



トレンド
生成AIのパフォーマンスが大幅アップ!?NVIDIA BlackwellアーキテクチャGPUの性能
2025.03.05

GPUエンジニア

2025年9月11日:表1. BlackwellとHopperのGPU比較を更新しました。
大規模言語モデル(LLM)開発が盛んになり、AIモデルのトレーニング/推論を加速させる次世代GPUの開発競争も激しくなっている中、2024年3月18日~22日にカリフォルニア州サンノゼで開催されたイベント「NVIDIA GTC 2024」で、同社のジェンスン・フアンCEO自ら生成AIの学習や推論に最適な次世代の高性能GPUアーキテクチャ「NVIDIA Blackwell」(以下Blackwell)を発表しました。
本記事では、生成AIのパフォーマンスを飛躍的に向上させるBlackwellについて、その特長や性能、ラインナップ、今後の展開について紹介します。
NVIDIAの次世代GPUアーキテクチャ「Blackwell」を採用したB200とは
Blackwellは、NVIDIA H100 Tensor コア GPUやNVIDIA H200 Tensor コア GPUのベースになっている「NVIDIA Hopper」(以下Hopper)世代の後継にあたり、性能が大幅に向上しています。特に、大規模なデータ処理や複雑なAIモデルのトレーニングなどにおいて優れた性能を発揮します。
ちなみに、Blackwellという名前は、ゲーム理論や統計学を研究した数学者の故デビッド・ブラックウェル氏に由来するそうです。
生成AIの高速化に焦点を当てたBlackwellには最高レベルの技術と叡智が盛り込まれています。内部アーキテクチャ、半導体パッケージング、インターコネクトなど、それぞれが先端テクノロジーの塊と言えるでしょう。
半導体の視点で見ると、レチクル(フォトマスクの一種)の上限サイズで製造した2個のダイを、8個のHBM3eメモリ・ダイとともに、ファウンドリであるTSMCのCoWoS(Chip on Wafer on Substrate)という3Dパッケージング技術を使ってひとつのパッケージに統合し、実質的に巨大なチップを構成しています(図1)。
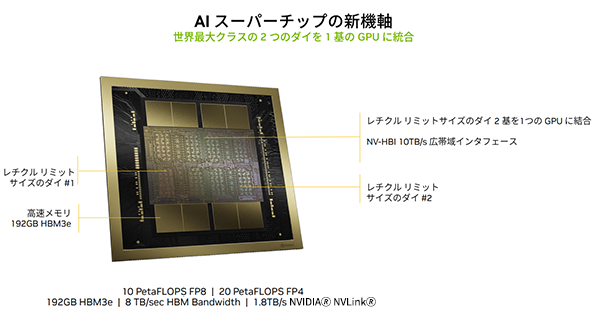
図1. NVIDIA B200の構造。総トランジスタ数は2,080億個
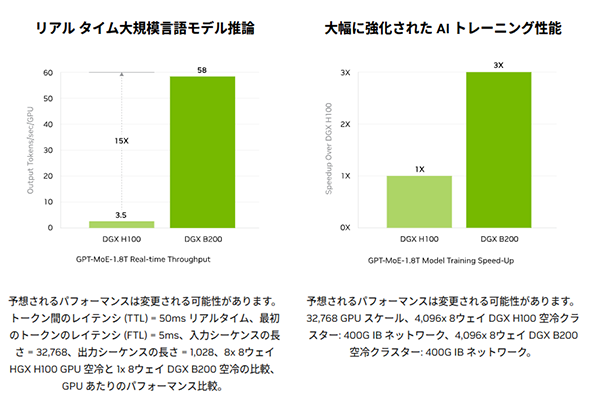
では、具体的にはどのぐらいの性能が得られるのでしょうか。NVIDIAはBlackwell B200の性能について、「GPT-MoE 1.8T」という1.8兆パラメーターのLLMにおいて、H100に対して学習性能で3倍、リアルタイム推論で15倍の性能向上が得られると発表しています(図2)。
また、LLM推論処理に必要なエネルギー効率は、Hopperの10J/tokenからBlackwellでは0.4J/tokenにまで低減されています。
Blackwellは、B100、B200、およびGB200 NVL72に使われる「GB200 Grace Blackwell Superchip」の3種類が提供されます。B100はH100用に設計された冷却系(空冷)がそのまま使えるように、TDP(サーマル・デザイン・パワー)≒消費電力はH100と同じ700Wに設定されています。もっとも高性能なのが、Grace CPUと組み合わせるGB200用のB200で、TDPは1,200Wと大きく、水冷が前提です。
表1. BlackwellとHopperのGPU比較
| 名称 | Blackwell | Hopper | ||
|---|---|---|---|---|
| GB200 | B200 | B100 | H100SXM | |
| パッケージあたりダイ | 2 | 1 | ||
| 総トランジスタ数 | 2,080億 | 800億 | ||
| 半導体プロセス | TSMC 4NP | TSMC 4N | ||
| FP4 Tensorコア | 20 PFLOPS | 18 PFLOPS | 14 PFLOPS | - |
| FP6 Tensorコア | 10 PFLOPS | 9 PFLOPS | 7 PFLOPS | - |
| FP8 | 10 PFLOPS | 9 PFLOPS | 7 PFLOPS | 3,958 TFLOPS |
| INT8 Tensorコア | 10 POPS | 9 POPS | 7 POPS | 3,958 TOPS |
| FP16/BF16 Tensorコア | 5 PFLOPS | 4.5 PFLOPS | 3.5 PFLOPS | 1,979 TFLOPS |
| TF32 Tensorコア | 2.5 PFLOPS | 2.2 PFLOPS | 1.8 PFLOPS | 0.989 PFLOPS |
| FP32 | 80 TFLOPS | 75 TFLOPS | 60 TFLOPS | 67 TFLOPS |
| FP64 | 40 TFLOPS | 37 TFLOPS | 30 TFLOPS | 34 TFLOPS |
| FP64 Tensorコア | 40 TFLOPS | 37 TFLOPS | 30 TFLOPS | 67 TFLOPS |
| GPUメモリ容量 | 最大186GB | 最大192GB | 最大192GB | 80GB |
| GPUメモリ帯域 | 8TB/s | 3.35TB/s | ||
| NVIDIA🄬 NVLink🄬 | 第5世代 1.8TB/s | 第4世代 900GB/s | ||
| 消費電力 | 最大1,200W | 最大1,000W | 最大700W | 最大700W |
※GB200はBlackwell 1個あたりの仕様
※FP64を除く各Tensorコア性能は、スパース行列演算機能を適用した場合の理論上の最大性能を示しています。
実際のアプリケーションで取得したベンチマーク結果や、スパース方式等が異なる環境では数値が変動します。
Blackwellはどこがすごいのか
Blackwellはどこがすごいのでしょうか。代表的な特徴をいくつか紹介します。
(1) 第5世代のTensor Core
Tensorコアが強化され、第4世代のTensorコアを内蔵するHopperに比べて、TF32、FP16/BF16、INT8、FP8の各性能はいずれも2倍以上に高められました。また、FP4とFP6が新たに追加されています。近年の研究で、テンソル積を構成する積和計算のうち行列積演算の精度を落としてもモデルの正確性(推論の正確性)には大きく影響しないことが分かっています。FP4やFP6を用いることでより高速な学習や推論が可能になると考えられます。
(2) 第2世代のTransformer Engine
H100で搭載されたTransformer Engineが第2世代に進化しました。Transformer Engineは、学習においてFP8やFP16などの演算精度を自動的に選択して性能の最適化を図る機能で、Blackwellハードウェアとソフトウェア(NVIDIA TensorRTTM-LLMおよびNeMo Megatronフレームワークに統合されたダイナミックレンジ管理アルゴリズム)の組み合わせによって実現されます。MoE(Mixture-of-Experts:混合専門家モデル)を含むLLMの学習や推論の性能向上が図れます。
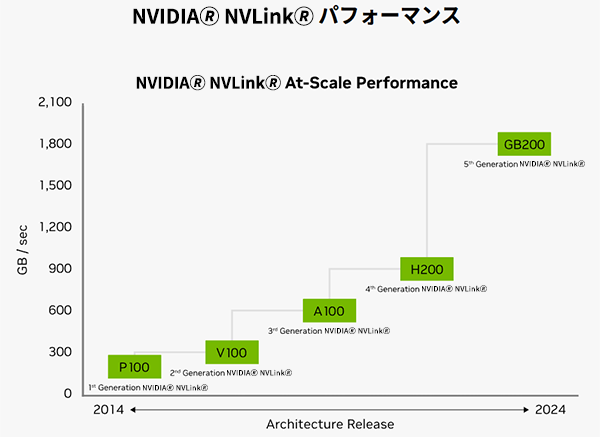
(3) 第5世代のNVIDIA🄬 NVLink🄬
BlackwellとBlackwell間を接続するNVIDIA🄬 NVLink🄬の性能は、第4世代のNVIDIA🄬 NVLink🄬の2倍に相当する1800GB/s×2(片方向あたり900GB/s)にまで高められました(図3)。
複数のBlackwellをまたぐ処理(たとえば部分積のやりとり)も、インターコネクトによるオーバーヘッドなく高速に処理できることを意味します。なお、後述するHGX B200やDGX B200では筐体内の8個のBlackwellのみがNVIDIA🄬 NVLink🄬で接続されています。GB200 NVL72ではラック内の72個のBlackwellすべてがNVIDIA🄬 NVLink🄬で接続されています。
(4) RASエンジン
信頼性(Reliability)、可用性(Availability)、および保守性(Serviceability)を高めるためにRASエンジンが新たに搭載されました。すべてのトランジスタ、フリップ・フロップ、オンメモリおよびオフメモリを診断して、異常を早期に検知する機能などが搭載されています。
(5) デコンプレッション・エンジン
圧縮されたデータを高速に伸長する機能が搭載されています。相対的に低速なストレージやネットワークからの転送量を圧縮によって削減する狙いです。
(6) 2個のダイを1パッケージに統合
冒頭で触れたように、レチクル・サイズ上限の2個のダイを、8個のHBM3eメモリ・ダイとともに、3Dパッケージング技術を使ってひとつのパッケージに統合することで、製造におけるダイ・サイズの制限を克服しています。2個のダイは10TB/sもの性能を持つNV-HBI(High-Bandwidth Interface)で接続されていて、実質的に1個のGPUとして機能します。
BlackwellのGPUを使うには
BlackwellのGPUは次の製品ラインナップで提供されています。
・NVIDIA DGX™ B200
NVIDIA DGX™ B200は、企業規模を問わず、AI導入のどの段階においても、パイプラインの開発から導入までを可能にする統合AIプラットフォームです。
第5世代のNVIDIA🄬 NVLink🄬で相互接続された8基のNVIDIA B200 Tensor コア GPUを搭載したDGX B200は、前世代と比較してトレーニング性能は3倍、推論性能は15倍の性能を提供します。
大規模言語モデル、レコメンダーシステム、チャットボットなどの多様なワークロードを処理することができ、AIトランスフォーメーションの加速を目指す企業に最適です。
・HGX B200
NVIDIAがOEMパートナー向けに提供する8GPUのユニットです。マザーボード、電源、外部ネットワーク・インタフェースなどを組み合わせた高さ10U前後の完成品が各OEMパートナー(ベアボーン・ベンダー)から提供されます。
HGX B200は、NVIDIA Blackwell TensorコアGPUと高速相互接続を統合し、データセンターを新しい時代に押し上げます。BlackwellベースのHGXシステムは、推論性能が前世代の最大15倍となるプレミア アクセラレーテッド スケールアップ プラットフォームであり、処理要求が非常に厳しい生成AI、データ分析、HPCのワークロード向けに設計されています。
・NVIDIA GB200 NVL2
NVIDIA GB200 NVL2は、2基のBlackwell GPUと2基のGrace GPUを搭載し、シングルノードNVIDIA MGX™アーキテクチャを採用した、省スペースラックマウント型サーバーです。さまざまなネットワーキングオプションと接続可能なため、既存のデータセンターへシームレスに導入できます。
生成AI/LLMの学習・推論用基盤や、ベクトルデータベース検索、データ処理に高いパフォーマンスを発揮します。
・NVIDIA GB200 NVL72
NVIDIA GB200 NVL72は、第5世代 NVIDIA🄬 NVLink🄬インターコネクト技術で、36基のNVIDIA GB200 Superchip(36個のGrace CPU+72個のBlackwell GPU)を1つのラックに統合したエクサスケールコンピューターです。
兆単位のパラメーターを持つLLMのリアルタイム推論性能を、前世代のH100 GPUと比較して30倍高速化します。
計算処理密度を高めた水冷式ラックとして稼働し、NVIDIA H100空冷サーバーと同じワークロードを実行する場合には、最大25倍の電力効率を発揮します。また、データセンターの二酸化炭素排出量とエネルギー消費を節約し、必要なフロア・ラック面積を削減できます。
表2. Blackwellを搭載したシステムの概要
| DGX B200 | HGX B200 | GB200 NVL2 | GB200 NVL72 | |
|---|---|---|---|---|
| 外観 |  |
 |
 |
 |
| GPU | B200 | B200 | GB200版 | |
| GPU個数 | 8 | 8 | 2 | 72 |
| GPUメモリ | 1.5TB | 1.5TB | 384GB | 13.8TB |
| FP4推論性能 | 144 PFLOPS | 144 PFLOPS | 40 PFLOPS | 1440 PFLOPS |
| FP8学習性能 | 72 PFLOPS | 72 PFLOPS | 20 PFLOPS | 720 PFLOPS |
| CPU | Intel Xeon Platinum 8570 | OEMメーカーの 仕様に基づき カスタマイズ可能 |
Grace(Arm Neoverse V2コア) | |
| CPU個数 | 2 | 2 | 2 | 36 |
| CPUコア数 | 112 | OEMメーカーの 仕様に基づき カスタマイズ可能 |
144 | 2,592 |
| CPUメモリ | 最大4TB | OEMメーカーの 仕様に基づき カスタマイズ可能 |
最大960GB | 最大17TB |
| ストレージ | 1.9TB×2+3.84TB×8 | OEMメーカーの 仕様に基づき カスタマイズ可能 |
- | - |
| 高さ | 10U | - | 2U | 48U |
| 消費電力 | 最大14.3kW | - | 120kW | 120kW |
| 冷却 | 空冷 | 空冷/水冷 | 水冷 | 水冷 |
※仕様は変更される場合があります
上記で挙げたGB200 Grace Blackwell Superchipを図4に示します。見て分かるように、Superchipという名称ですが実質は基板モジュールと考えて差し支えありません。上側の2個のデバイスがフル性能版のB200(このB200は便宜的にGB200と呼ばれることもあります)、中央のデバイスが72コアを内蔵したGrace CPUです。
GB200 NVL72を構成する1UのGB200コンピュート・トレイには、このGB200 Grace Blackwell Superchipが2枚横並びで収容されています。ただし、GB200 NVL2には使われていません。

図4. GB200 Grace Blackwell Superchipの外観
デスクにおける小型のAIスーパーコンピューター「NVIDIA🄬 Project DIGITS」も発表
NVIDIAはBlackwellプラットフォームのさらなる展開を発表しています。
・Blackwell B300/GB300(旧Blackwel Ultra)
メモリを192GB(8個のHBM3e)から288GB(12個のHBM3e)に増強したBlackwell B300/GB300が2025年にリリースされる予定です。GPUコア(演算性能)やTDPに変更があるかどうかは明らかにされていません。2024年6月のCOMPUTEX Taipeiで発表されました。
・Project DIGITSとGB10 Superchip
「Project DIGITS」と呼ばれる小型のAIスーパーコンピューターが2025年1月7日のCESで発表されました(図5)。
NVIDIA🄬 Project DIGITS|GPUならNTTPC|NVIDIAエリートパートナー
Project DIGITSには、新しいNVIDIA GB10 Grace Blackwell Superchipが搭載され、大規模なAIモデルのプロトタイピング、ファインチューニング実行に向きます。
FP4にて1 PFLOPSの演算性能を持つBlackwell GPU(小型版)と専用のGrace CPUとをシングル・パッケージに封止したチップ「GB10」が搭載されています。Project DIGITSは2025年5月ごろに発売される予定で、価格が3,000ドル~と安価なこともあり、注目を集めています。

図5. Project DIGITSと、搭載されているGB10 Superchip。Project DIGITSは手のひら程のサイズ
まとめ
本記事では、生成AIのパフォーマンスを飛躍的に向上させるBlackwell GPUについて、その特長や性能構成、ラインナップ、今後の展開について紹介しました。第5世代のTensor Coreや第2世代のTransformer Engine・第5世代のNVIDIA🄬 NVLink🄬が寄与し、前世代のHopperに比べ学習性能やリアルタイムLLM推論が飛躍的に高まります。これまでにない高性能GPUによって、基盤モデルの研究開発が加速していくとともに、生成AIを利用したサービスの高度化が図られていくに違いありません。
※本記事は2025年1月中旬時点の情報に基づいています。製品に関わる情報等は予告なく変更される場合がありますので、あらかじめご了承ください。NVIDIAが公表している最新の情報が優先されます。