



技術解説
CNNによる画像認識
2017.06.30

サービスクリエーション本部
アプリケーションエンジニア
石井 誉仁

サービスクリエーション本部
ソフトウェアエンジニア
渡里 凌

昨今ではニュースや新聞などで人工知能やAIという言葉を多く目にするようになりました。
人工知能の研究は以前から行われておりましたが,近年の人工知能・AIブームの火付け役には DeepLearning (深層学習)という技術の急速な進歩が背景にあると言えます。
その中でも,一般画像認識における標準的な手法とまで考えられるようになった Convolutional Neural Network (以下,CNN) について NTTPCコミュニケーションズ(以下,NTTPC) が調査・実装してみたことや今後の取り組みについて以下で解説していきたいと思います。
DeepLearningについて
まずはじめにですが,「DeepLearing とは何?」という方のために少し解説をしていきたいと思います。
昨今のAIブームの火付け役となった DeepLearning ですが,DeepLearing は決して新しい技術ではありません。以前からAIの研究で扱われていたニューラルネットワーク(人の脳の神経回路を模倣した機械学習の手法)を多層に組み合わせてたものであり,膨大な計算量を必要とするために実用的ではないアプローチとして認識されているものでした。しかし,近年の機械における処理性能向上やクラウド環境の普及などがこのアプローチを大きな成果へと昇華させる結果を導きました。
以上から,DepLearning の基本的な理論・考え方と言うのはニューラルネットワークの考え方とほとんど同じです。そこで,簡単のためにニューラルネットワークを題材にして説明したいと思います。
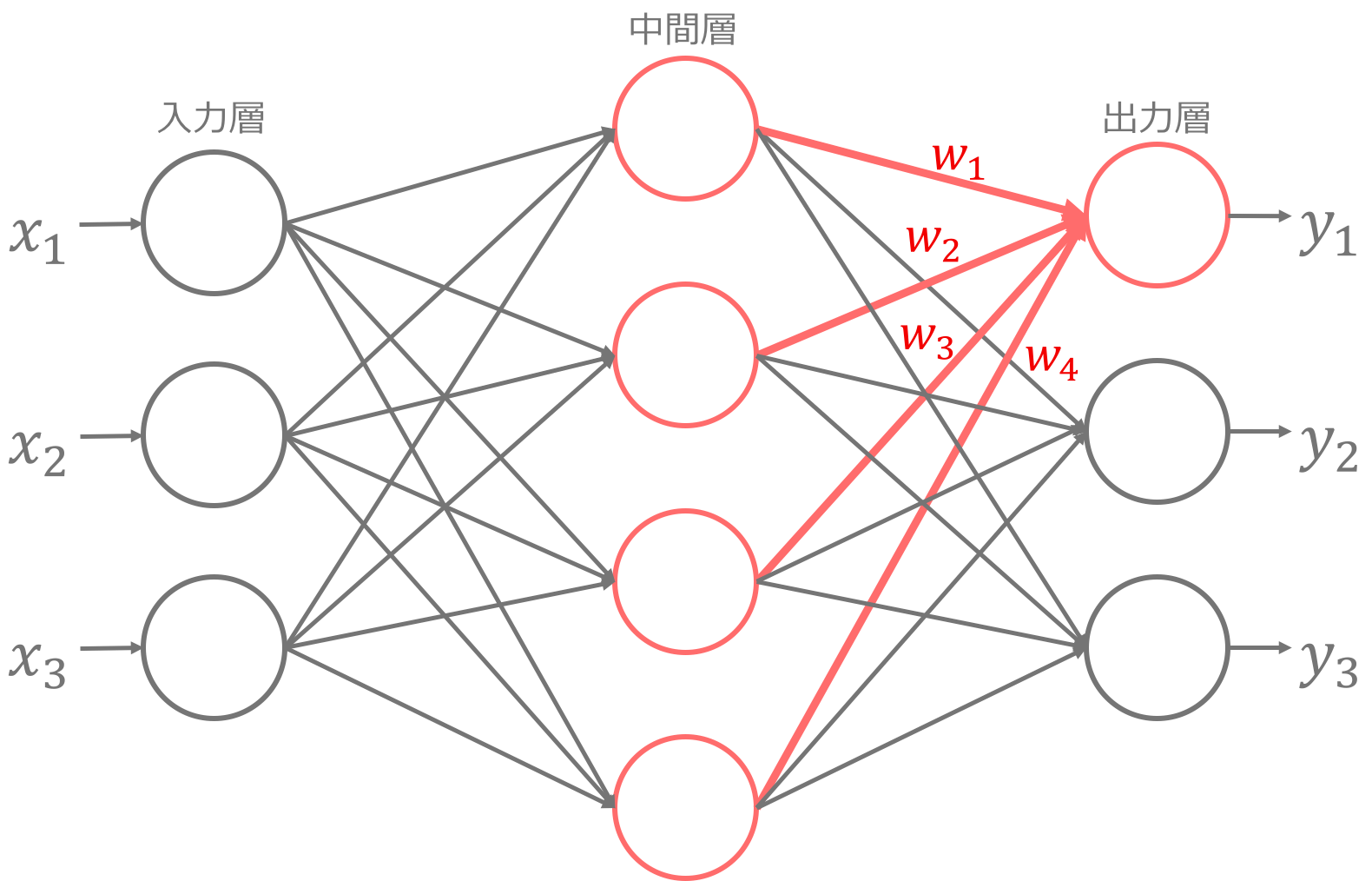
ニューラルネットワークは上記のようなネットワークを形成しており,入力層,中間層,出力層といった構成要素から成ります。上記図を見ていただくと,入力となる x_1, x_2, x_3 を入力して,出力であるy_1, y_2, y_3 を得ることで,ある入力から新しい結果を得ることになります(それぞれの丸の部分をノードと呼ぶ)。さらに,中間層から出力層の部分を見てもらうと分かるように,途中の処理については重みwをそれぞれの中間層に掛け合わせてy_1を算出していることが分かると思います。このように,ニューラルネットワークとはある入力に対して重みをかけた結果から新しい出力結果を獲得するということをネットワークの構成に従って行っています。そして,ニューラルネットワークの学習とはネットワーク中のwの値を既知のデータからから求めることで,人工知能的な予測ができるというのは未知のデータが来た時にも学習によって求めたwによる学習モデルから結果を予測することができるということになります。ちなみに DeepLearning は先ほどの上記に述べたようにこの中間層を多層に組み合わせたもので,最近の研究などで40層以上のネットワークを構成して成果を出しているものもあります。しかし,多層にすれば良い結果が得られるというわけではないので計算にかかる時間的制約や精度などを確認しながら高精度を実現する最適なネットワーク構成を模索していきます。(実際にはネットワーク構成だけではなく,wを求める際の最適化手法や用意するデータセットなど複数の条件を変えて調整することになります。)
また,最後にニューラルネットワークについての特徴を述べたいと思います。ニューラルネットワークの最も大きな特徴は,特徴量の選択までを学習で行うことです。厳密には選択ではなく重みの優劣で決まるのですが,これは他の機械学習の手法と異なる最も大きな特徴です。通常の機械学習の手法ですとどの特徴が結果に影響しているのかをある程度考えてから必要な特徴量を選択して学習データセットを作成して,機械学習のモデルを生成するということになります。ニューラルネットワークではその部分を機械に自動で行ってもらうため,人が見て理解しづらいデータなどには効果を発揮することでしょう。一方で,どの特徴が効いていてなぜそうなったのかという因果関係が見えづらいという点はニューラルネットワークのデメリットでもあると言えます。
画像認識への適応
ここまでで DeepLearning がどのようなものかをなんとなく理解されたと思います。
ここからは NTTPC で試してみた画像認識への適応について説明していきたいと思います。
DeepLearning を画像認識の分野で適用しようとする際に,非常に有力な手法として CNN という手法があります。
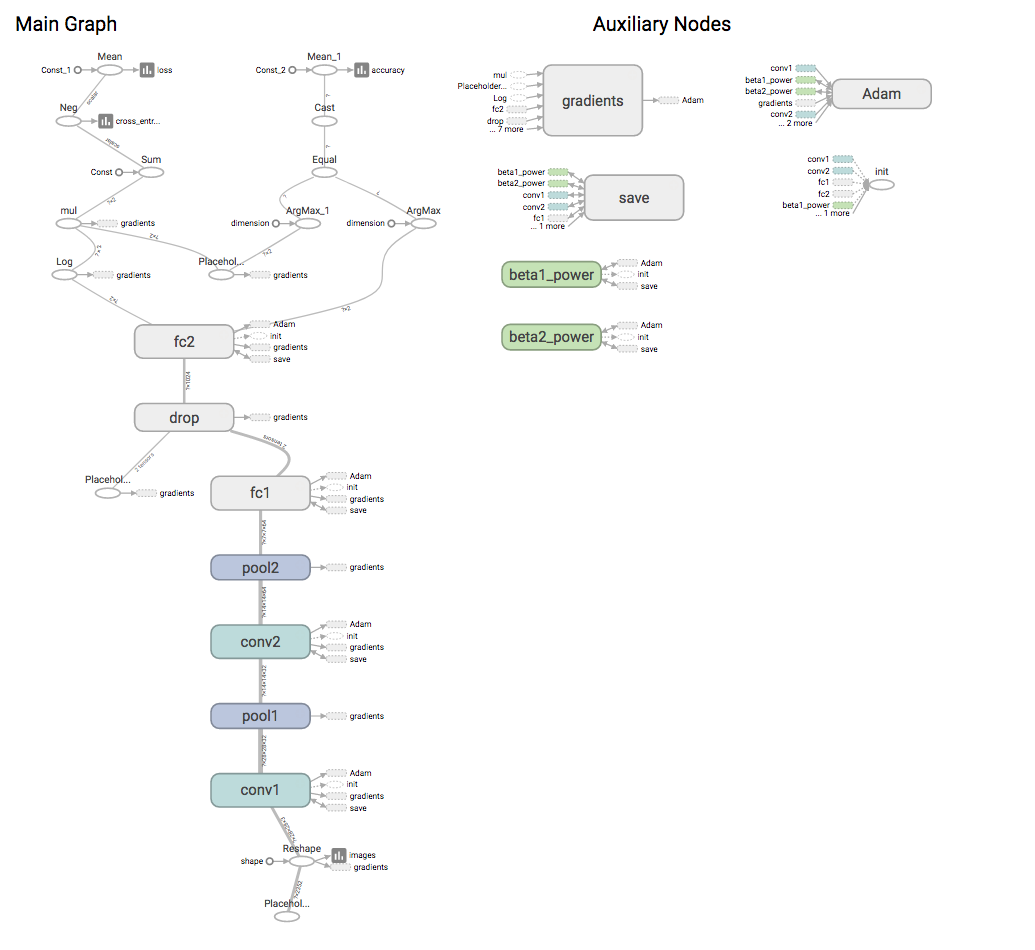
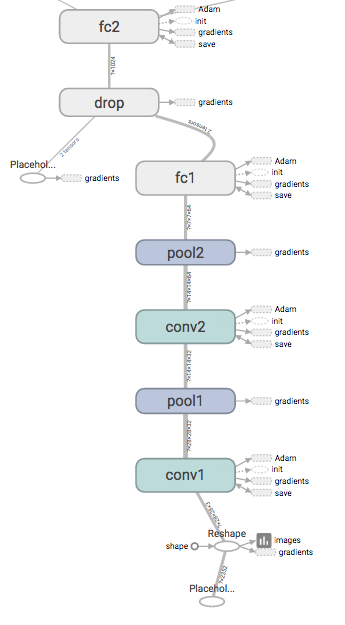
CNN は先ほどのニューラルネットの中間層の部分に畳み込み層(以下,Convolution層)とプーリング層(以下,Pooling層)を組み込んで構成されるニューラルネットワークを指します。下図は簡易的な5層のCNNを示しており,入力層からCovolution層,Pooling層を繰り返して,出力層の手前のFullyConnected層で予測結果に分類する為の識別を実施して出力をしている。
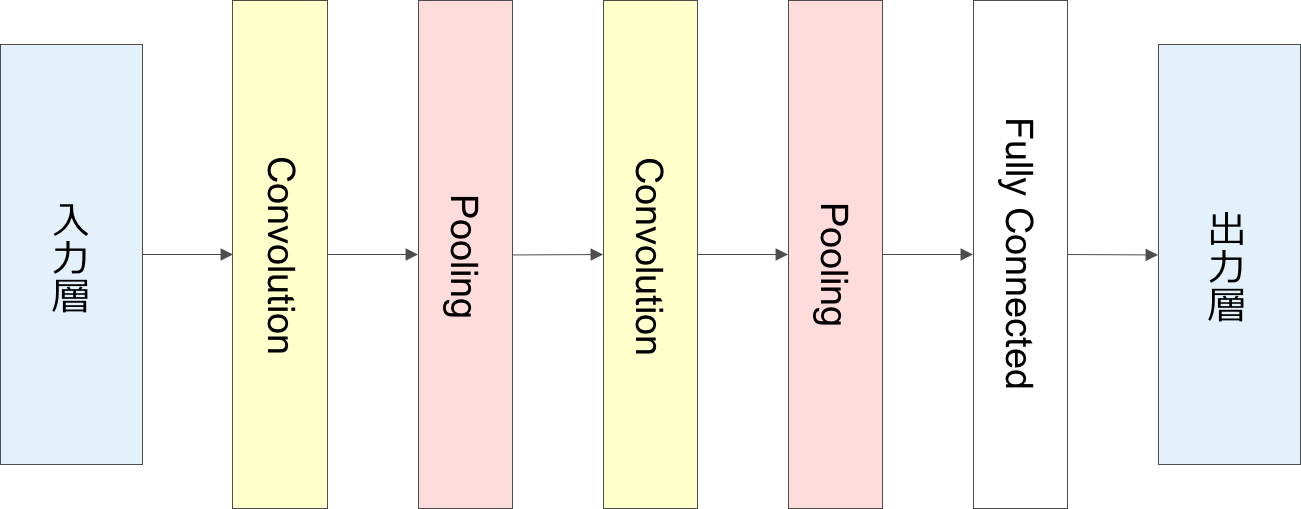
Convolution層は画像内にある小領域を設けて特徴量のまとまりを作るフィルタのような処理を実施します。これを畳み込みという処理と呼びます。その後,Pooling層で小領域に対してそれぞれの特徴量を圧縮することで,画像の移動や変形に対して影響を受けにくく,計算量を下げるなどの効果を発揮することになります。
CNN も畳み込みで使用するフィルタのパラメータ選択や使用する活性化関数を何にするのかで精度が大きく変化してしまうのでパラメータを指定・選択していく過程が人による感覚に依存してしまう点が難しい点であると言えます。
ここで説明した CNN はDeepLearningの手法の中の一部であり,この他にも時系列データに適応するRecurrent Neural Networkや強化学習へ応用したDeep Q Learningなどがあるので,目的に合わせて手法を選択していくことが求められます。
環境準備
それでは今まで説明してきた CNN の理論を実装する段階に移っていきます。複雑な数式や理論をプログラムするのかと思うとハードルが一見高いように見られますが,世の中には DeepLearning の仕組みを簡単に実装するためのライブラリ/フレームワークが多数オープンソースとして公開されており,自身の環境や用途に応じて利用することできます。今回は世の中で広く一般的に使われているGoogle 社が2015年に公開したニューラルネットのフレームワークである「 Tensorflow 」を扱っていこうと思います。
他のフレームワークでも同様の機能を備えているのですが,今回は Tensorflow の独自機能である TensorBorad の使用感について確認したく,上記フレームワークを採用いたしました。TensorBoard とは Google 社が開発したニューラルネットの学習過程を可視化してデバックやパラメータの最適化を容易にする為のものであり,これを用いてモデルの評価やパラメータなどを調整していきます。
そして今回は以下のようなスペックで CNN による画像認識を行う環境を用意しました。
・ハードウェアスペック
* OS: Ubuntu16.04LTS 64bit
* CPU: Intel Core i7
* HDD: 1TB
* GPU(1台): NVIDIA Geforce GTX 1080
・ソフトウェアスペック
* Python: 2系
* Tensorflow: 0.12.0
* Cuda: 8.0
* cuDNN: 5.1
* Dokcer: 5.1
* OpenCV: 2系
DeepLearning の学習には非常に膨大な計算量が発生するため,GPU を用いて高速な処理を実現します。GPU には NVIDIA 社が提供している Geforce GTX 1080 を活用するのですが,ここは自身が扱うデータ量や求める処理性能などに応じて適宜ハードウェアを選んでください。また,ソフトウェアについてもオペレーティングシステムやNVIDIA製品に対応したドライバをダウンロードして環境を構築してください。
学習からの認識モデルの生成
ここからは実際に画像認識を実施する話をしていきたいと思います。
とは言っても何を識別するのかというところから決定する必要があるので,今回はテニスをしているスポーツの画像から人物を検出・識別することを目的に調査・実装することを行いました。
準備したデータセットは以下の通りです。
・訓練データ
* テニスプレイヤーの画像:10000枚
* テニスプレイヤー以外の画像:10000枚
・テストデータ
* テニスプレイヤーの画像:3000枚
* テニスプレイヤー以外の画像:3000枚
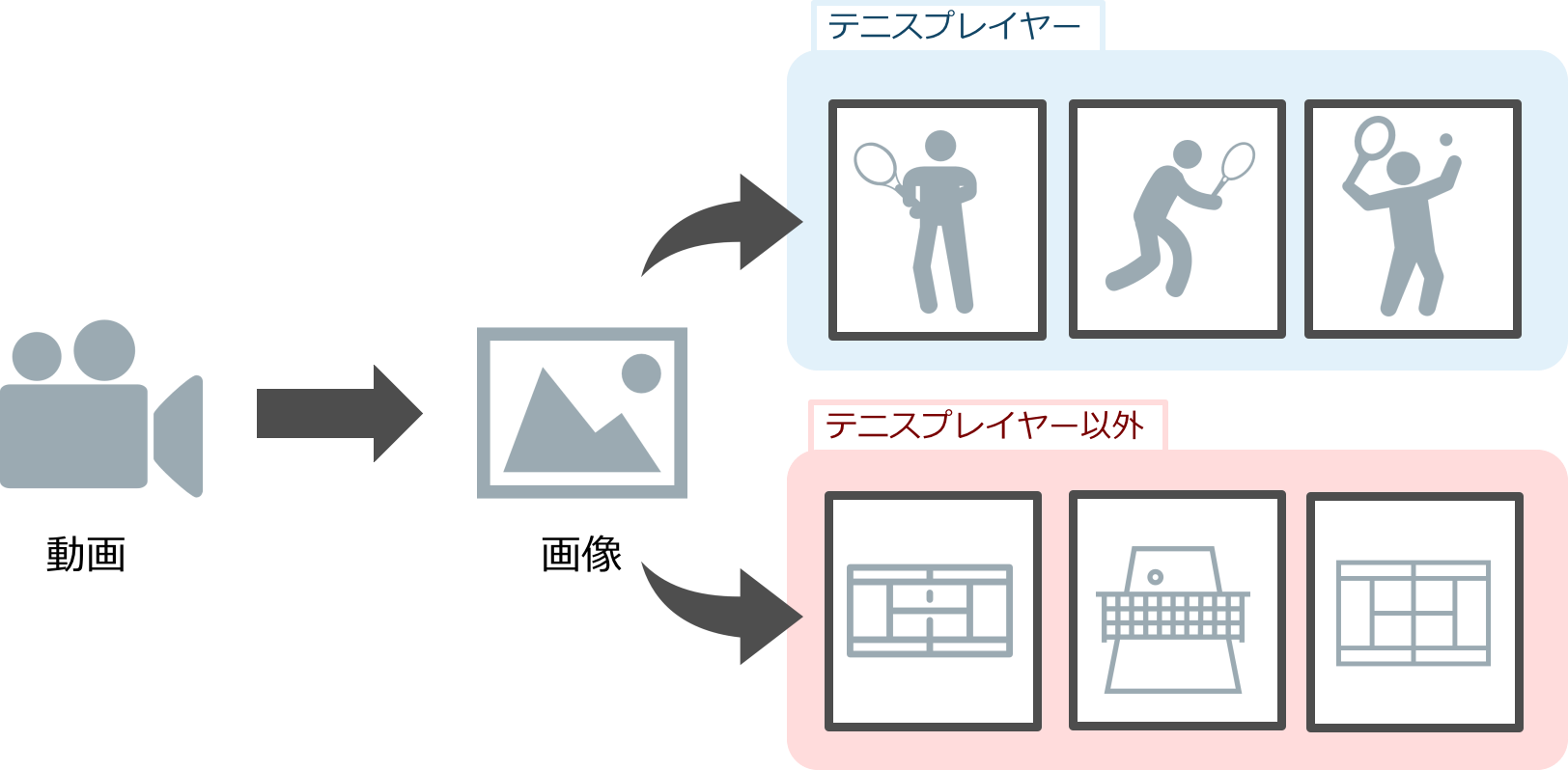
また,画像のサイズは250x250で用意しました。画像の画素数1つ1つが入力層の1入力に相当するので画像のサイズが大きくなるということはその分入力次元が大きくなり計算量が増加することになります。そのため,計算量を考慮して必要な処理を実装するために画像のサイズを250x250で用意して,さらに実行時に28x28にリサイズして学習を行いました。
前処理
データセットの準備
画像データセットを用意するために,動画から1フレームを抜き出して人の部分を抽出するという作業を行います。1フレームの画像中から同じサイズの人物部分を抽出する繰り返しの作業を手作業で実施するということは非常に膨大な時間と労力がかかります。そこで,画像からマウスでクリックした部分を中心に指定したサイズで画像を切り出すツールを作成しました。これでも人が画像から特定の部分を見つけてクリックし続ける必要があるためコストの軽減には繋がったもののデータセットの作成には時間がかかります。
認識ラベルの付与
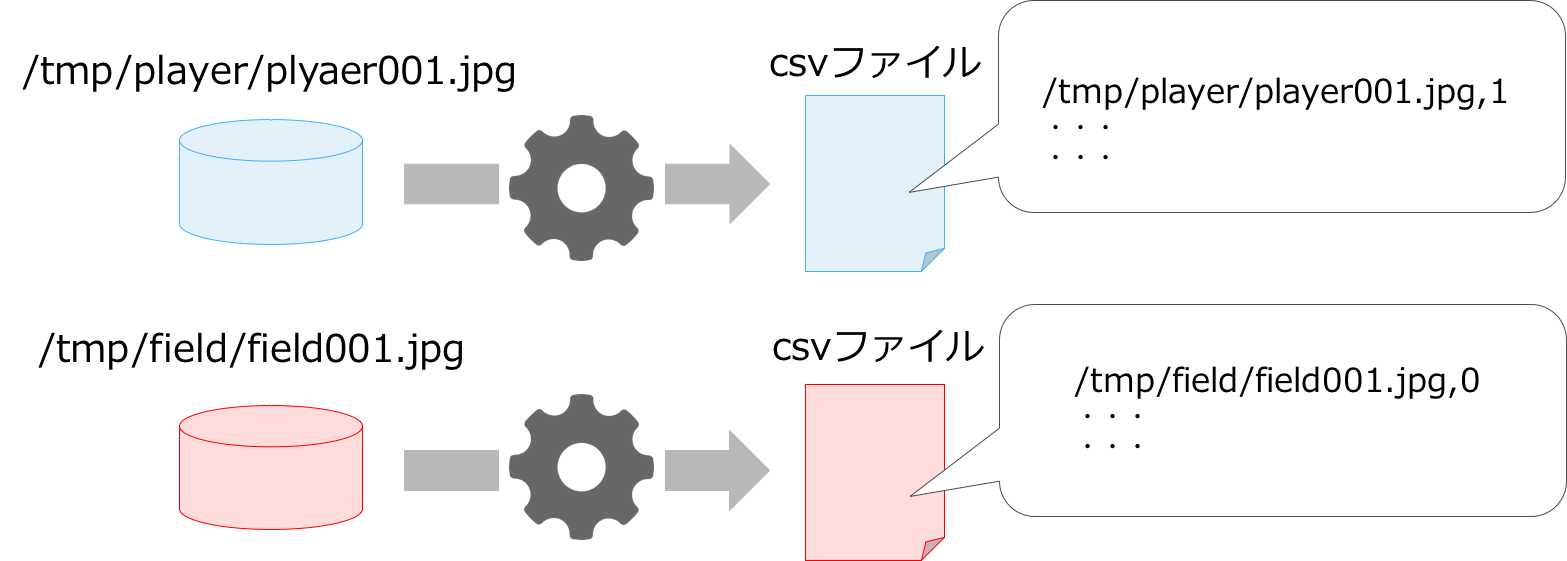
学習のためには使用する画像データには正解ラベル(1の場合)と不正解(0の場合)のラベルを付与する必要があります。今回は必要な判定ラベルを手動で作成するのは非効率であるため,ディレクトリの命名規則に応じて画像の読み込むファイルとその正誤判定を識別するcsvファイルを生成するツールも別途作成しました。仕組みとしては非常に簡単で,下図のようにディレクトリの命名がplayerであれば出力されるcsvファイルには対象画像のファイルパスと正解ラベルである1が記されいくという内容のものです。
このようにデータセットを作成する作業には非常に手間がかかるというのが常であり, DeepLearning を扱う上での1つの課題でもあります。また,今回は単純な2クラス判別のためにラベルとして正解か不正解の0と1のラベルを与えているだけなので半日もかからずに教師データを作成することができましたが,画像中のどこに検出した画像があるのかを出力結果として返すRegion-CNNなどでは学習データに画像中のどこに存在するのかを示す位置情報を一枚のそれぞれの画像に対して用意する必要があるあので非常に時間がかかります。このようにデータセットを用意する部分については課題が多いのでまだまだ対策する余地があると思います。
学習
前処理が終わったのでこれから実際に Tensorflow を用いて画像認識をさせていきたいと思います。
Tensorflowを用いて以下のようなネットワークモデルを形成いたしました。実際に構築したモデルはconvolutional層が2層,pooling層2層,fully_connected層が2層,dropout層が1層の合計7層のニューラルネットワークです。ニューラルネットワークの活性化関数にはRuLU(rectified linear unit)を用いて,最後に出力を確率に変換して出力するためにSoftmax層を用意しております。活性化関数にRuLUを採用した理由としては勾配消失問題を解決するためです。最近ではこの活性化関数をさらに進歩させた関数などが提案されております。また,dropout層では階層の深いニューラルネットを精度よく学習するために提唱された手法の1つで,層の中の幾つかのノードに対して次ノードへの影響を無くして学習を行うことで過学習を避け,汎化性能を向上させる役割を担っております。
それでは実際に学習させてみましょう。
学習している最中には以下のコマンドでGPUの監視を行うことができます。
# nvidia-smiコマンドを用いてGPUの稼働率を確認 $ nvidia-smi Thu Mar 16 13:26:34 2017 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 367.57 Driver Version: 367.57 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce GTX 1080 Off | 0000:01:00.0 Off | N/A | | 27% 33C P8 9W / 180W | 0MiB / 8112MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
また,Tensorflowでは特徴としてtensorboadによる可視化ツールが扱えることを上記で述べました。学習結果を可視化するためには学習するスクリプトに学習結果のログを吐き出す内容を記述する必要があります。そこで,学習を実行するスクリプトの中で以下のログを出力する内容を記述して学習を実行します。
tf.summary.FileWriter(logdir,graph) # logdirにはディレクトリ # graphにはグラフオブジェクト sess = tf.Session() tf.summary.FileWriter(/tmp/log_data, sess.graph) #ログを出力したいlog_dataというディレクトリが/tmp配下にある場合は上記のように書く
これによって実行されたスクリプトは指定したディレクトリ配下にログを吐き出すので,ディレクトリを指定して下記コマンドを実行することでローカルのHTTPサーバでtensorboardがホスティングされ,ブラウザでlocalhost:6006へアクセスすることで学習の様子を確認することができます。
$ tensorboard --logdir=/tmp/log_data
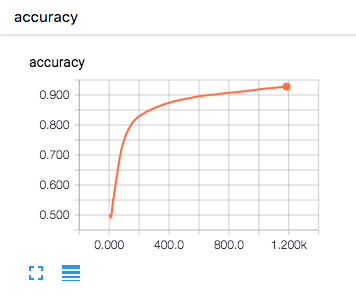
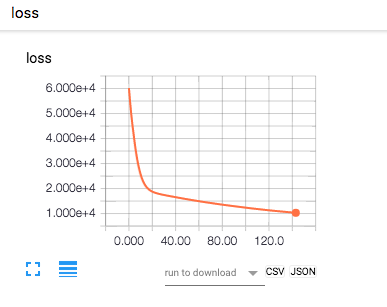
今回実際に上記ニューラルネットモデルとデータで学習の様子を可視化してみました。学習過程と結果は以下のようになりました。
accuracyを見てもらうとわかるように,学習回数を重ねるごとに精度が上昇していることがわかります。今回では,約700回ほどの学習後に正答率が9割の学習モデルになっていることがわかります。今回は用意したデータセット全てを学習せず,1500個の画像のみを使用して学習を行いましたが,最終的に1500回の学習に約1時間30分ほどの時間をかけて,accuracyが 0.943799 ,testデータによる精度が 0.929333 となる高い精度を満たす学習モデルを生成することができました。
このようにニューラルネットでは目的の学習結果が得られるまで,各種パラメータをチューニングして学習を行っていくため途中の過程を可視化して学習が正常に行われているのか,学習モデルの精度は良いかを確認できることは非常に有効であると言えます。
学習後の考察
これまで述べてきた結果と学習からまとめを行っていきます。
GPUの必要性
学習実行の環境にはGPUではなく,CPUのみでの学習も行いました(マシンスペックは下記記載)。当然ですが,GPUに比べて計算時間がかかるのですが,1stepを学習するのに1時間以上かかるため,実用的ではありませんでした。この結果からニューラルネットワークの学習にはGPUリソースを利用しなければ,ほぼ扱えるものではないということが言えます。今後のDeepLearingの利活用にはGPUリソースが不可欠ということでしょう。
・マシンスペック
* CPU:4コア
* Memory:4GB
* SSD:120GB
学習率の関係
学習率を変化させていくとどのような影響があるのかを見てみましょう。学習率は1e-8と1e-4でaccuracyとlossのグラフを比較してみました。比較した様子は以下のとおりです。
- 学習率:1e-4
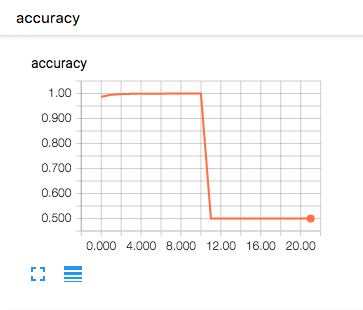
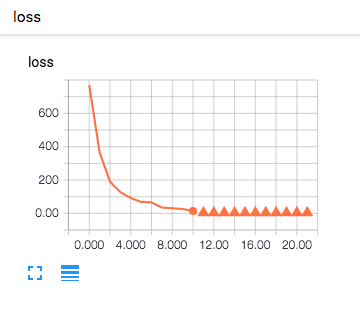
- 学習率:1e-8
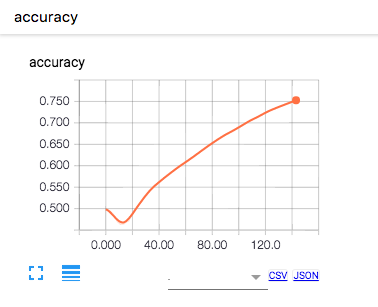
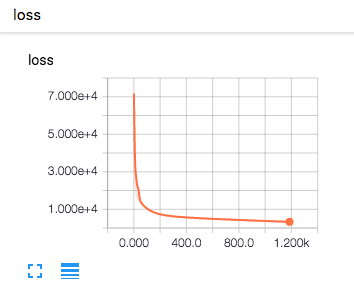
学習率を1e-4で実行すると,accuracyがある時を境に0.5の一定の値になってしまい,うまく学習が収束していません。これは学習時の変化量が大きいため,重みがぶれてしまうため学習がうまくいっていないことがわかります。逆に1e-8では,学習開始した頃はacuuracyは低く,lossも高いのですが,学習回数を重ねるに連れてaccuracyが上昇し,lossが減少していっているのがわかります。
これから言えることは学習率を大きくすると,最適化関数のパラメータを大きく動かすということになります。つまり,1回の学習による変化量が大きいということになります。逆に小さい学習率は,1回の学習の変化量が小さいことから精度よく学習させていくことが可能になります。ただし,トレードオフとして学習回数が増えてしまうことから一概に大きい方が良い,小さい方が良いという判断はできず最適なパラメータを都度求める必要があると思われます。一般的には学習率は大きい値から初めて徐々に小さくして,チューニングを行うことがよくあるそうです。また,以降で述べる最適化手法の中にはこの学習率について最低なパラメータを論文などで提唱しているものもあるので,論文などを見て推奨パラメータを設定すると良い結果が得られる可能性が高くなります。
最適化手法について
学習時に以下の条件で複数の最適化手法について比較を行いました。
- 学習回数:500回
- 学習率:1e-8
- GPU:NVIDIA Geforce GTX 1080
- 活性化関数:RuLU
| 手法 | 分類 | 特徴 | accuracy |
|---|---|---|---|
| GradientDescent | 最急降下法 | 収束が遅い | 0.884249 |
| Adagrad | 確率的勾配降下法 | 収束が早い, 学習率の自動調整 |
うまく収束せず(0.5036) |
| Adadelta | 確率的勾配降下法 | 収束が遅い, Adagradを改良 |
0.881249 |
| Adam | 確率的勾配降下法 | 性能が高い, 最も高い評価 |
0.886399 |
| RMSProp | 確率的勾配降下法 | 収束が遅い, 学習率の自動調整 |
0.844 |
今回の場合は500回のみ学習ということもありますが,「Adam」の最適化手法が最も精度が高いという結果になりました。これはニューラルネットのモデルや用意したデータセットの傾向,学習回数などにも依存すると考えられるので,学習回数を増やしていけば他の手法の方が最適化手法として効果を発揮する可能性はあります.また,収束が早い最適化手法は用意できる学習データが少ない場合などには効果を発揮するということはありそうです。
一般的にAdamは高精度な学習モデルを生成できる良い最適化手法であると評価をされておりますが,扱う問題やデータによってはAdamより他の手法の方が高い精度を出す場合などもある様なので,都度最適なもの探す必要があります。
tf_record型について
学習用のデータを読み込ませる際に画像をそのまま読み込ませても学習可能なのですが,その場合は画像とラベルは別々で用意して学習実行時にラベルと画像を対応付けて活用することになります。しかし,Tensorflowにはこの判定ラベルと画像データをセットで扱うためのファイル形式であるTFRecord(以下,TFRecord形式)と呼ばれる形式が用意されております。また,TFRecord形式の方が実行速度にも差が出てくるため,非常に大きなデータセットを扱う場合などにはTFRecordを積極的に扱うほうが効果が期待されます。
使用方法は学習データのデータセットを事前に作成する際に,複数の関連する情報をまとめてTFRecord形式のファイルに書き込みます。TFRecordファイルはバイナリデータとして書き込まれているので,実行時にTFRecordのファイルを読み込み,デコードすることで画像や属性情報に変換しデータを利用します。実際に今回の学習時もTFRecordを使用した場合の方が処理が早く実行される傾向が見られることも確認しました。これはバイナリデータとして使用しているために,I/Oが高速に行われたためではないかと考えられます。
Kearsとの比較
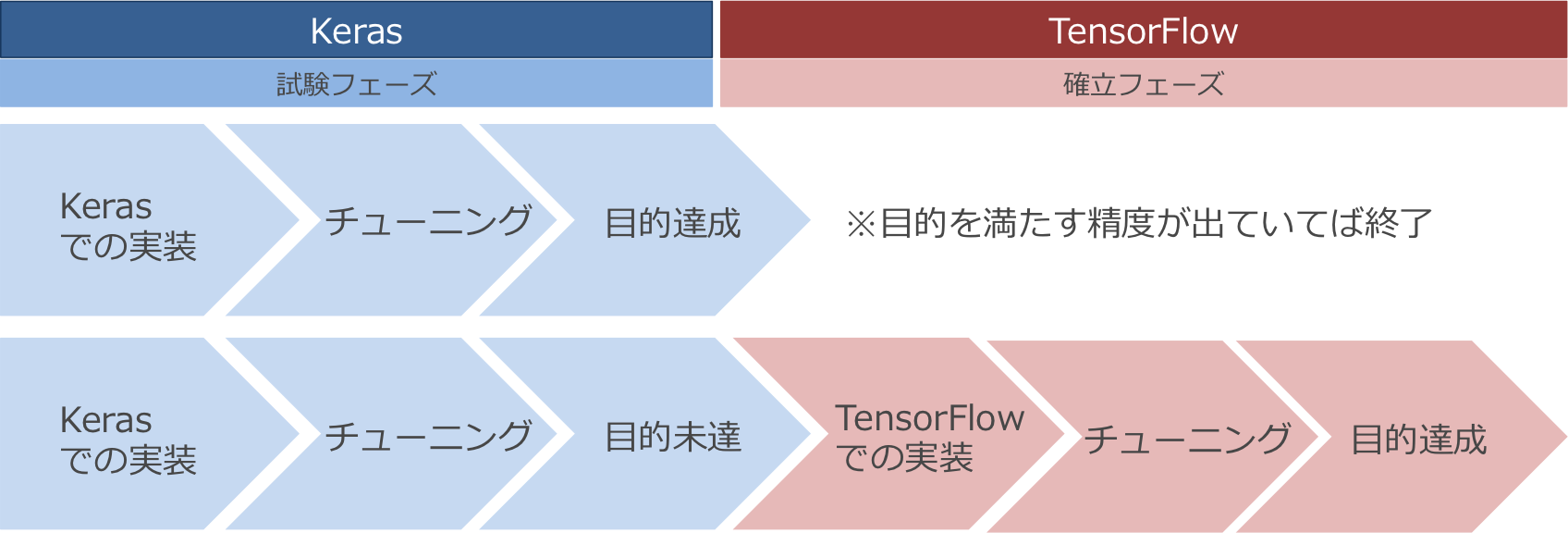
Tensorflowは各々の目的に応じて,様々なパラメータを変更して目的を満たす学習モデルを生成できることを確認しました。また,多種多様なパラメータを変更できるが故に,ある程度ニューラルネットワークがどのような仕組みで学習を行っているのかを理解した上で自由に扱うことができる便利なツールであると言えます。本番環境や高精度を出すために複数のパラメータをチューニングするといった場合の用途で活躍しそうです。言い換えると,プロトタイプなど簡単に試したいという時には,少しコストがかかりそうではあります。そこで,Tensorflowのwrapperとして簡単にアルゴリズムを記述することができるKerasというライブラリがあります。こちらの方が直感的にモデルの構造や最適化手法を記述することができるので初心者でもニューラルネットのモデルを簡単に作成することができます。そのため,学習モデルを作り始めの時やプロトタイプ作成の場合にはKerasを用いて,目的を満たすために試行を何度も繰り返してある程度の精度が出せた段階で,Tensorflowで細いパラメータチューニングを実施して実装し,高い精度を出すモデルや商用システムなどに適応していくなどの役割で進めいくのが良いと言えるでしょう。
開発イメージ
まとめ
NTTPC では皆様により良いサービスを提供できるように,日々新しい技術を活用したサービス開発に取り組んでおります。今回の DeepLearning への取り組みもその一環です。まだまだ,私たち自身も手探り状態で進めている段階ですが,自社のサービスへの活用を目指し挑戦をし続けて,皆様から必要とされるサービスを提供できるようにと考えております。今後は私たちの主力事業である通信事業から得られるデータ等に焦点を当てて DeepLearning の活用を目指していきたいと思います。また,サービスを通じて皆様に新しい価値を提供できるようになることを楽しみにしています。