



技術解説
AI/ディープラーニングに求められるGPU間のP2Pダイレクト転送とH/W要件
2020.02.13
Super Micro Computer, Inc.
Mitsuru Yabe

GPGPU、HPC、AIディープラーニングのトレーニングにおいては、複数のGPUデバイスメモリ間でデータを相互転送しながら演算を行うと、より効果的な性能結果を得られることが知られています。この場合、GPU間のデータ転送は、CPUやメインメモリを介さない「P2Pダイレクト転送」能力が必要です。
この要件に向けた解決策として、NVIDIA🄬は独自に広帯域(300GB/s)転送用インターコネクトとしてNVLINK™ や NVSwitch™ を開発、提供しています。
Supermicroでは1U 4GPU、4U 8GPU、10U 16GPUのNVLINK™/NVSwitch™対応製品をラインナップしおり、⽤途に応じて最強のGPUシステムをご提供できます。
GPGPUやディープラーニングのアプリケーションは、まずCPUとメインメモリ上で初期化、データの読み込みと準備が行われ、その後、アプリケーションと各APIの手順に従ってPCI-E x16 (現行ではGen.3 16GB/s) を介してGPUのデバイスメモリに演算命令とデータが転送され、GPGPUでの演算が行われます。ここで、トータル性能としてのスループット向上のためには、GPUの性能だけでなく次の2点も考慮する必要があります。
- CPUとメインメモリの性能、処理能力
- CPU/メインメモリからGPUまでの帯域
そして、GPGPUやディープラーニングにおけるトレーニングの演算においては、複数のGPU間でデータを相互転送しながらトレーニングを行います。各GPUが持つ専用のメモリ容量には上限があるため、それを補うことにもなります。言い換えれば、GPGPUが直接使えるメモリ空間が大きければトレーニングの演算により効果的であるということです(デバイスの物理メモリ増強については、各ベンダのアクセラレータ性能向上に期待しましょう!)。
この際に複数のGPU間で、CPUやメインメモリを介さないGPU間のP2Pダイレクト転送能力が必要になります。NVLINK™やNVSwitch™搭載機種であれば良好なP2Pを実現できますが、ここで問題となるのが、「従来のPCI-EカードタイプのGPUを使用したP2P機能の実現」です。
GPU間のデータ転送を行う上で考慮する必要があるのがPCI-Eの接続トポロジーです。これには、
- CPUをPCI-Eのルート(ホスト)とする
- PCI-Eスイッチをルートとする
の2つの選択肢があります。前提として、インテル🄬 Xeon® プロセッサーの場合は、プロセッサー間をつなぐインターコネクトのQPIやUPIを経由すると、レイテンシーと帯域がGPU間P2P転送の要求性能を満たさないため、QPIやUPIはGPU間P2Pでは使用しません。
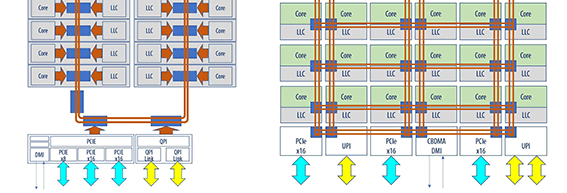
CPUをルートとする場合では、プロセッサーのI/O周りのRoot Complexに対して、アーキテクチャの世代による違いを理解し、異なる解決策を取る必要があります。次の図は、Broadwell世代と、現行のPurley世代のアーキテクチャの違いです。
(インテル🄬 Xeon🄬 プロセッサー E5 ファミリーと、インテル🄬 Xeon🄬 スケーラブル・プロセッサーのアーキテクチャ比較)
お気づきでしょうか?インテル® Xeon® プロセッサーのBroadwell世代 E5-26xx (SupermicroではX10世代)から、最新のPurley世代のスケーラブル・プロセッサー(SupermicroではX11世代)では、PCI-E周りのアーキテクチャが異なります。そのため、Broadwellでは可能であったCPUをルート(ホスト)として経由するP2Pデータ転送は、最新のスケーラブル・プロセッサーにおいては、レイテンシーと転送スループットが同じような性能を実現できない可能性があります。すなわち、CPUのPCI-Eの機能だけに頼らない解決策が必要になります。
SupermicroではPCI-E x16 GPUカードに最適化したシステムを豊富に用意しております。代表的なモデルは以下の通りです。
■X10(Broadwell)世代:
- ① SYS-1028GR-TRT: 4 GPU cards, 1U
- ② SYS-2028GR-TRT: 6 GPU cards, 2U
- ③ SYS-4028GR-TR/TRT: 8 GPU cards, 4U
- ④ SYS-4028GR-TRT2: 10 GPU cards, 4U
■X11(Purley)世代:
- ① SYS-1029GP-TRT: 4 DW GPU/Accelerator cards, 1U
- ② SYS-2029GP-TRT: 6 DW GPU/Accelerator cards, 2U
- ③ SYS-4029GP-TR/TRT: 8 DW GPU/Accelerator cards, 4U
- ④ SYS-4029GP-TRT2: 10 DW GPU/Accelerator cards, 4U
- ⑤ SYS-4029GP-TRT3: 9 DW GPU/Accelerator cards, 4U
- ⑥ SYS-6049GP-TRT: 20 Single Wide GPU/Accelerator cards, 4U
上記以外にも、ワークステーション型モデルなども用意しています。詳しくはこちらをご覧ください。
X11(Purley)世代では⑤と⑥の製品が新たに追加されました。なぜこのような多種類の製品を用意しているのでしょうか? それは、次のようなPCI-Eのトポロジーをアプリケーションの用途に合わせて柔軟に選択し、最良の性能を実現するためです。すべてのGPUカードがプロセッサーを介さずにPCI-Eスイッチを経由可能なSYS-4029GP-TRT3は、前述のPurley世代のプロセッサーにおけるGPU間P2P性能を最適化するために、新たに追加された製品で、これは業界でも唯一です。
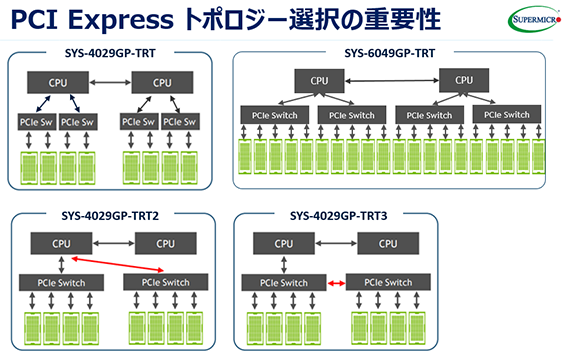
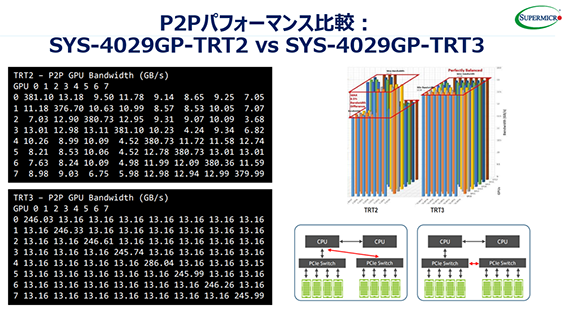
各トポロジーの用途は以下の通りです。
- CPU-GPU間をバランスの取れた帯域で接続する -TRT: HPC、3次元グラフィックス
- P2P性能に特化した真のシングルルート -TRT3:ディープラーニング、トレーニング
- 上記の中間的、汎用的な -TRT2:HPC、ディープラーニング、トレーニング、推論
- Single wide PCI-Eに特化 SYS-6049GP:推論、FPGA(Lookup & In-line)
さらに、GPUサーバーのスタンダードモデルであるSYS-4028GRおよびSYS-4029GPシリーズでは、NVIDIA🄬 Tesla🄬のようなデータセンターGPUに対応しているほか、
- A) ディスプレイ出力を持った3次元グラフィックス用Quadro🄬 GPUカードに対応
- B) コンシューマ向けGeForce GPUカードに対応
- C) 2枚のGPU間をつなぐNVIDIA🄬 NVLINK™ブリッジ の利用が可能
- D) VR/AR/Simulatorに必要なGenLock機能のNVIDIA Quadro Sync IIを搭載可能
- E) NVIDIA🄬 Tesla🄬とNVIDIA🄬 Quadro🄬を同時に搭載(ハイブリッド搭載)でき、GPGPU演算させた結果を直接Quadro🄬 GPUで可視化させることが可能
- F) AMD GPUを搭載可能
- G) インテル🄬 FPGAカードを搭載可能
- H) InfiniBand広帯域ネットワークカードを搭載可能
と多岐にわたる機能を実現します。
もう一点、GPUアクセラレータの搭載密度が上がると重要になる要件が、システム内の冷却機能です。GPUはより効率的に冷やすことで、最良の性能が発揮できます。言い換えると、高温になるとGPU側で処理能力を落とす(抑える)機能が働いてしまいます。そこでSupermicroのGPU製品は、フル稼働しても計算パフォーマンスを維持できるよう、効率的な冷却を考慮したエアフローを設計しており、常に高いGPU能力を引き出すことが可能です。

このように、各用途のアプリケーションに合わせた、多岐にわたる機能と最適化を施したシステムを提供するのは他のメジャーメーカーでは難しく、AIビジネスにおける個社別の機微な要件・ニーズに応えられるサーバー設計とラインナップがSupermicroのもっとも大きな強みとなっています。