



技術解説
機械学習によるロシアW杯の優勝予測
2018.07.25

サービスクリエーション本部
データサイエンティスト
張 暁楠

はじめに
4年に1度開催され、今回で21回目を迎えるサッカーワールドカップが熱狂の渦の中、ついに閉幕しました。 今大会ではFIFAランキング7位のフランスが優勝しましたが、皆さまの予想結果はいかがだったでしょうか。私は実は今回、仕事と趣味を兼ねて機械学習を用いた優勝国の予測を行っていました。本記事では、学習データセットやモデル作成、予測結果など、そのシミュレーション内容をレビューしたいと思います。
目標
サッカーの試合に影響する要因が複雑であり、たとえば試合当日の選手の健康状態やレッドカードによる退場処分のような不安定要因が存在します。そのため、すべての要素を機械学習で扱うのは困難だと考えられます。また、精度の高い予測を行うためには、大量の訓練データが必要ですが、現状では試合結果などのデータはあるが、歴代のチームや選手のデータがなかなか手に入れることができません。上記を踏まえて、今回の分析目標を下記のように設定しました。
- 機械学習を用いてロシアW杯の試合結果を予測し、考察をおこなう
なお、執筆時点で、準決勝戦まで終了しているため、グループステージまでのデータを用いて、決勝トーナメントの試合結果を予測するものとしました。
データの準備
今回の予測には、2種類のデータセットを用いました。
チームデータ
1つ目はこちらのサイトより取得した各チームの戦力を表す出場選手の「市場価値総額」、「平均年齢」、「人数」などです。
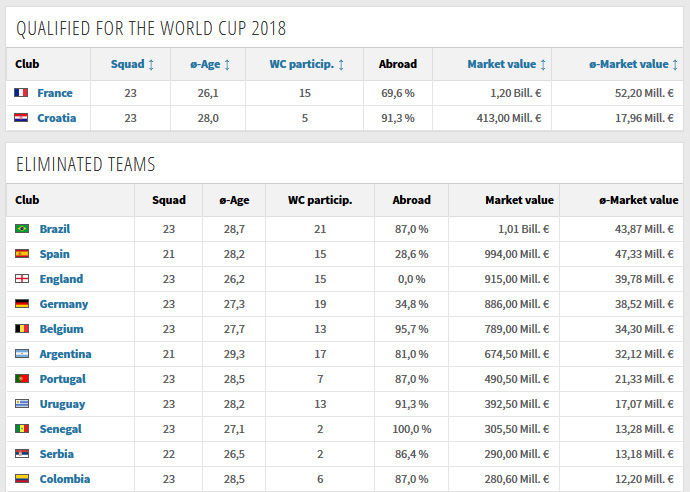
データの収集は、BeautifulSoupというライブラリを利用してスクレイピングを行い、データセットを作成しました。スクレイピングを行うと、スペースや他の数値でない符号が数値データと混在しており、使えるようにするために正規表現などの方法でデータを整理する必要やNullの項目をデータから除去する必要があります。
今回作成したスクレイピングコードの一部を次に記載します。
...
import requests
from bs4 import BeautifulSoup
...
def getHistoryValue(url):
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36'}
page = url # アクセスするURL
pageTree = requests.get(page, headers=headers)
pageSoup = BeautifulSoup(pageTree.content, 'html.parser')
# 指定したクラスを満たすtdを返す
clubs_td = pageSoup.find_all("td", {"class": "links no-border-links hauptlink"})
clubs = []
# tdの内容(チーム名)をリストに格納する。
for td in clubs_td :
clubs.append(td.findAll('a')[0].string)
...
取得したデータは次のようになります。
「市場価値総額などのチーム情報の一部」
| club | Squad | ø-Age | WC particip. | Abroad | Market value | ø-Market value | rmv | remv |
|---|---|---|---|---|---|---|---|---|
| France | 23 | 26.1 | 15 | 69,6 % | 1,08 Bill. € | 46,98 Mill. € | 1080 | 46.98 |
| England | 23 | 26.1 | 15 | 0,0 % | 874,00 Mill. € | 38,00 Mill. € | 874 | 38 |
| Belgium | 23 | 27.7 | 13 | 95,7 % | 754,00 Mill. € | 32,78 Mill. € | 754 | 32.78 |
| Croatia | 23 | 28 | 5 | 91,3 % | 364,00 Mill. € | 15,83 Mill. € | 364 | 15.83 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
ワールドカップオッズ
前述したとおりサッカーの試合に影響する要因はさまざまありますが、ワールドカップオッズを利用するとサッカー専門家の予測を含めた全体の動向を情報として利用できるかもしれません。そこで、こちらのサイトで取得できるワールドカップオッズを2つ目のデータセットとしました。
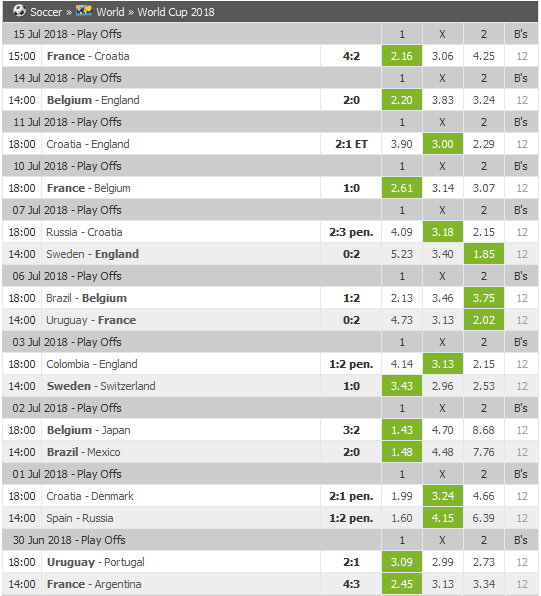
このデータには、試合前に算出されたオッズと試合結果があり、試合結果については、勝ち/負け/引き分けの3パターンがあります。
「ワールドカップオッズデータの一部」
| team1 | team2 | 1 | X | 2 | team1_result | team2result2 | result_ref | win |
|---|---|---|---|---|---|---|---|---|
| Croatia | England | 3.91 | 3.01 | 2.29 | 2 | 1 | ET | 3 |
| France | Belgium | 2.61 | 3.14 | 3.07 | 1 | 0 | FALSE | 3 |
| Russia | Croatia | 4.09 | 3.18 | 2.15 | 2 | 3 | pen | 0 |
| Sweden | England | 5.23 | 3.4 | 1.85 | 0 | 2 | FALSE | 0 |
| Brazil | Belgium | 2.13 | 3.46 | 3.75 | 1 | 2 | FALSE | 0 |
| Uruguay | France | 4.73 | 3.13 | 2.02 | 0 | 2 | FALSE | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
このように作成した2つのデータセットですが、2002年以前のデータはないため、今回は2006年から2018年までのワールドカップの試合結果と当時のチームデータを利用しました。
データの前処理
予測を行うためにデータの前処理が必要です。この前処理では2つのデータセットを1つに結合します。具体的にoddsワールドカップオッズデータに対戦チームそれぞれのチーム名をキーとして、infoチーム情報データ(市場価値総額など)から条件に合うデータを結合します。
odds = pd.merge(odds, info, on=['tag'], how='left')
結合したデータセットは下記のようになります。
| index | 1 | X | 2 | squadteam1 | ageteam1 | rmvteam1 | remvteam1 | squadteam2 | ageteam2 | rmvteam2 | remvteam2 | win |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| .. | ... | ... | ... | ... | ... | ..... | ... | .. | ... | ... | ... | ... |
| 19 | 1.6 | 3.69 | 7.59 | 23 | 27.3 | 218.1 | 9.48 | 23 | 29.9 | 40 | 1.74 | 1 |
| 20 | 2.21 | 3.4 | 3.59 | 21 | 28.6 | 152.3 | 7.25 | 23 | 28.3 | 119.75 | 5.21 | 0 |
| 21 | 19.39 | 8.39 | 1.17 | 23 | 27.9 | 87.53 | 3.81 | 23 | 27.2 | 883 | 38.39 | 3 |
| 22 | 4.44 | 3.99 | 1.82 | 21 | 28 | 76.75 | 3.65 | 23 | 28 | 364 | 15.83 | 0 |
| 23 | 5.98 | 5.27 | 1.5 | 23 | 26 | 134.85 | 5.86 | 21 | 29.3 | 679 | 32.33 | 0 |
| 24 | 2.93 | 3.54 | 2.48 | 23 | 28.2 | 50.25 | 2.18 | 23 | 27.5 | 38.53 | 1.68 | 0 |
| .. | ... | ... | ... | ... | ... | ..... | ... | .. | ... | ... | ... | ... |
また、各特徴のばらつきを減らすために、学習を行う前にデータの標準化を行いました。今回はPythonのオープンソース機械学習ライブラリであるScikit-learnにあるStandardScalarを用いて、平均0、分散1に変換しました。
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train = scaler.fit_transform(X_train) #訓練用データの標準化 X_test = scaler.transform(X_test) #テスト用データの標準化
モデル作成
機械学習にはたくさんの手法があります。今回は教師データあり、試合の結果を、勝ち/負け/引き分けの3パターンのいずれかに予測する分類問題となるため、サポートベクターマシン(supportvector machine, SVM)を利用しました。
SVMは代表的な教師あり学習を用いるパターン認識アルゴリズムの1つであり、分類問題の他、回帰問題でも用いることができます。標準化でも用いたScikit-learnのSVM関数を利用して学習することができます。
from sklearn import svm # SVM
from sklearn.model_selection import GridSearchCV
# 探索するパラメータ
tuned_parameters = [{'kernel': ['rbf'], 'gamma': [1e-3, 1e-4], 'C': [1, 10, 100, 1000]},
{'kernel': ['linear'], 'C': [1, 10, 100, 1000]}]
svc = svm.SVC()
# グリッドサーチの設定
classifier = GridSearchCV(svc, tuned_parameters, n_jobs = -1)
# 最適なパラメータを検索しながら、訓練を行う
classifier.fit(X_train, y_train.values.ravel())
上記のコード例ではGridSearchという関数を使い、SVMのハイパーパラメータの探索を行いました。これはSVMを使うために設定する必要があるパラメータを逐次的に試して、最適なパラメータを得る手法です。
次に、最適なパラメータで学習を行い得られたモデルを用いて、テストデータに適用し予測を行います。
y_pred = classifier.predict(X_test)
決勝トーナメントの各試合の結果を次のように予測することができました。
| team1 | team2 | team1 実際 | team1 予測 |
|---|---|---|---|
| France | Croatia | 未知 | 勝 |
| Croatia | England | 勝 | 負 |
| France | Belgium | 勝 | 負 |
| Russia | Croatia | 負 | 負 |
| Sweden | England | 負 | 負 |
| Brazil | Belgium | 負 | 負 |
| Uruguay | France | 負 | 負 |
| Colombia | England | 負 | 負 |
| Sweden | Switzerland | 勝 | 負 |
| Belgium | Japan | 勝 | 勝 |
| Brazil | Mexico | 勝 | 勝 |
| Croatia | Denmark | 勝 | 勝 |
| Spain | Russia | 負 | 勝 |
| Uruguay | Portugal | 勝 | 負 |
| France | Argentina | 勝 | 負 |
今回のロシアW杯の優勝をフランスと予測しました。ベスト16から準決勝までの結果として、クロアチアやロシアなどあまり期待されてなかったチームが勝利を重ねており、いくつかのケースで誤った予測となりました。今後、試合のリアルタイムの状況や選手のモチベーションなどのさらなる情報の追加、訓練データの追加による精度向上ができるのではないかと考えられます。
まとめ
今回の記事は、ロシアW杯でどの国が優勝するかを機械学習を用いて予測しました。
結果、フランスが優勝すると予測しましたが、実況中継で観戦しながら、まさにそのフランス優勝が決まったときには、驚きとともに大変うれしく感じました!