



性能検証
NVIDIA DGX™ H100徹底検証!ベンチマーク&消費電力
2024.04.11

GPUエンジニア
石渡 巧

はじめに
前モデルのNVIDIA DGX™ A100に続き、NVIDIA社からリリースされたGPUアプライアンス「NVIDIA DGX™ H100」を、NTTPCの検証設備として導入しました。
本マシンは、前世代のA100(Ampereアーキテクチャ)から更に性能が向上した、2024年2月時点で最新の「HopperアーキテクチャGPU」を搭載したアプライアンスサーバです。
搭載されている「NVIDIA H100 Tensor Core GPU」は、SM 自体の高速化、SM 数の増加、クロック周波数の向上等により、A100 との比較で最大 6 倍高速化されています。
※Streaming Multiprocessor (SM)
また、より高速なGPU間通信を実現するため、第4世代NVLink🄬に対応しており、マルチGPUI/Oの総帯域幅は900GB/秒を実現。これは前世代のNVLink🄬の1.5 倍、PCIe Gen5の約7倍です。
加えて、ネットワークカードとしてGPU専用のNVIDIA ConnectX®-7(旧Mellanox Infiniband)NDRを搭載しているため、よりGPUクラスタに適した構成になっています。ただし、大幅なパフォーマンス向上の代償として消費電力も「最大10.2kW」と、過去モデルから大きく上がってしまっており、最大のパフォーマンスを発揮するために運用環境を準備する必要のある製品となっています。
今回は、この「NVIDIA DGX™ H100」について、実機を活用した忖度なしのベンチマークテストを行い、実際の電力消費もチェックしたいと思います!
マシン導入を検討している方の参考になれば幸いです。
検証環境
今回もNTTPCデータセンターにラッキングして検証を行いますが、最大消費電力(10.2kW)だと、当社データセンターの最大規格である8kVAラックでも足りないため、実際にどれだけ電力を消費するかも含めてテストしました。

サーバラックにラッキングした状態

背面
ユニット数は8U。背面のGPU用InfinibandポートはOSFP x4になっています。
C19-20の電源ケーブルが付属しています。
PSUは6本(4+2冗長)備えています。フルパワーで稼働させた場合は、PSUが3本故障するとシステムダウンします。
なお、検証時の動作環境・バージョンは初期セットアップの状態のままとします。
【動作環境・バージョン】
| OS | DGX OS 6.0.11 (Ubuntu22.04.2LTS) |
|---|---|
| Driver | 525.105.17 |
| NVIDIA Container Toolkit | 1.13.1 |
| Docker | 23.0.4 |
検証項目
本記事では、下記3点を検証した結果を公開します。
① NVLink帯域幅測定結果
② Tensorflowベンチマークソフト実行結果
※Tensorコアのパフォーマンス向上により、A100の2倍近い性能が期待できます
③ DGX H100をフルパワーで回した場合の温度上昇・消費電力
1. NVLink帯域幅測定
まずはNVLinkの帯域幅を確認してみます。
NGCのCUDAコンテナを使用してnvbandwidth testを実施します。
下記はdockerコンテナイメージの起動コマンドと起動後のメッセージです。
コンテナを起動後、NVIDIAのGithubからnvbandwidthをダウンロードして実行します。
下記が実行結果です。
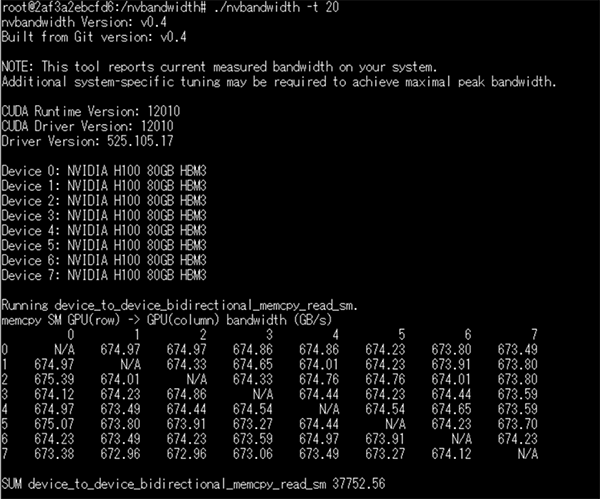
GPU間通信のNVLink帯域幅は約670GB/s出ていることを確認できました。
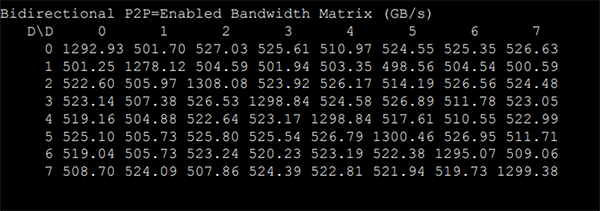
DGX A100のP2P Bandwidth Testでは下記のような結果なので、520GB/s⇒約670GB/sへ、大幅に向上していることがわかりました。
2. ベンチマークソフト実行結果
NGCコンテナを用いたTensorflowのCNNプログラムでベンチマークを取り、DGX A100と比較してみます。
※CNNについては下記記事をご覧ください。
CNNによる画像認識|GPUならNTTPC|NVIDIAエリートパートナー
こちらもNGCコンテナイメージを使ってテストしますが、DGX A100とH100でアーキテクチャが違うので、対応しているコンテナバージョンが異なります。
まずはDGX A100からテストします使用する環境は下記の通りです。
Tensorflowコンテナイメージ
nvcr.io/nvidia/tensorflow:20.08-tf1-py3
使用するCNNプログラム
workspace/nvidia-examples/resnet50v1.5/main.py
mpiを使って8枚のGPUに対して並列処理を行います。
mpiexec –allow-run-as-root –bind-to socket –np 8
実行に必要なバッチサイズや計算回数といったパラメータオプションを付与し、CNNプログラムを実行します。
--mode=training_benchmark --batch_size 512 --use_tf_amp --use_xla --num_iter 1000
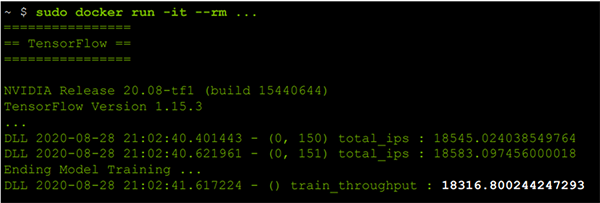
上記がDGX A100のベンチマーク結果です。大体18000/ipsという結果になりました。 コンテナイメージの更新のため環境が新しくなり、性能向上したおかげで、nvidia/tensorflow:21.06版にて、18000~20000/ips程度まで性能が引き上げられています。
次にDGX H100のベンチマークを取得します。
こちらはアーキテクチャのcompute capabilityも上がっているので、DGX A100で安定動作しているコンテナイメージではサポート対象外となってしまいます。 そのため、H100に対応したコンテナイメージを使いますが、新しいコンテナイメージではA100で使用していたCNNのプログラムが一新されたため、別のプログラムで同じパラメータを使ってベンチマークを取っていきたいと思います。
Tensorflowコンテナイメージ
nvcr.io/nvidia/tensorflow:23.02-tf1-py3
使用するCNNプログラム
workspace/nvidia-examples/cnn/resnet.py
mpiを使って8枚のGPUに対して並列処理を行います。
mpiexec –allow-run-as-root –bind-to socket –np 8
CNNプログラムには以下のオプションコマンドを付与して実行します。
--layers 50 --batch_size 512 --use_xla --num_iter 1000
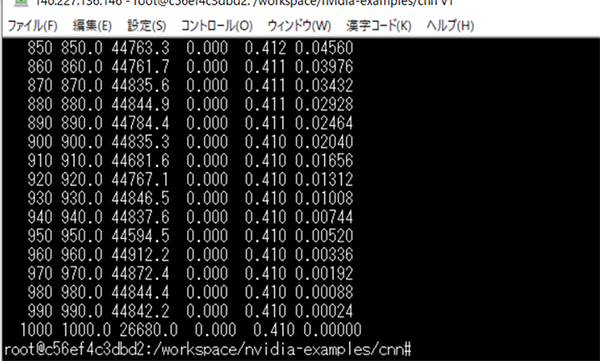
44500/ips平均という結果になりました。
CNNのResnet50においては約2.5倍の性能向上が見られます。
なお、今回は1台のDGX H100でのテストなので検証対象外としましたが、DGX H100のインターコネクトはInfiniband NDR400に対応しているため、DGX SuperPODなどの大規模クラスタ構成でノード間並列を行った場合でも十分な性能が発揮できる製品となっています。こちらは別途検証結果を公表したいと思います。
3. 温度、電力測定結果
DGX H100を搭載しているラック周辺に温度計を設置し、温度と電力測定を実施しました。結果は下記の通り、消費電力は7.3kW、温度は11.7度上昇する結果となりました。
今回は1台でのテストでしたが、複数台設置した場合はホットアイル側の熱だまりが懸念されます。ホットアイル側のキャッピングを実施しているデータセンターに設置することで、より高い冷却効率を期待できます。
●実施環境
場所:NTTPC 勝どきデータセンター
キャッピング:コールドアイル
設置機器:NVIDIA DGX™ H100 (最大消費電力 10.2kW)
電力環境:200V 30A(L6-30) x 3系統
ベンチマークツール: nbody (CUDA Toolkit)

●検証内容
DGX H100をフルパワーで稼働させた場合の
- 消費電力
- ラック前面の温度 / 湿度
- ラック背面の温度 / 湿度
を測定。
●検証結果
① 消費電力
- 測定値:7.3kW
- 最大消費電力(DGX H100) 10.2kWに対して7割
- GPU利用率は100%だったが、CPU、メモリ、Disk I/Oなどの負荷をフルでかけられていないため、その差分と思われる
② 温度・湿度
- 温度:11.7度上昇
- 湿度:16.4%減少
※1台のみの検証のため、機器を設置した背面の上段への影響はほぼない


感想
私はGPUエンジニアとして、DGX Systemsの初期モデルである「DGX-1」から、時代の変化と共にアーキテクチャの進化を見てきました。
DGX A100も、発売当初は「革新的な進化を遂げた製品だ!」とわくわくしていましたが、DGX H100はさらにGPUクラスタや並列処理に特化した構成となっており性能が向上した反面、1台あたりの消費電力も大きくなっているので、日本国内では運用できる環境が限られています。超高電力に対応したデータセンターでないと最大のパフォーマンスを発揮させることは難しいでしょう。
今後リリースが期待される次世代のDGX Systemsも、性能と電力設計がどうなるか注目どころです。更なる技術発展と共に、GPUを通じた世界のAIの発展に繋がればよいと思います。
なお、NTTPCコミュニケーションズでは、NVIDIA社によるサーティフィケイトの取れた、DGX Systemsの安定稼働に適したデータセンターを紹介可能です。導入をお考えの方はぜひお問合せください。