



基礎知識
いまさら聞けないCUDA:GPU並列処理の基礎技術
2025.11.25

GPUエンジニア

NVIDIA GPUの並列処理能力を最大限に引き出すための中核技術NVIDIA® CUDA®(Compute Unified Device Architecture)。AI・数値計算・画像処理といった幅広い用途に適したライブラリ群が充実しており、そのエコシステムは拡大を続けています。
本記事では、CUDAの基本構造から、NVIDIA® CUDA® Toolkit(以下、CUDA Toolkit)やRAPIDS™(GPU高速化ライブラリ)との役割の違い、実際の処理速度比較、ビジネスでの導入ステップまで、「GPUが手元に届いたら、まず何から始めればいいの?」とお悩みの実務担当者の方にもわかりやすく解説します。
目次:
- CUDAとは?ビジネスで活用が広がるGPU並列処理の基盤技術
- CUDAエコシステムの構成要素
- CUDAによる処理の基本構造と開発環境
3-1. CUDAによる処理の基本構造
3-2. 開発に必要なツールと環境 - NVIDIA CUDA Toolkitとは?GPU開発を支える公式ツール群
- NVIDIA CUDA Toolkitの使い方:業務目的と技術レベルに応じた5つの活用アプローチ
5-1. ライブラリで手軽にGPU高速化【Python活用】
5-2. AIフレームワーク(PyTorch / TensorFlow)で本番導入【Python活用】
5-3. Numbaでカスタム処理をGPU化【Python活用】
5-4. CUDA C/C++で最大パフォーマンスを実現 - よくある質問(FAQ)
6-1. CUDAはどのようなプロジェクトに適しているか?
6-2. 他のGPUプログラミング技術との違いは? - まとめ
1. CUDAとは?ビジネスで活用が広がるGPU並列処理の基盤技術
CUDAとは、NVIDIAが提供するGPU専用の並列処理プラットフォームであり、大量のデータを高速に処理するための中核技術です。
もともとはC/C++ベースで開発された技術ですが、近年ではPythonや機械学習フレームワークとの連携が進んでいます。GPUを使いこなすための事実上の標準インフラといっても過言ではないでしょう。
CUDAを利用すれば、拡張プログラミング言語を用いてGPUを直接制御することができます。たとえば、従来のCPUでは数時間かかっていたモデル学習やシミュレーションが、CUDAを活用したGPU並列処理により数分〜数十分に短縮されることも珍しくありません。これにより、開発の高速化だけでなく、コスト削減や業務効率化にも直結します。
2. CUDAエコシステムの構成要素
CUDAは、単なる開発ツールやライブラリにとどまらず、GPU活用を実現するための周辺ツールや実行環境までを含めた広義のエコシステムとして設計されています。
CUDAを構成する要素は、次のような多層構造として捉えることができます。
- アーキテクチャ層:GPUの並列処理モデル(グリッド・ブロック・スレッド階層、SIMTなど)
- プログラミング層:CUDA C/C++やPythonなど、GPU制御のための言語・API
- 開発環境層(CUDA Toolkit):NVCCコンパイラ、CUDA-Xライブラリ(cuBLAS・cuDNN・cuFFTなどの最適化済みライブラリ群)、Nsightなどの開発・解析ツール
- 高水準ライブラリ層:RAPIDSやTensorRT™など、Toolkit上に構築された業務向けライブラリ
このように、CUDAは単なる「GPUを動かすための技術」ではなく、開発・運用・業務活用までを支える総合的な技術基盤として、広範なエコシステムが構築されています。
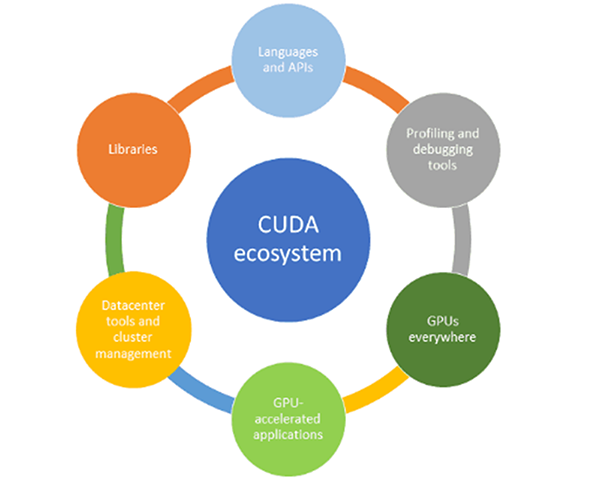
| CUDA層 | エコシステムの各要素 | 説明 |
|---|---|---|
| ① アーキテクチャ層 | GPUs everywhere | ノートPCやサーバー、クラウド環境などCUDA実行環境の総称 |
| ② プログラミング層 | Languages and APIs | CUDA C/C++、Python(Numba、PyCUDAなど)を用いたGPU制御用のプログラミングインターフェース |
| ③ 開発環境層 (CUDA Toolkit) |
CUDA-Xライブラリ (cuDNN、cuBLAS、TensorRTなど) Profiling and Debugging Tools (Nsight Compute / Systems など) |
GPUアプリ開発を支えるCUDA-Xライブラリと、性能解析・デバッグツール群を含み、CUDA Toolkitの主要要素を構成する ※CUDA-Xライブラリは、行列演算(cuBLAS)、深層学習(cuDNN)、信号処理(cuFFT)、推論最適化(TensorRT)など、幅広い分野をカバーしており、高水準ライブラリ層(RAPIDSなど)や外部のAIフレームワーク(PyTorch、TensorFlowなど)からも利用される基盤となっている。 |
| ④ 高水準ライブラリ層 | GPU-accelerated Applications (AI、HPC、映像処理、可視化など) Datacenter Tools (NVIDIA NGC、クラスタ管理ツールなど) |
CUDAを活用する業務アプリケーションや、それらを支える運用インフラ全般 |
中でも、「③ 開発環境層(CUDA Toolkit)」が充実していることがCUDAエコシステムの競争力の源泉となっています。
難しいプログラミング言語を使わなくてもやりたいことを実現できたり、普段利用しているライブラリとの互換性が担保されていることが開発のハードルを下げ、今日のNVIDIA GPUの普及につながっています。
また、CUDAのエコシステムは日々進化しており、さまざまなアップデートが加えられています。より詳細を知りたい方は、NVIDIA CUDAの技術情報も参考にしてみてください。
3. CUDAによる処理の基本構造と開発環境
GPUを活用した開発を始めるうえで重要なのが、「CUDAによる処理がどのように構成されているのか」という前提条件を理解することです。
プログラミングを始める前にエコシステム全体を俯瞰したうえで、実際のプログラムがどのようにGPU上で実行されるのか、その基本的な流れと開発ステップを押さえておくことは、効率的なCUDA活用への第一歩となります。
ここでは、CUDAを活用する際の基本的な処理フローと、実際に操作するツール群について解説します。
3-1. CUDAによる処理の基本構造
CUDAによる並列処理では、ホスト(CPU)とデバイス(GPU)の役割が明確に分かれており、次のような一連のステップで構成されます。
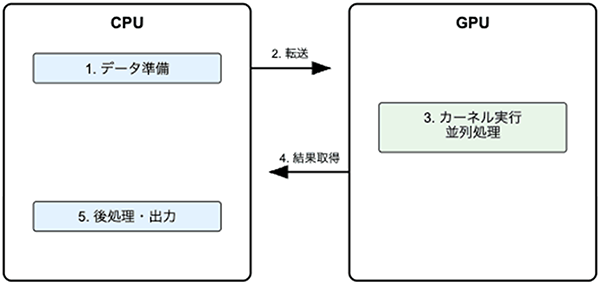
CUDAによる処理の基本構造イメージ
- データの準備
処理対象となるデータ(例:数値配列や行列など)をホスト(CPU側)で用意します。 - データの転送
ホストメモリ上のデータを、CUDAのメモリ管理関数(例:cudaMemcpy)を用いて、GPU側のデバイスメモリへ転送します。 - カーネル関数の実行
GPU上で並列に実行される処理(カーネル関数)を、CUDAの構文(例:<<<gridDim, blockDim>>>)で起動します。これにより、膨大な数のスレッドによる同時処理が実現されます。 - 結果の取得
処理が完了した結果データをCUDAのメモリ管理関数(例:cudaMemcpy)を用いて、デバイスからホスト側に戻します。 - 後処理・出力
得られた結果に対し、ホスト側で可視化や保存などの後処理を実施します。
このように、CPUとGPUの役割を明確に設計できる点は、CUDAを用いた開発の大きな特徴です。処理の特性に応じて最適な分担を行うことで、GPUが持つ高い並列演算性能を効果的に活用できます。
3-2. 開発に必要なツールと環境
CUDAを活用したGPU開発を行ううえで、代表的な開発ツールや環境構成要素は以下の通りです。
| ツール・環境 | 役割・概要 |
|---|---|
| CUDA Toolkit | NVIDIAが提供する公式SDKで、NVCCコンパイラやcuBLAS・cuDNNなどのライブラリ、開発ツールを含む統合パッケージ |
| GPUドライバ | 対象GPUに対応したNVIDIA製ドライバであり、CUDAとの連携とGPUリソースの認識・利用に必要 |
| 統合開発環境(IDE) | Visual StudioやVS Codeなど、CUDAコードの作成・補完・ビルド・デバッグを支援する統合型開発環境 |
| 軽量エディタ | VS CodeやSublime Textなど、シンプルで柔軟な編集操作を重視する開発者向けエディタ |
| 環境設定 | PATH設定やnvcc --versionによるコンパイラ確認、nvidia-smiによるGPU認識確認など、開発準備に必要な構成手順 |
4. NVIDIA CUDA Toolkitとは?GPU開発を支える公式ツール群
CUDA Toolkitは、NVIDIA GPU上で動作するアプリケーションを開発・最適化するための公式開発パッケージ(SDK)です。GPUプログラミングに必要なコンパイラ、最適化ライブラリ、デバッグ・プロファイリングツールなどが一括で提供されており、CUDAを使った開発の出発点となる存在です。
2025年6月時点の最新版「CUDA Toolkit 12.9 Update 1」では、最新のBlackwellアーキテクチャにも対応しており、高性能かつ信頼性の高い開発環境が整っています。

CUDA Toolkitに含まれる主なコンポーネントは以下の通りです。
| コンポーネント | 概要 |
|---|---|
| NVCC(CUDA C/C++コンパイラ) | GPUカーネルとCPUコードの一括ビルド |
| cuBLAS / cuDNNなどの最適化ライブラリ | 行列演算やディープラーニングに特化した高速処理機能 |
| CUDA Runtime / Driver API | メモリ管理やカーネル実行の抽象化レイヤ |
| Nsight Compute / Nsight Systems | GPU処理のボトルネックを解析するための可視化ツール |
| CUDA‐LLVM | カスタム言語やDSL向けのLLVMベース開発環境 |
これらのツールは、なんとNVIDIA公式サイトから無償で提供されています。開発環境に応じて適したものをダウンロードしましょう。
5. NVIDIA CUDA Toolkitの使い方:業務目的と技術レベルに応じた5つの活用アプローチ
CUDAはAI・数値計算・画像処理・HPCなど幅広い用途に適したライブラリを備えています。初心者でも簡単に立ち上げられる特定用途向けテンプレートもあれば、逆にカスタマイズ性を求める玄人が満足できる機能も整っています。
次の項目では、企業や組織がCUDA Toolkitを活用する際の代表的な5つの手法を、CUDAとの関係、主な技術スタック、利用シーンの3つの観点から整理します。
5-1. ライブラリで手軽にGPU高速化【Python活用】
Pythonユーザーであれば、既存コードに近い感覚でGPUによる高速処理を導入できます。処理の多くはライブラリ側が担うため、導入にかかる時間も短く、初期検証にも適したアプローチです。なかでも有力な選択肢の一つが、NVIDIAが提供するオープンソースライブラリ群「RAPIDS(ラピッズ)」です。RAPIDSはCUDA Toolkitを基盤に構築されており、PythonだけでGPU処理を実現できる高水準なAPIを提供しています。
①CUDAの処理構造との関係:
- CUDAの処理構造をツール側が内部でラップしており、ユーザーはCUDAを意識することなく利用が可能
②主な技術スタック:
- cuDF:pandas互換のGPUデータフレーム処理ライブラリ
- cuML:scikit-learn互換のGPU機械学習ライブラリ
③利用シーン:
- Pythonベースの環境を維持しつつ、データ分析やPoC、モデルの高速学習などを効率的に進めたい場合
5-2. AIフレームワーク(PyTorch / TensorFlow)で本番導入【Python活用】
PyTorchやTensorFlowなどのAIフレームワークは、大規模なディープラーニングの学習や推論を支える基盤として広く活用されています。
いずれもCUDAに最適化されており、Pythonから直感的にGPU処理を実行できるため、本番環境での高負荷なAIワークロードにも対応可能です。
①CUDAの処理構造との関係:
- バックエンドで cuDNN や CUDA を自動的に活用しており、明示的なGPU制御を記述することなく、高速化を実現
②主な技術スタック:
- PyTorch:柔軟な記述スタイルとデバッグ性に優れ、研究開発での利用が多いディープラーニングフレームワーク
- TensorFlow:スケーラブルな構成に対応しやすく、本番運用や大規模サービスでの利用に適したフレームワーク
※いずれも内部的に CUDA・cuDNN を活用しており、GPUによる高速な学習・推論が可能です。
③利用シーン:
- AIプロジェクトにおける画像認識、自然言語処理、リアルタイム推論などの本番運用で、高速な学習・推論基盤を構築したい場合
5-3. Numbaでカスタム処理をGPU化【Python活用】
Numbaは、Pythonコード内に直接CUDAカーネル(GPU向け関数)を記述できるライブラリです。標準のPython構文に近い形でGPUコードを記述できるため、柔軟なカスタム処理を高速に実装したい場合に適しています。ライブラリベースでは対応しづらい独自アルゴリズムのGPU化にも対応でき、中級者以上の開発者にとって強力な選択肢となります。
①CUDAの処理構造との関係:
- CUDAカーネルをPythonコード内で明示的に記述でき、必要に応じてメモリ転送などの制御も可能なため、柔軟なGPU制御が実現
②主な技術スタック:
- Numba(@cuda.jit デコレータでGPU関数を記述)
③利用シーン:
- 業務ロジックに近い独自の処理や、ループ・数式演算などの柔軟なGPUオフロードが求められる場面
- 標準のライブラリで対応できない独自処理を柔軟にGPU化したい場合
5-4. CUDA C/C++で最大パフォーマンスを実現
CUDA C/C++は、CUDAの本質的な活用方法であり、GPUカーネルをC/C++で直接記述することで、最も細やかな制御と高いパフォーマンス最適化が可能です。
メモリ配置やスレッド制御などを明示的に設計する必要があり、高度な技術力を要します。
①CUDAの処理構造との関係:
- CUDAの処理構造すべてを開発者が詳細に設計する必要があり、最も高い自由度とパフォーマンス最適化を実現
②主な技術スタック:
- CUDA C/C++(__global__ 関数でカーネル記述、cudaMemcpy などによる明示的なメモリ管理)
③利用シーン:
- 金融リスク計算、製造業のシミュレーション、大規模な数値解析など、最大限の処理効率と細やかな制御が求められる高度な用途
このように、CUDA活用には複数のアプローチが存在し、それぞれに特性・導入難易度・適用領域が異なります。どの手法を採用すべきかは、自社の業務目的、人材スキル、既存システムとの親和性といった観点から検討するとよいでしょう。
たとえば、初期段階では分析部門がPythonライブラリを用いてGPUによる処理高速化の効果を簡易に検証し、十分な成果が確認できた段階で、CUDA C/C++を活用した本格的な最適化に移行する――こうした段階的な導入プロセスは、実現性と費用対効果の両面において有効なアプローチだといえます。
6. よくある質問(FAQ)
6-1. CUDAはどのようなプロジェクトに適しているか?
CUDAは、GPUを活用した並列処理が必要なプロジェクトに適しています。特に、生成AI/LLM、VLM/画像処理、シミュレーション、科学技術計算など、大量のデータを高速に処理する必要がある分野で効果を発揮します。さらに、各用途に対応したライブラリやAPIも充実しています。
6-2. 他のGPUプログラミング技術との違いは?
CUDAは、NVIDIAのGPU向けに特化して設計された技術であり、NVIDIA GPUを最大限に活用することが可能です。これに対して、OpenCLやDirectComputeは、複数のハードウェアベンダーに対応した汎用的な技術です。CUDAは、NVIDIAの独自最適化が施されており、高性能なGPU処理を実現するためのツールやライブラリが充実している点が大きな特徴です。
7. まとめ
本記事では、CUDAエコシステムの全体像、処理構造の特徴、CUDA Toolkitの基本構成、そして代表的な活用手法について紹介しました。
CUDAは、PythonライブラリやAIフレームワークを活用した手軽なGPU活用から、CUDA C/C++による高度な並列処理の実装まで、業務ニーズや技術レベルに応じて柔軟に選択できるプラットフォームです。さらに、用途や技術スキルに応じて、小規模な試行から高度な並列処理まで、一貫してGPUリソースを有効活用できる点は、CUDAならではの大きな強みといえるでしょう。
最新のGPUアーキテクチャに対応し、さまざまなユーザーの用途にあわせたツール郡を提供することで、CUDAエコシステムはますます拡大しています。本記事が、GPU開発環境の構築や、CUDA導入方針の検討にあたり参考となれば幸いです。
多様なGPUソリューションと豊富な導入実績を持つNTTPCは、お客さまのビジネス課題解決に適したGPU環境をご提案します。ミッションクリティカルな商用AIサービスから、高いパフォーマンスが求められる研究開発基盤に至るまで、用途・予算に合わせた適切なAI基盤の設計・構築が可能です。
GPU導入をご検討の企業や組織の担当者さまはお気軽にNTTPCにご相談ください。
▶︎ お問い合わせはこちら
※NVIDIA、CUDA、CUDA-X、RAPIDS、TensorRTは、米国およびその他の国におけるNVIDIA Corporationの商標または登録商標です。
※Pythonは、Python Software Foundationの登録商標です。
※PyTorchは、The Linux Foundationの登録商標または商標です。
※TensorFlowは、Google LLCの商標または登録商標です。
※OpenCLは、Apple Inc.の商標であり、Khronosの許可を受けて使用されています。
※本記事は2025年10月時点の情報に基づいています。製品に関わる情報等は予告なく変更される場合がありますので、あらかじめご了承ください。メーカーが公表している最新の情報が優先されます。