



トレンド
【Part1 基調講演編】NVIDIA GTC2025 現地参加レポート
2025.04.07

GPUセールス&マーケティング担当
亀谷 淑恵

2025年7月追記
NTTPCのポッドキャスト「hello.pc」でも、GTC2025現地参加レポートを公開しました!ぜひお聞きください。
#43_NVIDIA GTC 2025 現地レポート 「サンノゼのお祭りはどうでした??」(前編)
みなさんこんにちは。NTTPCの亀谷です。
2025年3月17日~21日(現地時間)に米国カリフォルニア州サンノゼで開催された「GTC2025」に参加しました!GTC(GPU Technology Conference)は、NVIDIAが毎年主催している世界的なAIカンファレンスです。
「Technology」とついてはいるものの、技術者向け情報発信のみならず、さまざまな産業界のビジネスリーダーによる事例紹介や、スタートアップによるピッチ、参加者同士のMeetupなど、現地で体験できるイベントは多岐にわたります。まさにAIの今後をうらなうイベントといえるでしょう。
今回は、NVIDIA CEOによる基調講演のほか、1,100以上のトークセッション・パネルディスカッション・ワークショップ等のセミナーが開催され、400社超が展示ブースを出展、170以上の研究ポスター展示が行われます。全世界から約2.8万人がサンノゼに集まり、日本からも600名以上が参加エントリーしているとのこと!5日間通してのカンファレンス パスは完売御礼となりました。
さらに今回はGTC初の試みとして、「Quantum Day」も行われます。世界中の量子コンピューティング業界のリーダーたちがNVIDIA CEOとのパネル ディスカッションに参加し、今後数十年間で企業が量子コンピューティングに期待することや、量子技術の実用化に向けた道筋が明らかにされるということで注目が集まっています。
GTCの一部セッションはアーカイブ配信されていますので、ぜひ下記URLよりご覧ください。
GTC公式サイト:https://www.nvidia.com/ja-jp/gtc/
私は2024年に続いて2回目の参加です。すでに多くのメディアやブログがGTC2025での発表内容を報じていますが、昨年参加時との比較や、現地で特に盛り上がりを見せていたセッション、日本のみなさまに特に関係しそうなコンテンツなど、私が注目したポイントを抜粋してお届けします。
5日間の長いイベントのため、Part1~3までの3部に分けて掲載する予定です。
Part1:基調講演編
Part2:基調講演以外の注目セッションの模様
Part3:会場内で注目を集めていた展示ブース
【目次】
1. 現地の雰囲気
メイン会場は今年もサンノゼのMcEnery Convention Centerですが、昨年とは異なり付近一帯が歩行者天国となっていました。来場者の往来や自動運転車の試走、ランチ会場のために提供されており、GTCパスを持っていれば自由に移動できます。

メイン会場であるMcEnery Convention Centerには今年も大きなゲートが(NTTPC社員撮影)

GTCパス(参加バッチ)
自由に移動はできるものの、建物内に入る際には毎回金属探知ゲートでのセキュリティチェックを通過する必要があります。警備員も多数配置され、さらに検疫探知犬と思われる犬たちも常時待機するなど、開かれたイベントではありつつも安全に配慮して開催されています。

入場ゲートで来場者をチェックする犬 休憩中の様子です(NTTPC社員撮影)
私たちは会場から6kmほど離れたホテルに宿泊していましたが、宿泊客はGTCパスを下げた方ばかり。会場周辺のホテルは満室のようなので、次回参加を考えている方は早めに予約したほうがよさそうです。
2. 基調講演
3月18日10時(現地時間)より、NVIDIA 創業者/CEO の Jensen Huang(ジェンスン フアン) 氏による基調講演 が行われました。GTCのメインイベントであり、AIに関連するあらゆる人々がHuang氏の一挙手一投足に注目する講演です。
今年もメイン会場から少し離れたSAP Center(12,000人収容)での開催。開演2時間前から入場を受け付けていたものの、会場周辺には長蛇の列ができていました。私たちは1時間半前に会場に到着し、なんとか2階席に座ることができました。

基調講演会場 2階席からのビュー(NTTPC社員撮影)
まるでアーティストのライブのような光の演出とオープニングムービーが流れたのち、歓声とともにHuang氏が入場します。Huang氏自身が「this year it's described as the Super Bowl of AI. (今年はAIのスーパーボウルと言われている)」と述べたようにド派手な演出です。

Huang氏が登場(NTTPC社員撮影)
2.1 AIの進化を後押しするBlackwellアーキテクチャ
冒頭では、この10年間のAIの進化の過程を振り返りました。単に画像や音声の認識を行うだけの知覚AIから、文脈を理解し応答を生成する能力を持った生成AI、そしてここ2~3年のブレイクスルーにより、自律的に思考・動作する「エージェントAI」に発展を遂げています。さらには物理法則を理解し、ロボットや車両などのデバイスと協調する「フィジカルAI」の実現も視野に入ってきました。
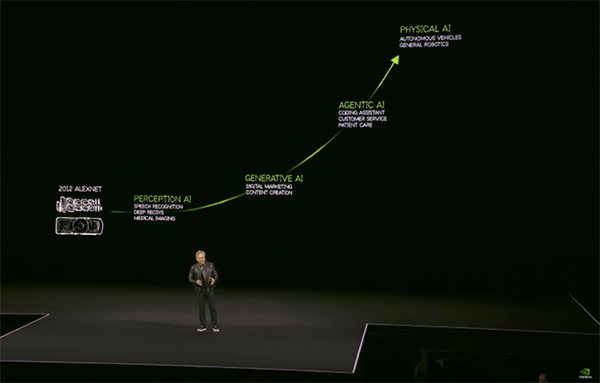
2012年のALEXNET登場からこれまで(YouTubeより)
また、NVIDIAによる包括的な技術スタックについても改めて述べられます。CUDA®と各業種向けの専門ライブラリが紹介されました。いまや200以上の国で600万人を超える開発者がCUDAを利用し、900以上のCUDA-XライブラリとAIモデルが利用可能であることを強調しました。「This slide is genuinely my favorite(このスライドは本当に気に入っている)」という言葉通り、CUDAの各ライブラリについて、まるでつい先ほど自分自身の手で生み出したかのように熱く語る姿に、創業者として自社の発展に尽力してきたことへの想いがうかがえました。

各業界向けのCUDAライブラリ(YouTubeより)
人間が扱えるデータや検証できる範囲には限界があるため、明確な回答があるタスクでは、AIは「強化学習」という手法を用いて精度を向上させています。モデルが生成した問答に対して、正しい回答をした場合には報酬を与えることで徐々に最適化していく手法です。膨大な量の試行を通じてトークンが生成され、最終的には兆単位のトークンが必要となります。これまでは人間がソフトウェアを作成し、それをコンピュータ上で実行していましたが、強化学習ではコンピュータがモデル訓練のためのトークンを自ら生成する存在になるのです。
コンピューティングの在り方が変わるこの状況を、Huang氏は「AIファクトリー」と呼びます。大量のトークンを生成し、それを音楽や言葉、ビデオ、化学物質やタンパク質に再構成することでAIの精度が上げる営みが進んでいます。
このようにAIが高精度化・多角化するにあたって必要な計算能力は、従来想定されていた量の100倍になるとも言われています。計算要件が劇的に増加する世界に対応するため、新世代のGPUアーキテクチャ「Blackwell」が本格的な生産体制に入ることが発表されました。Blackwellを導入することで、前世代のHopper™と比べ、ユーザーはエネルギー効率とラック収容率を約30%削減できることを示しました。
Blackwellアーキテクチャの中でもとりわけ強調されていたプロダクトは、水冷式ラックソリューションの「NVIDIA GB200 NVL72」です。NVIDIAリファレンスアーキテクチャとして、各ハードウェアメーカーより提供されるもので、会場にはずらりと各メーカーのラックが並びます。シャーシ中央にラッキングされたNVLink™ Switchを通して、GB200が搭載されたコンピュートノードが相互接続されています。

各メーカーのGB200 NVL72(YouTubeより)
2.2 今後のGPU開発ロードマップ
さらに、今後2~3年間のGPU開発ロードマップも示されます。まず2025年度下期より登場予定の「Blackwell Ultra(B300)」が公開されました。B300はSXMモジュールやBGAとして展開され、ポケットサイズでの高密度実装が可能です。B200に比べFP4性能が50%以上向上し、メモリは288GB HBM3e、最新のConnect🄬-X 8 NIVを搭載し、合計800GBのInfiniBand通信を実現します。
GB200 NVL72と比較すると、「Blackwell Ultra NVL72」は1.5倍の性能を実現し、1.1ExaFLOPSのFP4推論性能を発揮できることが明らかになりました。

Blackwell Ultra NVL72(YouTubeより)
ダークマターを発見した天文学者の名を冠する「Vera Rubin」も発表されました。(ちなみに、会場にはVera Rubin氏の孫も来場していたようです)
Vera CPUはTSMCの3nmプロセスで、2つのレチクルサイズの計算用ダイと2つのI/Oタイルを搭載。前世代のGrace CPUと比べ2倍の性能を発揮します。HBM4メモリへ移行することで、13TB/sに帯域幅を拡張しながらも、消費電力は小さく抑えられています。
RubinアーキテクチャGPUは、新しいネットワーク規格Connect-X🄬 9や、第6世代NVLink、HBM4メモリに対応します。Blackwellの前例と同じく、Rubinも1つのGPUパッケージに2つの計算用ダイが組み込まれるということです。
Rubin UltraはGPUダイを4基配置し、計算性能はなんと100 PFLOPsに達するとのこと!従来比で3.5倍となる1024GBのメモリ容量を実現し、これまで複数GPUを接続してメモリを確保していたようなワークロードでも1GPUで完結することができます。
このVera Rubinを計72基(=144ダイ)搭載した「Vera Rubin NVL144」と、さらにそれを拡張した「Rubin Ultra NVL576」が発表されました。Rubin Ultra NVL576は2027年度の後半にリリースされ、15ExaFLOPSの演算性能を持つということが発表された瞬間、会場は驚きの声に包まれました。今後の詳報が楽しみですね!

Rubin Ultra NVL576(YouTubeより)
Rubin以降も、年に1回のペースで新型GPUを開発していく方針が打ち出されました。
また、2028年には「Feynman」アーキテクチャの開発を予定しているというロードマップも公開されました。
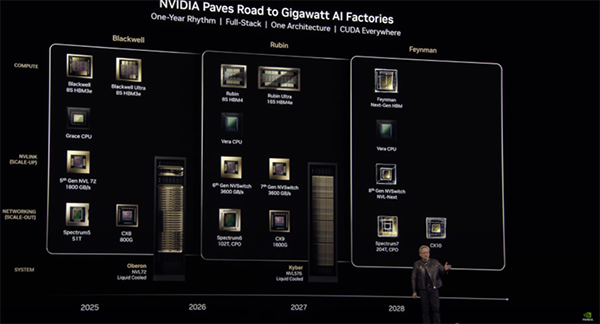
今後の開発ロードマップ(YouTubeより)
2.3 光伝送技術の実装:シリコンフォトニクス
さらなるスケールアウトを実現するためには、各ノードを高速かつ低遅延に接続するネットワークが欠かせません。続けてHuang氏は、NVIDIAのネットワーキング技術の進展を紹介しました。
現在主にネットワーク伝送に利用されている銅(電気信号)は、非常に優れた接続性、高い信頼性、優れたエネルギー効率、低コストを満たすとても良い技術ではありますが、今後さらに長距離間での高速通信を求める場合は、「シリコンフォトニクス」が重要な役割を果たすでしょう。
シリコンフォトニクスとは、シリコン半導体の製造技術を用いてシリコンウエハ上に大規模な光の回路、すなわちフォトニクス回路を構築する技術です。従来の電気信号と比較して、高速・大容量かつ低消費電力な伝送が可能になります。データセンターの需要が急激に増えている昨今、期待が高まっている分野です。
本講演ではNVIDIAが初めて開発したシリコンフォトニクスシステム「NVIDIA Photonics」が公開されました。TSMCと長年取り組んできた研究とのことです。このNICを利用することで、最大通信速度は現行の800Gb/sから1.6T/sへ大幅に向上します。

NVIDIA Photonics(YouTubeより)
Huang氏自らケーブルの束を持ち、繰り返しアピールしていたのが省電力性です。NVIDIA Photonicsの実装により、各GPUが複数のインターフェースを持ち、トランシーバーを使わずに直接光ファイバーでスイッチに接続する構成となり、その分の消費電力を大幅に削減できます。Quantum-Xには2025年後半から、Spectrum-Xには2026年後半から採用されるということでした。

光ケーブルを手に語るHuang氏(YouTubeより)
2.4 自動運転AI実現のためのパートナーシップ
AIをさらに拡大していくためには、NVIDIAだけではなく幅広いパートナーとの提携が欠かせません。すでにテスラやWaymoはデータセンターと車両の双方にNVIDIA GPUを導入しています。講演では、GMがNVIDIAソフトウェアスタックを採用し、自動運転車の開発に役立てるプロジェクトが発表されました。
これに関連して、自動運転の安全性の確保するためのパッケージ「NVIDIA Halos」もリリースされました。NVIDIA Omniverse™とNVIDIA Cosmos™と組み合わせることで、3D合成データを生成し、物理演算に基づくデジタルツイン上でのシミュレーションを行い、自動運転車が複雑な走行シナリオを確実にこなすデモが上映されました。
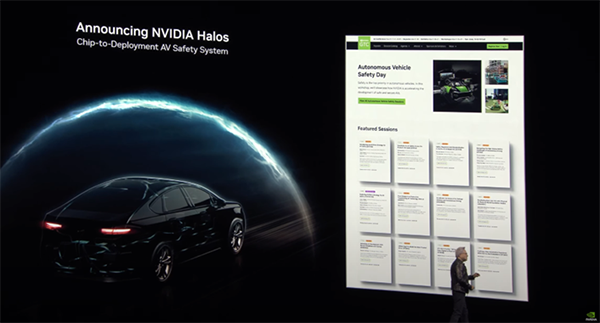
NVIDIA Halos(YouTubeより)
2.5 エッジ向けAIワークステーション「DGX Spark」と「DGX Station」
また、NVIDIA DGX™ Systemsの新モデルが気になっている方も多いのではないでしょうか?今回の講演では、エッジ向けにAI機能を提供するために設計された新しい「DGX Spark」(これまでは”Project DIGITS”と呼称されていました)と「DGX Station」がお披露目されました。
DGX SparkはGB10 Grace Blackwell Superchipを備えた手のひらサイズのコンピュータです。ごく省サイズであるにもかかわらず、FP4精度の計算で1PFLOPSを達成していることが驚きのポイントです。他のBlackwell世代マシンは大規模で高価格帯のラインナップが多く、小規模なオフィス、研究室などではなかなか導入が難しいと思われていた方も多いかもしれませんが、そんな方にもぴったりの製品です。

DGX Spark(YouTubeより)
どうやら2台セットでの利用が推奨されているようで、接続ケーブルがセットになったモデルもNVIDIAや各OEMメーカーから販売されるということでした。GTC期間中からさっそく予約受付を開始しており、価格は$2,999~と発表されましたが、残念ながら日本での予約・出荷開始はもう少し先になりそうです。
次にお目見えした「DGX Station」は、GB300を1基搭載した内部液冷式のワークステーションです。過去に販売されていた「DGX Station」や「DGX Station A100」と同じく、デスクサイドでの利用を想定して設計されたマシンです。

DGX Station(YouTubeより)
最大 800 Gb/s のNVIDIA ConnectX®-8 SuperNICと、描画用GPUを搭載するためのPCIeスロットも備えています。DGX OSと、Run:AI を含むNVIDIA® CUDA X-AI™ プラットフォームもサポートするようです。1台あたりの消費電力は1,500Wということなので、おそらく100V電源ケーブル1本で電力供給できるものと思われます。2025年中にHP、Dell、Lenovo、ASUSなどのメーカーが販売開始する予定です。
詳しい仕様は今後発表ということですが、展示ブースにて実物を見学できましたので、次の記事でも紹介します。
DGX SparkとDGX Stationは、NVIDIA Blackwell GPUのリソースを手元で利用したいという方に非常に使いやすい仕様となっており大注目です!「This is what a PC should look like(PCはこうあるべきだ)」という言葉に深くうなずきました。年々高集積化・大型化が進む昨今のGPU市場において、今回の基調講演ではこれらのワークステーション型製品も発表されたことについて、本気でAIの民主化を実現しようというNVIDIAからのメッセージだと受け取りました。
2.6 フィジカルAIを具現化するロボティクスへの取り組み
ここまでの盛りだくさんな発表で、予定講演時間の2時間はすでにオーバーしていましたが、最後にHuang氏はNVIDIAのロボティクスへの取り組みを発表しました。
現実世界に即して動作するロボットの訓練には、多種多様な合成データが必要になります。実世界のデータを集め、そのデータを拡張してフォトリアルに再現するためにはNVIDIA OmniverseとCosmosが役に立つでしょう。Isaac™ Labを使えば、ロボットが模倣学習により人間の行動をコピーしたり、AIからのフィードバックを受けながら強化学習を行うことも容易です。
さらに、今回新たに打ち出された人型ロボット用の汎用基盤モデル「Isaac GR00T N1」を活用することで、人間の認知処理の原則に基づき、ロボットは自分の周囲や指示を理解し、推論し、適切な行動を計画したり、他のロボットとの共同作業を実行できるようになります。なんとこのGR00Tはオープンソースで提供されるとあって、会場内は驚きに包まれていました。
DeepMind、Disney Research、NVIDIAの3社パートナーシップによる、ロボット開発のためのより高精度な物理エンジン「Newton」もリリースされました。どちらかというとNewtonそのものよりも、Newtonを用いてDisney Researchが開発した小さなロボット「Blue」が人々の記憶に残ったのではないでしょうか。愛らしい仕草で登壇し、リアルタイムにHuang氏とかけあうBlueは、人とともに過ごすパートナーロボットとして理想的な姿を見せてくれました。また、フィジカルAIが普及した近未来での具体的なシーンを想起させるものでもありました。

Blueも壇上に(YouTubeより)
2時間超にわたる講演のため、一部内容を省略したり順序を入れ替えてご紹介しました。Huang氏の実際の熱量や時折挟むジョークも知りたい方は、ぜひ下記Webサイトより実際の講演内容をご聴講ください。日本語字幕もあります。
GTC March 2025 Keynote with NVIDIA CEO Jensen Huang
Part2記事では、基調講演以外の注目セッションの模様を紹介します。
【Part2 セッション編】NVIDIA GTC2025 現地参加レポート