



性能検証
Tesla® P100の性能ベンチマーク
2018.03.30

サービスクリエーション本部
GPUアーキテクト
山崎 智行

GPUの性能をベンチマークするソフトウェアは数多くありますが、深層学習で使われる行列計算の能力において、果たしてどれくらいの性能がでるのか検証してみました。
<構成>
サーバー :Supermicro SYS-4028GR-TRT2
OS :Ubuntu 16.04 LTS
GPU :NVIDIA® Tesla® P100 12GB ( PCIeベース ) x 4
CUDA :NVIDIA® CUDA® 9.1
今回は、データセンターアクセラレータのデファクトとなっているTesla® P100を検証してみたいと思います。その公式スペック における演算性能をみると、単精度:9.3TFlops、倍精度:4.7 TFlopsとあります。では、実際にその性能を検証してみましょう。
<ベンチマーク方法>
CUDA®をインストールするといくつかサンプルがついてきます。 ( 例: /usr/local/cuda-X.X/samples )
この中の「0_Simple」ディレクトリ配下に「matrixMulCUBLAS」があり、これが行列計算をしていますのでちょっと改造して性能を測っていきます。なお、「matrixMulCUBLAS」のソースを確認するとcublasSgemm関数を呼んでいるので単精度浮動小数点行列演算をしています。
NVIDIA®のCUBLASはBLAS ( Basic Liner Algrebra Subprogram ) のCUDA版の実装で、BLASとはウィキペディアによると「ベクトルと行列に関する基本線型代数操作を実行するライブラリAPIのデファクトスタンダード」ということです。今回のベンチマークはこれで十分でしょう。
/usr/local/cuda-9.1/sample配下でmakeするとサンプルプログラムがコンパイルされていきます。
yama3@GPU101:/usr/local/cuda-9.1/samples$ sudo make make[1]: Entering directory '/usr/local/cuda-9.1/samples/0_Simple/matrixMulDrv' make[1]: Nothing to be done for 'all'. make[1]: Leaving directory '/usr/local/cuda-9.1/samples/0_Simple/matrixMulDrv' make[1]: Entering directory '/usr/local/cuda-9.1/samples/0_Simple/clock' make[1]: Nothing to be done for 'all'. make[1]: Leaving directory '/usr/local/cuda-9.1/samples/0_Simple/clock' make[1]: Entering directory '/usr/local/cuda-9.1/samples/0_Simple/simpleLayeredTexture' make[1]: Nothing to be done for 'all'. make[1]: Leaving directory '/usr/local/cuda-9.1/samples/0_Simple/simpleLayeredTexture' make[1]: Entering directory '/usr/local/cuda-9.1/samples/0_Simple/matrixMulCUBLAS' make[1]: Nothing to be done for 'all'. make[1]: Leaving directory '/usr/local/cuda-9.1/samples/0_Simple/matrixMulCUBLAS' make[1]: Entering directory '/usr/local/cuda-9.1/samples/0_Simple/systemWideAtomics' make[1]: Nothing to be done for 'all'. make[1]: Leaving directory '/usr/local/cuda-9.1/samples/0_Simple/systemWideAtomics' make[1]: Entering directory '/usr/local/cuda-9.1/samples/0_Simple/inlinePTX_nvrtc' make[1]: Nothing to be done for 'all'. ..... (以下すべてのディレクトリを再帰的にコンパイルしていく)
これでもいいのですが、すべてのサンプルは必要ないので 0_Simple/matrixMulCUBLAS とcommonをホームディレクトリにコピーして進めていきます。
yama3@GPU101:~$ cp -R /usr/local/cuda-9.1/samples/0_Simple/matrixMulCUBLAS/ . yama3@GPU101:~$ cp -R /usr/local/cuda-9.1/samples/common matrixMulCUBLAS
MakefileのCUDAパスの確認と、commonディレクトリのインクルードパスの修正をしてコンパイルします。
Makefile CUDA_PATH ?= /usr/local/cuda-9.1 ← CUDAのパスを確認 INCLUDES := -I../../common/inc ← ここを修正 INCLUDES := -I./common/inc yama3@GPU101:~$ make ...
できたmatrixMulCUBLASの実行形式を実行してみます。
yama3@GPU101:~$ ./matrixMulCUBLAS [Matrix Multiply CUBLAS] - Starting... GPU Device 0: "Tesla P100-PCIE-12GB" with compute capability 6.0 GPU Device 0: "Tesla P100-PCIE-12GB" with compute capability 6.0 MatrixA(640,480), MatrixB(480,320), MatrixC(640,320) Computing result using CUBLAS...done. Performance= 4079.05 GFlop/s, Time= 0.048 msec, Size= 196608000 Ops Computing result using host CPU...done. Comparing CUBLAS Matrix Multiply with CPU results: PASS NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
「Performace」のところを見ると4TFlopsしか出ていません。しかし時間は0.048 msしか実行していないので計算量が少ないようです。
matrixMulCUBLAS.cppのint matrixMultiply()とvoid initializeCUDAのint block_sizeを大きくします。あまり大きすぎると時間がかかりすぎますので1024くらいにします。
matrixMulCUBLAS.cpp
(中略)
#define BLOCK_SIZE 1024 ←追加
(中略)
void initializeCUDA(int argc, char **argv, int &devID, int &iSizeMultiple, sMatrixSize &matrix_size)
{
(中略)
int block_size = BLOCK_SIZE; ←変更
// int block_size = 32;
matrix_size.uiWA = 3 * block_size * iSizeMultiple;
matrix_size.uiHA = 4 * block_size * iSizeMultiple;
matrix_size.uiWB = 2 * block_size * iSizeMultiple;
matrix_size.uiHB = 3 * block_size * iSizeMultiple;
matrix_size.uiWC = 2 * block_size * iSizeMultiple;
matrix_size.uiHC = 4 * block_size * iSizeMultiple;
(中略)
int matrixMultiply(int argc, char **argv, int devID, sMatrixSize &matrix_size)
{
cudaDeviceProp deviceProp;
checkCudaErrors(cudaGetDeviceProperties(&deviceProp, devID));
int block_size = BLOCK_SIZE; ←変更
// int block_size = 32;
// set seed for rand()
srand(2006);
(以下略)
変更後に再びコンパイルして実行します。
yama3@GPU101:~$ ./matrixMulCUBLAS [Matrix Multiply CUBLAS] - Starting... GPU Device 0: "Tesla P100-PCIE-12GB" with compute capability 6.0 GPU Device 0: "Tesla P100-PCIE-12GB" with compute capability 6.0 MatrixA(20480,15360), MatrixB(15360,10240), MatrixC(20480,10240) Computing result using CUBLAS...done. Performance= 9150.93 GFlop/s, Time= 704.022 msec, Size= 6442450944000 Ops NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
「Performance= 9150.93 GFlop/s」9.1TFlopsは出ています。block_sizeをもっと大きくしても、これ以上の性能はあがらないようです。もちろん、このプログラムの実行の最後に、
「NOTE: The CUDA Samples are not meant for performance measurements.
Results may vary when GPU Boost is enabled.」
とあるのであくまで参考値とすべきですが、ほぼカタログスペック通りですね。
なお、今回のサーバーはGPUカードを4枚実装していますが、matrixMulCUBLASは引数を与えないと最初のカード、つまりdeviceID 0のカードに対してのみ実行してしまいます。GPUカードを指定するには 引数に device=X ( Xにカード番号 ) を与えます。
このようにして4枚すべてで10回づつ確認してみました。
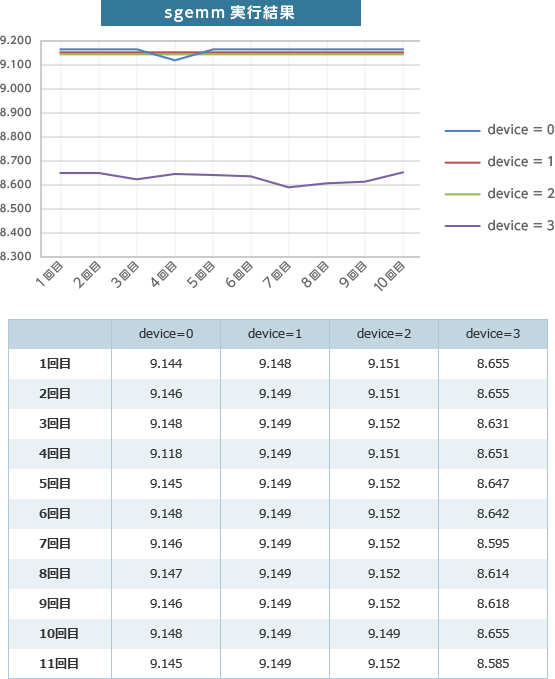
device=3 だけ8.6TFlopsしか出てないですね。同じプログラムですが、カードのスロットを変えても同じ結果になりました。
以前、GPUサーバーを導入いただいたお客さまから、GPUカードによって稀に性能差がでることがあるという話を聞いたことがあります。このカードが当たり?だったのかもしれません。なお、この程度の性能差だと交換対象にはならないようです。
次回は、NVIDIA最新の次世代アーキテクチャであるNVIDIA® Volta™を実装した、Tesla® V100のベンチマークを行ってみたいと思います。