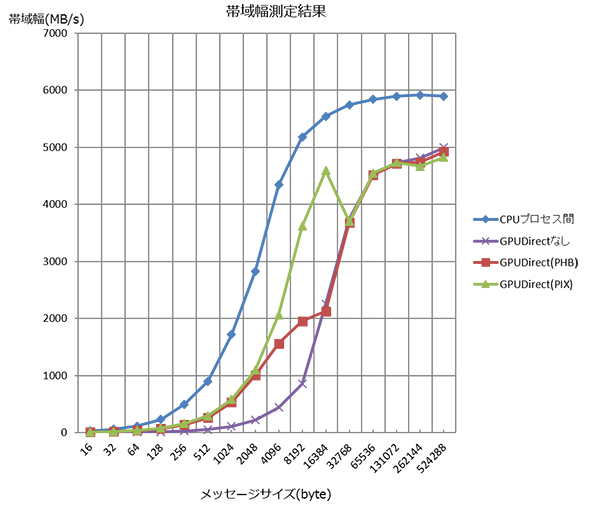
GPU Direct™はCPUプロセス間に及ばないとはいえ、メッセージサイズが8192バイトまではGPU Direct™なしの場合に比べて倍以上の帯域が出ています。
PHBでは8,192~16,384バイトあたりで上限を迎え、それ以降の帯域幅はGPU Direct™なしとほぼ同値です。PIXでは16384バイトまではうまく伸びていって、32,768バイトではGPU Direct™なしとほぼ同値になります。
このことから、16,384~32,768バイト間で“変曲点”があると思われます。 メッセージサイズを適切に選ぶことは、GPU Direct™がInfinibandを効率よく使う際に重要な要素となると言えそうです。
「レイテンシ」の計測
次にレイテンシの比較を行います。mpirunに渡すコマンド名をosu_bwからosu_latencyに変更するだけです。
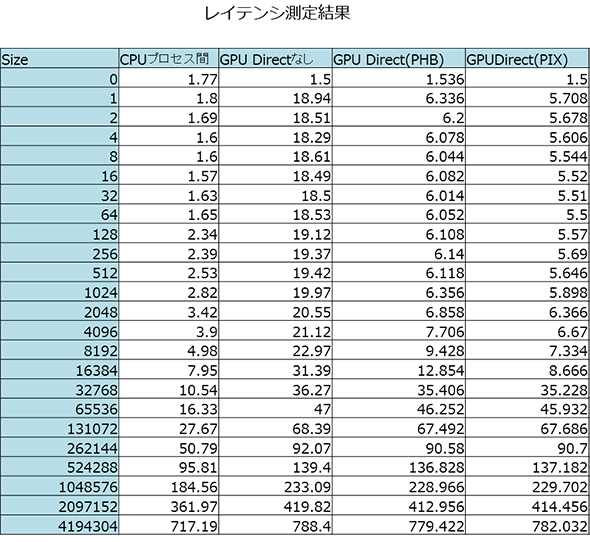
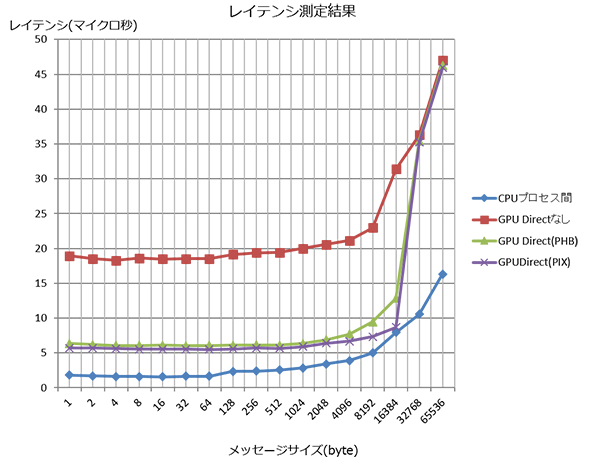
Infinibandを導入するモチベーションの一つに“低遅延”があげられますので、10マイクロ秒オーバーを厳しいとすると、実効的なメッセージサイズはCPU間通信では16,384バイトまで、GPU Direct™だと8,192バイトまでとなります。
GPU Direct™を使わない場合は、メッセージサイズが小さくても20マイクロ秒近くかかってしまうことがわかりました。また、PHBとPIXの比較ではPIXのほうが若干低遅延です。
2,048バイト以下では1マイクロ秒ほど、4,096~16,384バイト区間では2~3マイクロ秒に差が広がっています。
まとめ
今回はOMBを使い、Infiniband通信 ( FDR ) の「帯域幅」と「レイテンシ」を計測しました。
GPU Direct™を利用した場合、GPUデバイスメモリー間の通信では、帯域・レイテンシともにメッセージサイズが4,096バイトから8,192バイトの間で大きな効果がでることがわかりました。
一方、16,384~32,768バイト間には“変曲点”が存在するため、メッセージサイズを適切に選ぶことが重要です。