



トレンド
NVIDIA GTC2024 現地参加レポート(基調講演編)
2024.04.16

GPUセールス&マーケティング担当
亀谷 淑恵

みなさんこんにちは。NTTPCでGPUセールス&マーケティングを担当する亀谷です。
このたび、2024年3月18日~22日(現地時間)にカリフォルニア州サンノゼで開催された「GTC2024」に、私を含めた当社チームが参加しました。GTC(GPU Technology Conference)は、NVIDIAが毎年主催している世界的なAIカンファレンスです。
例年、NVIDIAのCEOであるJensen Huang 氏による基調講演が行われ、新型GPUアーキテクチャなどの大きな発表がなされます。世界のAIトレンドを予測するような注目度の高いイベントのため、NVIDIAユーザー・パートナーのみならず、多くの報道関係者も参加します。
前回まではコロナ禍によりオンライン開催がメインになっていましたが、2024年は5年ぶりに全世界から参加者が集まりました。900以上のトークセッション・パネルディスカッション・ワークショップ等のセミナーが開催され、約300社が展示ブースを構えていました。
リアル開催と合わせて、オンライン配信も行われました。現地での参加者が3万人超、オンラインでの聴講登録者はなんと約31.9万人です。ちなみに、円安の影響で日本からの現地参加者はやや少なく、330名ほどということでした。
GTCの一部セッションはアーカイブ動画を見ることができますので、ぜひ下記URLよりご覧ください。
公式サイト:https://www.nvidia.com/ja-jp/gtc/
すでに多くのメディアで基調講演での発表内容が報じられていますが、今回のレポートでは、特に現地で参加者の関心を集めていたセミナー・ブースや、今後の日本市場に大きな影響を及ぼす可能性のある点など、私が注目したポイントをお届けします。
基調講演
GTC初日である3月18日13時(現地時間)より、NVIDIA 創業者/CEO の Jensen Huang 氏による Keynote (基調講演) が行われました。今回のGTCのメインイベントであり、参加者はみんなこの基調講演を見に来ています。
2019年まではサンノゼ内の別の会場で開催されていましたが、今回は多くの来場者が見込まれるため、11,000席を用意できるSAP Centerに場所を移されました。それでも2階席まで超満員で、会場内は熱気に包まれています。日本からも報道陣や大学関係者など、さまざまな立場の方が来場されていました。

イベント開始前 リアルタイム3Dアート生成のパフォーマンスが行われている
Jensen氏が登壇し、会場の盛り上がりはピークに達します。これまでのAIテクノロジーとNVIDIAの進歩を振り返ったあと、いよいよ新しい製品・ソリューションの発表に移ります。
2時間超の基調講演の中で私が注目したのは、以下の3点です。
なお、以降の画像は基調講演のYouTubeアーカイブ動画から抜粋しています。
1. 最新GPUアーキテクチャ”Blackwell”
これまでにも情報が小出しにされていましたが、今回正式に次世代GPUアーキテクチャ「Blackwell」が発表されました。ゲーム理論と統計を専門とする数学者、David Harold Blackwellにちなんで名付けられたNVIDIA Hopper™ アーキテクチャの後継となるモデルです。

Blackwell 1基に2つのGPUが搭載されている
Blackwellアーキテクチャは生成AI/LLMの学習と推論(特に推論時)に高い性能を発揮し、前世代の「Hopper」世代のNVIDIA H100 Tensor Core GPUと比較し、GPUメモリは80GB⇒192GBに向上、浮動小数点演算ベースのAI処理性能は5倍(20PFLOPS)を達成しました。Blackwellを採用した製品は2025年後半からの出荷開始を予定しています。
Blackwellは、新たにFP4(4ビット浮動小数点演算)に対応したことが注目ポイントです。H100以降、NVIDIAの生成AI向けチップには「Transformer Engine」が採用されています。
これは、より高速化・正確性を実現できるワークロードにはFP4を適用し、それ以外はFP8やFP16を利用する といったように、GPU側で最適な演算方法を選択してくれる機能です。演算結果の統計情報を基に自動的に選択されるため、利用者側で操作を行う必要はありません。
1基あたりの性能向上も目を見張るものがありますが、私が驚いたのはBlackwellの拡張性の高さです。下表のように、複数のGPUを束ね、さらにそれを統合していくことで、最大32,000GPUを備えたデータセンターにまで拡張できるという構想が示されました。
第5世代NVIDIA NVLink🄬が実装されたことで、NVLink帯域幅はこれまでの2倍の1.8TB/s(双方向)となり、大規模な拡張プラットフォームであっても高速インターコネクト接続を実現できるようになりました。
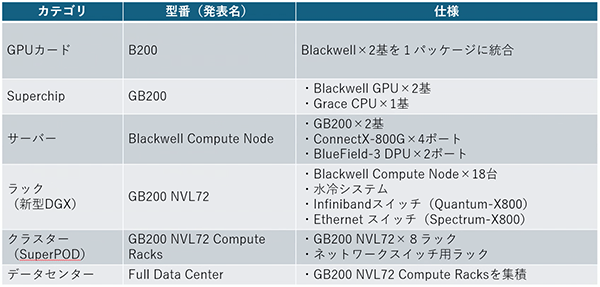

また、GB200に採用されているフルスペックのB200 GPUは、1カードあたりの消費電力が1,200Wになるようです。1つのサーバに8枚搭載すると、GPUだけで9,600Wになる計算です。
この規模のGPUリソースを必要とする用途とはいったい・・・?と驚かれる方も多いかもしれません。私もその一人です。しかし、べき乗則(スケール則)の考え方に基づいてモデル規模が飛躍的に増加しているLLM研究開発では、GPUの演算性能がカギになります。
Jensen氏曰く、「Hopper×8,000基だと90日(消費電力:15MW)かかるモデルでも、Blackwellなら2000基(消費電力:4MW)と4分の1で済む」ということ。Blackwellを採用することで、計算時間と消費電力の大幅な効率化を図ることができます。

このほか、Blackwell GPUをそれぞれ8基搭載した「NVIDIA HGX B100 / B200」(NVIDIA HGX H100の後継シリーズ)や、統合AIインフラストラクチャであるNVIDIA DGX™ H100の後継となる「NVIDIA DGX B200」もリリースされています。
2. NVIDIA AI Enterprise 5.0 とNIM(NVIDIA Inference Microservices)
今回発表されたNVIDIA AI Enterprise 5.0の目玉は、AI推論モデルを本番環境に展開するために必要なミドルウェア・ソフトウェアをひとまとめにしたマイクロサービス「NVIDIA NIM」(NVIDIA Inference Microservices)が追加されたことです。
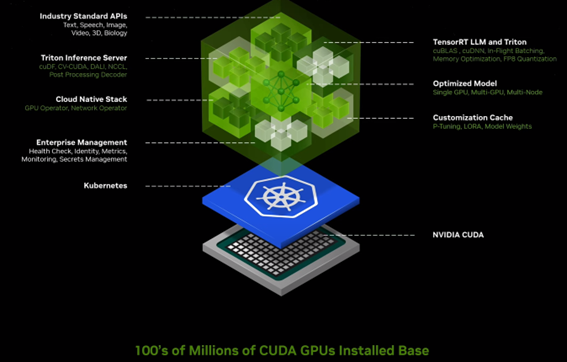
CUDAをベースに展開されるプラットフォーム
NIMを利用することで、Llama2をはじめとするオープンソースの大規模言語モデル(LLM)を素早く自己ホスト型で動作する環境を構築できます。
これまでは、RAG(Retrieval-Augmented Generation)※技術を用いて、ローカルにある情報をChatGPT等の外部リソースに送信する事で処理を行っていましたが、自己ホスト型では外部にデータを送信する必要が無いため、機密情報も安全に取り扱うこともできます。
※RAG:LLMの生成能力を向上させる技術。従来のLLMは、膨大なテキストデータを用いて訓練されていたが、それでも不正確な情報や偏見を含む回答を生成してしまう(ハルシネーション)のリスクがあり、ローカル情報を生成に使うにはファインチューニングが必要不可欠だった。RAGを用いて、事前に信頼できる外部データソースから関連情報を検索し、生成に利用することで、情報の信頼性を向上させるとともに、ファインチューニング無しで内部情報を扱えるといったメリットがある。
NIMは生成AIの「推論」のためのマイクロサービスとして発表されました。基調講演以外のセッション・展示も含め、今回のGTCでは全体として「学習」から「推論」へ市場の関心が移り変わっているように感じました。
生成AI/LLMの研究開発(初期学習)フェーズから、商用サービスとして展開する推論フェーズへ移行し、生成AIの産業実装がより具体的に進んでいるといったグローバルトレンドが見えます。
NVIDIA NIMには、「Triton Inference Server」や「TensorRT-LLM」など、生成AIの推論に必要なソフトウェアがプリインストールされ、業界標準API経由で簡単に起動することができます。
「もうPythonのコードを大量に書く時代は終わった」「AIアプリケーションの導入に数週間かかっていたところ、数分にまで短縮できる」と基調講演で言及されていました。ぜひ当社でも試用してみたいです。
NVIDIA GPUを搭載し、CUDAが動作する環境であれば、DGXでもHGXでも、AWS/Azureなどのクラウド環境でも、コンテナが実行できればどこにでもKubernetesベースでNIMをデプロイできます。
NVIDIA AI Enterpriseに含まれるサービスなので、EnterpriseレベルのNVIDIAテクニカルサポートが利用可能で、NVIDIAのテクニカルエンジニアへ問い合わせることができます。OSSにはない手厚いサポートが嬉しいポイントですね。
NVIDIAはひとくくりに「半導体メーカー」と呼ばれることがありますが、CUDAやNVIDIA AI Enterprise、NVIDIA Base Command™といった、開発者向けのソフトウェアスタックを提供していることこそが、市場優位性の源泉となっています。
私自身はAI開発者ではないので詳しく語れませんが、いったんNVIDIAソフトウェアをお試しで使い始めると、どんどん使いやすくアップデートが進み、開発メンバが増えた際のスケールアップにも対応できるので非常に有用 というお客様のお声をよく伺っています。
3. Omniverse新機能
デジタルツイン環境を実装する際、最も手間がかかるのが基になる3次元データの制作です。今回発表されたOmniverseの新機能「ChatUSD」では、LLMとの連携が図られ、テキスト形式のプロンプトを入力するとそれに沿ったモデルを自動生成してくれるようになりました。

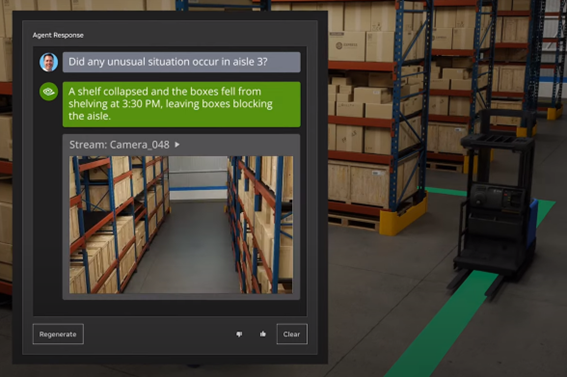
また、産業用シミュレーターである「Isaac Sim」にも大きなアップデートがありました。ロボティクスシミュレーション機能では、リアル空間で何らかの予測不可能なイベントが起こった際に、実センサデータからそれを感知し、バーチャル空間にも反映して、自動的にロボットの挙動を変更することが可能です。例えば、倉庫内の3番通路で貨物が崩れてしまった場合、AGVが3番通路を通らないよう進路を自動調整します。

さらに、こちらもLLMに対応します。「3番通路で何が起こったの?」と問いかければ、「3:30にコンテナが崩れ落ちてきて通路が走行不能になりました」とIsaac Simが回答し、その時間のカメラ映像を添付してくれます。まさにAIが倉庫内のオペレーターの役割を果たしています。
Omniverse Cloudは、Omniverse Cloud APIにより、さまざまなデバイス・サービスと連携できるようになります。AppleのVRヘッドセット「Vision Pro」とOmniverseポータルとの連携も発表されました。Omniverseで制作したデジタルツイン空間に、Vision Proを使って閲覧・操作可能・・・ということだと思われますが、具体的なワークフローやリリース時期は未定のため、詳しいことが分かり次第当社でも検証したいと思います。

基調講演だけでずいぶん長くなってしまいました。後編記事では、その他の注目セッションの模様や、会場内で注目を集めていた展示ブースをご紹介します。