



技術解説
最近よく聞く「MoE」とは?GPT-OSSにも採用された注目技術を調べてみた
2025.10.01

GPUエンジニア
塩田 晃弘

GPUエンジニア
小野 雅也
1. 本コラムの目的
はじめまして、NTTPCコミュニケーションズ1年目社員の塩田・小野です。普段はGPUクラスタの構築やRAG ChatBotの検証業務に取り組んでいます。
このコラムでは、GPT-OSS や Qwen3-Coder などのLLMで採用され、最近話題となっている注目技術「Mixture of Experts(MoE)」について解説します。従来の Transformer と MoE を採用した Transformer の違いや、MoE が複数の専門家ネットワークを活用して推論処理を行う仕組みについて紹介します。
さらに、MoE モデルを比較的小規模な GPU 環境で効率的に動作させるための最適化設定を探る検証も実施しました。
MoEモデルの採用をお考えの方へ、検討の一助になる情報をお届けできれば幸いです。
2. 背景 - なぜMoEが注目されているのか
近年、より高性能なLLMの開発を目的として、学習に用いるデータセットはますます大規模かつ多様化しています。それに伴い、AIモデルのパラメータ数も増加しているため、計算資源となるGPUリソースの確保や最適化がこれまで以上に重要となっています。
こうした背景の中で、計算効率とモデル性能の両立を可能にする手法として、「MoE(Mixture of Experts)」が注目を集めています。
MoE とは、複数の専門家(エキスパート)ネットワークの中から、タスクに応じて最適なものを選択して使用することで、LLMが効率的な推論を実現する仕組みです。多数の専門的なサブネットワーク(エキスパート)の中から、入力に応じて必要なものだけを選択的に活性化する構造を持っています。
この仕組みにより、モデル全体としては膨大なパラメータを保持しつつも、推論時には限られたエキスパートのみが使用されるため、計算コストを抑えながら高い表現力が維持されます。今後、MoE は効率性と表現力の両立を実現する技術として、AI活用において重要な役割を果たすと考えられます。
3. 基本概念をおさらい
ここで、MoEで利用されている基本的な概念・技術をおさらいしておきましょう。
3.1 Transformer
Transformer は、LLM の基礎として採用されてきたニューラルネットワークモデルです。入力された文章(トークン系列)を、 2つの異なる機能を持つブロック(AttentionとFFN)で繰り返し処理することで、高度な文脈理解と応答生成を可能にします。
3.2 Attention
Attention は、「自己注意 (Self-Attention)」という機構を用いて、単語間の関連性を見つけ出す計算工程です。この計算では、ベクトル化された Query (Q), Key (K), Value (V) の 3つの行列を用いて各単語間の関連度を算出し、それに基づいた重み付けが行われます。
3.3 Feed Forward Network (FFN)
FFN(Feed Forward Network)は、Transformer モデルにおいて、Attention で得た文脈情報をさらに抽象化し、表現力を高める役割を担います。高次元への線形変換と非線形変換を経て、情報の抽象度を向上させた後、再び低次元に圧縮することで、効率的かつ豊かな特徴表現を実現します。
通常の Transformer モデルでは、単一の FFN を使用するアーキテクチャが採用されていましたが、MoE では複数の FFN を用いることでモデルの表現力を高めています。
4. MoEの仕組み
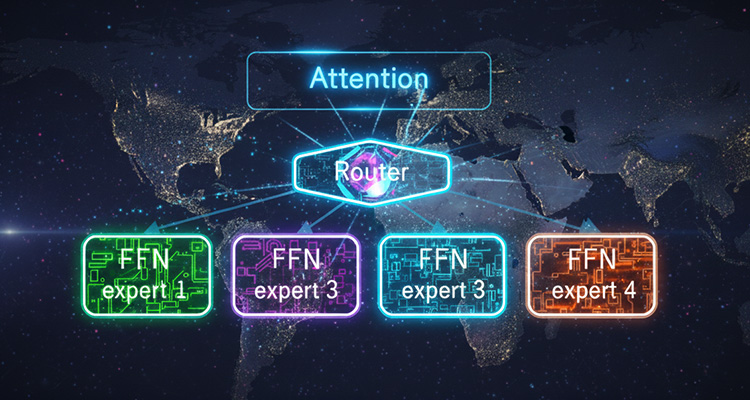
MoE モデルでは、複数の専門家(エキスパート)ネットワークを入力に応じて動的に切り替える仕組みが導入されています。ここでいう「専門家」とは、Transformer ブロック内に配置された複数の FFNを指します。
図1は、従来の Transformer ブロックと MoE ブロックの構造の違いを示しています。左側が従来の構造、右側がMoEの構造です。
従来はAttention ブロックと FFN が1対1で対応していましたが、MoE では複数の FFN が追加され、その上に Router と呼ばれる経路選択機構が配置されています。
推論時には、Attention の出力が Router に渡され、Router が最適な”専門家”であるFFNを選択します。この仕組みにより、入力に応じた専門家の動的な切り替えが可能となり、モデルの表現力と柔軟性が大幅に向上しています。

図1: 従来の Transformer Block (左) と MoE の Transformer Block (右)
※簡略化のため、Norm 層と Skip connection は省略しています。
5. MoE モデルのパラメータ数
MoE モデルは非常に多くのパラメータを有しますが、トークン1つあたりの生成に使用されるパラメータは、実際にはごく一部です。次の表は、主要な MoE モデルにおける全体のパラメータ数とトークン1つあたりの使用パラメータ数です。
表1 主要な MoE モデルにおける総パラメータ数と使用パラメータ数
| モデル名 | 総パラメータ数 | 1トークンあたりの 使用パラメータ数 |
|---|---|---|
| GPT-OSS:20B | 21B | 3.6B (17.1%) |
| GPT-OSS:120B | 117B | 5.1B (4.4%) |
| Qwen3-Coder 480B | 480B | 35B (7.3%) |
| Qwen3 235B | 235B | 22B (9.4%) |
| Mixtral 8x22B | 141B | 39B (27.7%) |
※2025年9月現在 NTTPCコミュニケーションズ調べ
表1の通り、たとえば GPT-OSS:20B では、全体の 17.1% が 1トークンあたりの生成に使用されており、GPT-OSS:120B のモデルでは、全体のわずか 4.4% しか使用されていません。これは、パラメータのほとんどが専門家ネットワークに集中しており、1トークンあたりの生成時には一部の FFN しか使用されないためです。この仕組みにより、豊富な知識と少ない計算量が両立されています。
しかしながら、これらの MoE モデルはそもそもパラメータ数が非常に多いため、すべてのパラメータを GPU 上に展開するには、大容量の VRAMを持ったGPUが必要となります。例えば、GPT-OSS:120B の 4bit量子化モデルを使用する場合、およそ60GBの VRAM が必要です。VRAM 容量の小さい GPU を使用する場合には、一部のパラメータを CPU にオフロードする必要がありますが、動作速度は低下します。
そうは言っても、さまざまな要因で利用できるGPUが限られていることもあるかと思います。次の章では、GPUのVRAM が不足するケースにおいても、なるべく高速に MoE モデルを動作させるための設定について解説します。
6. CPU と GPU の割り当て最適化実験と評価
VRAM が限られたGPU環境で MoE モデルを効率的に動作させるには、専門家ネットワークの一部を CPU にオフロードする手法が有効です。
前章で述べた通り、膨大なパラメータを持つ専門家のうち、MoE で実際に使用されるのは一部のみです。そのため、頻繁に使われる Router や Attention 層だけを GPU に配置し、専門家ネットワークの大部分を CPU に移すことで、VRAM の節約とスループットの向上が期待できます。
モデルの CPU と GPU の割り当てを制御する場合は、llama.cpp を使用するのがおすすめです。今回は、GPT-OSS:120B を llama.cpp で動作させるコマンドを紹介します。
--n-gpu-layers 37 で、すべての Trasformer ブロックを GPU で動作させます。その後の -ot オプションが、CPUにオフロードする層を指定するオプションです。今回は ffn_gate_exps と ffn_up_exps を CPU にオフロードさせます。
llama-server -hf unsloth/gpt-oss-120b-GGUF:Q4_K_M --n-gpu-layers 37 -ot ".ffn_(gate|up)_exps.=CPU"
比較対象として、CPU と GPU の細かい割り当てを行わない、--n-gpu-layersオプションだけを使う方法も試します。上の手法と VRAM の使用量をそろえるため、--n-gpu-layers 12を設定します。
llama-server -hf unsloth/gpt-oss-120b-GGUF:Q4_K_M --n-gpu-layers 12
2つの条件での計測結果が図2です。-otオプションによって、約 1.3 倍の高速化が実現できることが分かりました。

図2 計測結果(計測条件:1000トークン生成までの実行時間を10回測定し平均を算出)
Qwen3-235B の実験結果
Qwen3 でも同様に、最適化によって約 1.3 倍の高速化の効果がありました。

図3 Qwen3-235Bでの計測結果
7. まとめ
今回は、MoEの概要と高速化検証結果について解説しました。検証結果からは、小規模な GPU 環境において割り当てを最適化することで、VRAM の節約とスループットの向上を実感することができました。
GPT-OSSをはじめ、MoE を採用したオープンな LLM モデルが多数登場しています。MoEを使って表現力を高めたLLM モデルは今後ますます増えると予想されるため、引き続き業界の動向に注目していきたいと思います。