



基礎知識
データサイエンスを加速するGPU:機械学習・大規模データ分析における活用法と業務要件から考えるGPU導入判断のポイント
2025.10.08

GPUエンジニア
生成AIの台頭により、データサイエンスの現場では非構造化データの活用が急速に広がり、分析手法や処理要件にも大きな変化が生まれています。特に、機械学習や深層学習、自然言語処理といった高度な分析では、従来のCPUでは処理が追いつかず、GPUによる並列処理の活用が注目されています。
本記事では、こうした背景を踏まえ、データサイエンスで求められる代表的な分析手法から、処理のボトルネックとなりやすい課題、そしてGPUによる高速化の実践的な選択肢までを解説します。Python環境で使えるライブラリ、導入判断のポイントなど、現場で活かせる視点を交えて紹介していますので、「そろそろデータ分析でのGPU活用を検討したい」という方はぜひ参考にしてください。
目次:
- データサイエンスとは:ビッグデータから生成AI時代への進化
1-1. 生成AIによって可能になった「非構造化データ」の処理
1-2. 前処理のあり方が大きく変化 - データサイエンスに関係する代表的な分析手法と活用領域
- データサイエンスの制約とその解消法
3-1. 制約1:データの多様な形式と重さが、処理を複雑化
3-2. 制約2:モデルの高度化による、演算処理の限界
3-3. 制約3:分析・インフラ面でのコストとスキルの不足 - なぜデータサイエンスにGPUが必要なのか?──GPUの構造理解
4-1. CPUとGPUの違い
4-2. GPUを活かすライブラリと開発環境 - 自組織の分析にGPUは必要か?──業務要件から考える導入判断の視点
5-1. 並列化できる処理か?
5-2. 処理時間がボトルネックになっているか?
5-3. PythonやGPU対応ライブラリが使える体制か?
5-4. 小規模PoCで費用対効果を検証できるか? - まとめ
1. データサイエンスとは:ビッグデータから生成AI時代への進化
データサイエンスとは、膨大なデータを収集・分析し、そこから価値ある知見を導き出すための学問・技術分野です。統計学、機械学習、コンピュータサイエンスなどを横断的に活用し、業務や研究の意思決定を支える基盤として広く活用されています。
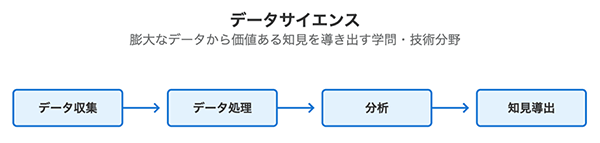
データサイエンスの処理プロセスイメージ
従来のデータサイエンスは、主に数値や表形式の構造化データを対象とし、いわゆる「ビッグデータ」の分析が中心でした。たとえば、売上データやセンサーログを使った傾向分析・予測などが代表例です。しかし近年では、生成AIの台頭により、分析対象データの種類と前処理の役割が大きく拡張・変化しています。
1-1. 生成AIによって可能になった「非構造化データ」の処理
生成AIの普及により、これまでの分析では扱いづらかった非構造化データの利活用が、企業活動において急速に拡大しています。
たとえば、以下のようなデータが対象です。
- テキストデータ(自然言語):問い合わせ内容、議事録、チャットログなど
- 画像・映像:監視カメラ映像、製品検査画像、医療画像
- 音声・動画:コールセンター音声、面談録音、講義動画など
これらの情報は、人間にとっては直感的に理解しやすい一方で、従来の機械による処理では意味の把握や文脈の理解が難しく、高度な前処理や解析技術が必要とされてきました。
しかし近年、生成AIの登場によって、このような非構造化データの処理が大きく前進しています。従来のシステムがテキストを単なる文字列、画像をピクセルの集合として扱っていたのに対し、生成AIは人間に近い形で意味や文脈を捉える処理が可能です。大規模な自然言語モデル(LLM)やマルチモーダルモデル(VLM)により、非構造化データから有用な情報を抽出・変換できるようになったことで、生成AIは非構造化データの利活用を飛躍的に進める技術基盤として、実務における役割を急速に高めています。
1-2. 前処理のあり方が大きく変化
特に注目すべきは、こうした変化に伴い前処理のあり方そのものが大きく変化している点です。従来のデータサイエンスでは、構造化データ(CSVなど)を前提とした「欠損値の補完」や「特徴量エンジニアリング」が中心でしたが、生成AIの登場により、非構造化データをAIにとって意味のある形式へ変換するための新たな前処理が求められています。
| 項目 | 従来の前処理 | 生成AI時代の前処理例 |
|---|---|---|
| データ形式 | 構造化(CSVなど) | 非構造化(画像・音声・自然言語) |
| テキスト処理 | トークン化、ストップワード除去など | 文脈保持、要約生成、意味ベースのフィルタリング |
| 画像・音声・映像の整形 | ノイズ除去、サイズ統一 | エンベディング変換、マルチモーダル統合 |
| モデル入力に向けた整形 | 数値正規化、カテゴリ変数変換など | LLMやVLM用のプロンプト設計・フォーマット変換 |
つまり、データサイエンスの領域は「整った数値データを扱う技術」から、「人間が扱うあらゆる情報をAIによって意味ある形に変換する技術」へと進化しています。この変化に伴い、処理対象のデータが大規模化・複雑化し、演算処理能力の高いGPUの導入が、企業の現場でも欠かせない選択肢になりつつあります。
2. データサイエンスに関係する代表的な分析手法と活用領域
データサイエンスは単なるAIの活用にとどまらず、「課題に応じて適切な手法を選び、データから価値を引き出す」ための体系的なアプローチです。実務では、以下のような多様な手法が目的やデータ種別に応じて使い分けられています。
まず基本となるのが、記述統計や推定・検定といった統計学に基づく手法です。これらはデータの傾向をつかんだり、施策の効果を検証したりするために活用され、主に表形式(構造化データ)の集計や比較分析で使われます。より応用的な領域に進むと、機械学習による分類・予測や、深層学習による非構造化データ(画像・音声・テキストなど)の解析、さらに自然言語処理(NLP)や生成AIといった新しいAI技術の活用が主流になります。そして近年では、AI自身が最適な行動を学ぶ強化学習も注目されています。
以下に、実務で活用される代表的な分析手法を整理しました。
| 手法カテゴリ | 主な手法 | 活用目的・特徴 |
|---|---|---|
| No1. 記述統計 | 平均、中央値、分散、ヒストグラムなど | データの傾向を把握するために用いられる。グラフ化や要約に適する。 |
| No2. 推定・検定 | 回帰分析、相関分析、t検定、χ²検定など | 母集団の特性を推定し、差異や関係性の有無を統計的に検証する。 |
| No3. 機械学習 | 決定木、SVM、ランダムフォレストなど | 既存データからパターンを学習し、分類や予測を行う。 |
| No4. 深層学習 | ニューラルネットワーク、CNN、RNNなど | 非構造化データ(画像・音声など)に対応可能な高精度な学習手法。 |
| No5. 自然言語処理 | 文書分類、感情分析、要約、翻訳など | テキストデータを解析し、分類・理解・生成を行う。 |
| No6. 生成AI | ChatGPT、画像生成AI、音声合成など | テキスト・画像・音声などの新しいコンテンツを生成する技術。 |
| No7. 強化学習 | Q学習、Deep Q Network など | 試行錯誤を通じて最適な行動を学習。戦略策定や自律的な意思決定に活用される。 |
このように、データサイエンスには統計学的な手法から高度なAI技術まで、幅広いアプローチが含まれています。中でも、AI活用が本格的に問われる領域は、No.3の「機械学習」以降の手法群です。
具体的には、機械学習・深層学習・自然言語処理(NLP)・生成AI・強化学習といった領域が該当します。いずれも大量かつ多様なデータを前提とし、それに応じた高い計算処理能力が求められます。こうした手法の高度化とデータの肥大化は、処理時間やコスト、設計上の複雑性といった新たな課題を生み出します。
3. データサイエンスの制約とその解消法
高度な機械学習モデルや生成AIの活用等のデータサイエンスが進む一方で、それらをビジネス現場や研究の場に導入しようとすると、いくつかの共通した「壁」に直面します。ここでは、データ活用の現場で抱えがちな課題と、その解消に向けた現実的なアプローチを整理します。
3-1. 制約1:データの多様な形式と重さが、処理を複雑化
データサイエンスの現場では、構造化データ(数値・カテゴリ・表形式)が依然として多くの意思決定の基盤となっています。一方で、前述のとおり近年は、生成AIや深層学習の進展に伴い、テキスト・画像・音声などの非構造データを分析対象とするニーズも急速に拡大しています。こうした変化により、従来のルールベースETLや表形式前提の前処理では対応しきれず、属人化や処理遅延といった問題を引き起こすケースが増えています。
特に、以下の2点が前処理の複雑化を引き起こす要因となります。
- 形式の多様性:自然言語・画像・動画・音声といった多様なデータごとに、処理手順や整形方法が異なり、統一的な対応が困難。
- 情報量の多さ:非構造データは1件あたりのサイズが大きく、処理の計算負荷が高い。
▶ 解決策:前処理の再設計 × GPUによる処理基盤の強化
これからの生成AI時代において多様化・大規模化するデータに対応するには、従来の前処理手法を見直し、生成AIを前提とした前処理フローへ再設計することが本質的な解決策となります。テキストだけでなく、画像・音声・動画といった高負荷な非構造データや膨大なビッグデータを扱う場面が増える中、それらを現実的な処理時間で支える基盤としてGPUの活用が不可欠となります。
3-2. 制約2:モデルの高度化による、演算処理の限界
生成AIや深層学習モデルの高度化に伴い、1モデルあたりのパラメータ数や処理対象データの規模が急激に増大しています。
特に自然言語処理(NLP)、画像・音声認識、動画解析などのタスクでは、モデルの実行にかかる計算量が膨大で、従来のCPUベースの環境では学習や推論に多大な時間を要することが、実運用上の大きな障壁となっています。また、リアルタイム応答や低遅延処理が求められる業務アプリケーションでは、1秒の遅延がUXや業務成果に直結するケースも多く、計算処理の遅さはビジネス上の制約に直結します。
▶ 解決策:AI処理を実運用に落とし込むための設計と基盤の最適化
モデルの高度化に対しては、モデル設計・処理方式・実行基盤の三位一体で最適化を図ることが本質的な対応策です。
たとえば以下のようなアプローチが有効です。
- 【モデル設計】モデルの軽量化や推論最適化による演算負荷の削減
- 【処理方式】バッチ処理や非同期化による処理の再設計
- 【実行基盤】高負荷な処理に対しては、GPUなどの並列処理基盤の導入
具体的なアプローチ方法については次の関連記事もご参照ください。
関連記事:ディープラーニングにGPUが求められる理由・ビジネスにおける活用方法
3-3. 制約3:分析・インフラ面でのコストとスキルの不足
多くの企業では、「どの分析モデルを選ぶべきか」「GPUをどこまで活用するか」といった設計段階での判断に迷いが生じやすくなっています。また、前処理や特徴量設計といった分析プロセスには高度な専門性が求められ、社内の人材リソースだけでは対応が難しいケースも少なくありません。さらに、GPUインフラの導入には、初期コストや構成設計、ライブラリ対応、運用ノウハウの確保など、技術面・コスト面の両面で高いハードルがあります。
▶ 解決策:分析設計とインフラ運用を支える外部連携と支援体制の整備
分析設計の面では、データサイエンティストやAIエンジニアといった専門人材の知見を取り入れることで、モデル選定や前処理設計の精度と効率が向上します。また、データの要約・分類・仮説出し・コード生成といった定型作業の一部を生成AIに任せる活用法も広がっており、仮説構築や壁打ちのパートナーとして使うのも有効です。
一方、インフラ面では、GPU環境の設計・構築・運用を支援する外部パートナーを活用することで、初期導入の負担を軽減し、継続的な運用の安定化と効率化を実現できます。インフラ構築や最適な構成のご相談については、NTTPCにお気軽にお問い合わせください。
4. なぜデータサイエンスにGPUが必要なのか?──GPUの構造理解

ここまで、生成AI時代のデータサイエンスにおいて、前処理やモデル運用といった各工程の基盤としてGPUが果たす役割をお伝えしました。ここでは一歩踏み込んで、「なぜGPUなのか」──特にCPUとの構造的な違いや、GPUの活用環境を整理します。
4-1. CPUとGPUの違い
従来のデータサイエンス処理は、主にCPU(中央処理装置)によって実行されてきました。CPUは汎用性が高く、判断・制御といった逐次処理に優れたプロセッサです。一方で、GPUは、大量のコアによる並列演算に特化した構造を持ち、行列演算やベクトル処理など、生成AIや機械学習に不可欠な計算を高速にこなせるのが特徴です。この構造の違いが、特に処理時間・実行コスト・電力効率といった点で、両者の間に大きな性能差をもたらしています。
以下に、CPUとの違いをまとめました。
| 比較項目 | CPU | GPU |
|---|---|---|
| 処理方式 | 逐次処理(1つずつ) | 並列処理(同時に多数の処理) |
| コア数 | 数個~数十個 | 数千個以上 |
| 得意な処理 | 複雑な判断・制御 | 行列演算・ベクトル処理・大量データの並列処理 |
| 向いている用途 | アプリケーション制御、基本的な分析等 | 機械学習、深層学習、生成AI、大規模データ処理 |
| 処理速度 | 単体処理は高速だがスケールしにくい | スループットが高く、計算量が多いほど効果的 |
| 消費電力 | 比較的低い | 高負荷時は大きいが処理あたりの効率は高い |
特に生成AIのような演算負荷の高いユースケースでは、GPUによる処理基盤の導入が現実的な選択肢となっています。CPUとGPUの違いの詳細は関連記事をご参照ください。
関連記事:CPUとGPUを徹底比較:導入で差がつく基礎知識と選択の仕方
4-2. GPUを活かすライブラリと開発環境
GPUによる高速化は、ハードウェア性能だけでは完結しません。実際にGPUの並列処理能力を業務で活用するには、それを支える専用ライブラリや開発環境の存在が不可欠です。現在、生成AIや高度なデータ分析の分野では、Pythonが事実上の標準言語となっており、GPU対応ライブラリの多くもPythonを中心に開発・提供されています。これにより、GPUの高い処理性能を実務へ取り入れるためのハードルは着実に下がってきています。
以下に、Pythonで広く使われている代表的なGPU対応ライブラリを整理しました。
| ライブラリ | 主な用途 | 特徴 |
|---|---|---|
| cuDF | 表形式データの処理(pandas代替) | 数千万行規模のデータも高速に変換・集計が可能 |
| cuML | 機械学習アルゴリズム | 線形回帰・クラスタリングなどをGPUで高速に処理 |
| cuGraph | グラフ構造分析(例:SNS・ネットワーク解析) | PageRank・連結成分解析などの処理が可能 |
| XGBoost (GPU版) | 高精度な予測モデルの学習 | 大規模な表形式データを用いた学習を大幅に短縮 |
| PyTorch / TensorFlow | 深層学習 | 画像認識・自然言語処理などAIモデルの開発における標準フレームワーク |
これらのライブラリの多くは、NVIDIAの「RAPIDS」エコシステムや、GPU向けの並列処理技術であるCUDAを基盤に構築されており、既存のPythonコードを大きく書き換えずにGPU高速化が可能です。
5. 自組織の分析にGPUは必要か?──業務要件から考える導入判断の視点
生成AIや機械学習の実装が進む中で、GPUを活用した処理高速化のニーズは高まりつつあります。しかし、GPUはすべての業務や処理に対して一律の効果をもたらすわけではありません。むしろ、処理の構造や業務上の要件を踏まえたうえで、適切に導入判断を行うことが重要です。
ここでは、GPU導入の是非を判断するにあたって押さえておきたい4つの実務的な視点を整理します。自社のデータ処理環境や分析業務の特性と照らし合わせながら、投資判断やPoC設計の検討材料としてご活用ください。
5-1. 並列化できる処理か?
GPUは、大量のデータに同一の処理を一括で実行する並列処理に強みがあります。そのため、対象の処理が「逐次処理」ではなく、「同種の処理の繰り返し」であることが重要です。
- 適している例:数百万件のデータへのスコア計算や特徴量生成、大量画像への分類処理など
- 適していない例:複雑な条件分岐や手続き型の制御が中心の処理
5-2. 処理時間がボトルネックになっているか?
高速化による恩恵が業務に直結するかどうかは、GPU導入の判断材料として非常に重要です。時間短縮によって意思決定や顧客体験の向上が見込める場面では、投資対効果も明確になります。
- 適している例:推論処理に遅延があるレコメンドエンジン、学習に数時間を要するモデル更新
- 適していない例:時間が長くかからない処理や夜間に実行し、翌朝までに終われば問題ない処理
5-3. PythonやGPU対応ライブラリが使える体制か?
GPUの恩恵を最大限に活かすには、cuDFやPyTorchなどのGPU最適化ライブラリを扱える環境が必要です。特にPythonが分析業務の基盤にあるかどうかが、導入のしやすさを左右します。
- 適している例:Jupyter NotebookやPythonベースでの分析が日常的に行われている現場
- 適していない例:ExcelやSQLのみで分析業務が完結している体制
5-4. 小規模PoCで費用対効果を検証できるか?
GPU導入の効果は、まずは限定的な処理から試すことで明確になります。PoC(概念実証)で処理時間やスループットの改善を定量的に確認できれば、本格導入の意思決定もスムーズになります。
- 適している例:既存処理との比較が容易な夜間バッチ処理や定型的な学習処理
- 適していない例:成果指標が曖昧で改善効果が測定しにくい処理
これらの4点をチェックすることで、「自社にとってGPU導入が本当に意味を持つか」「どこから始めるべきか」の判断軸が整理できます。無理に全体最適を目指すのではなく、まずは一部の処理から、PoCベースでの導入を検討することも良いスタート地点となるでしょう。
6. まとめ
本記事では、データサイエンスの概要、データサイエンスの処理形式の変化、それによるGPU活用の重要性や実務への導入ポイントなどを解説しました。生成AIの普及により、構造化・非構造化データを含む大規模処理が求められる今、GPUは単なる性能向上ではなく、「実務での成果」に直結するインフラとなりつつあります。
本記事ではGPUに焦点を当てて解説しましたが、高速なデータ分析基盤を構築するためには、GPUを効率的に利用するための高速ネットワークや、大容量ストレージとの連携も欠かせません。
NTTPCは、GPU活用の導入検討から、用途に合わせた適切なネットワーク、ストレージ機器の選定、具体的な構成の設計や運用管理まで、企業、研究機関等の組織が抱える実務課題にあわせてトータルでご提案しています。大学・研究機関における大規模モデリング、製造業での異常検知、マーケティング領域でのユーザー動向データ分析など、業種・分野を問わず幅広い支援実績があります。まずはお気軽にご相談ください。
▶︎ お問い合わせはこちら