



性能検証
ディープラーニングを用いた音声変換技術と「VOICE MART」での活用 〜あらゆる声が動き出す、声のマーケット〜
2021.07.01

プロダクトマネージャー
飯田 嘉一郎

ソフトウェアエンジニア
長澤 優佑

追記:VOICE MARTの開発は2022年3月に終了しました。本記事は2021年7月時点の開発内容に基づくものです。
「あなたは声によって印象が変わった経験はありますか?」
私は何度か経験があります。アニメキャラクターの声優が交代した時にキャラクターの印象が変わってしまったという経験や、初対面の方とのビデオ会議では声によってその人の印象が左右されるなと感じた経験等です。
このように声がコミュニケーションにおいて非常に重要な要素であるとことは、経験則で共感してもらえるのではないでしょうか?
声は人同士の対面コミュニケーションや電話等のコミュニケーションだけではなく、現在ではスマートスピーカーのような機械とのコミュニケーションにも利用されるようになってきています。
このように、コミュニケーションにおける「声」の価値は高まってきています。私は、全ての「声」を理想の声に変えることができたら、世の中の音声を使ったコミュニケーションがもっと良くなるのでは?と考えました。
そこで、音声変換技術の検証を実施し、「VOICE MART™」というサービスにできないか検討しています。
本記事ではディープラーニングを用いた音声変換技術とその活用アイデア「VOICE MART」を紹介します。最後までお読みになり、声変換技術の面白さとその可能性について感じていただければ幸いです。
まずは、音声変換技術について紹介します。
音声変換技術とは
音声変換技術とは人や機械が発話した音声を、発話内容を変えずに別の声に変換し出力する技術です。その中でも本記事で紹介する技術は「任意の声に変換する技術」です。
昔から音声のピッチを変換して声を変える手法は存在しますが、「任意の声への変換」となるとピッチだけではなく他にもさまざまな声のパラメータを操作する必要があります。
まずは、声をどのように変換するのかという部分から簡単に紹介します。
音声変換で変換するパラメータ
人の声質を変換する際には音声の特徴を分解し、適切に変換をする必要があります。
声質と言っても1つの要素ではなく、図1の3つのパラメータで構成されているという考え方が主流です。(参考https://www.jstage.jst.go.jp/article/jasj/74/11/74_608/_pdf#:~:text=%E9%9D%9E%E5%91%A8%E6%9C%9F%E6%80%A7%E6%8C%87%E6%A8%99%E3%81%AF,%E5%89%B2%E5%90%88%E3%81%A8%E3%81%97%E3%81%A6%E5%AE%9A%E7%BE%A9%E3%81%95%E3%82%8C%E3%82%8B%E3%80%82)
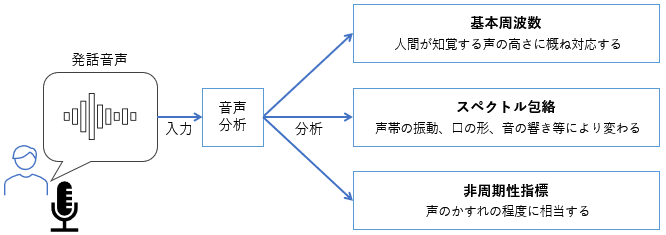
図1 人の声の3種のパラメータ
AI音声変換の仕組み
AI音声変換で押さえておくべき声のパラメータについてわかったところで、AI音声変換の仕組みを紹介します。AI音声変換は図のような流れで音声を変換します。 事前に音声データをAIに学習させることで、音声のパラメータを変換できる「変換モデル」を作ります。 実際に変換する際には変換前音声のパラメータを分析し、そのパラメータを変換モデルで変換します。その後、変換したパラメータを使って合成音声を生成し、別の声に変換された音声が出力されるというわけです。(図2)
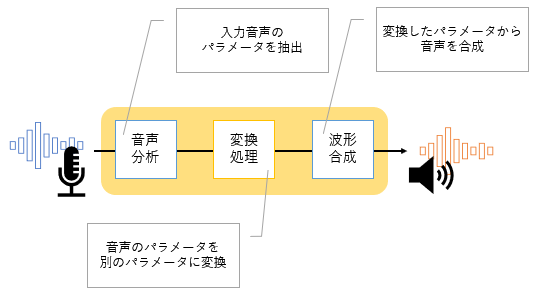
図2 音声パラメータの変換を使った音声変換の概略図
そのため、変換後音声は生成された合成音声になります。よくある合成音声ソフトは文章から音声を生成するText to Speechのものになりますが、音声変換の合成音声はSpeech to Speechということになりますね。
既存のAI音声変換手法の課題
AI音声変換技術が発展したおかげで変換音声の品質が向上してきましたが、実用化には多くの問題があります。その中の大きな問題の一つに「1対1の音声変換にしか対応できない」というものがあります。1対1の音声変換とはどういうことか?というと、「事前に音声を学習した1対1のペアでなければ正しく音声変換できない技術である」ということです。つまり、誰が話してもXXさんの声になることができるわけではなく、事前に学習させたAさんの声でなければXXさんの声になれません。また、多数の人の声を変換したい場合はその人数分の変換モデルを作成する必要があり、非常に非効率です。(図3参照)
実際に音声変換を利用するためには、誰の声でも変換ができる多対1の音声変換を実現が必要です。本記事で紹介する音声変換技術は1対1の音声変換技術ではなく、多対1の音声変換を実現しています。
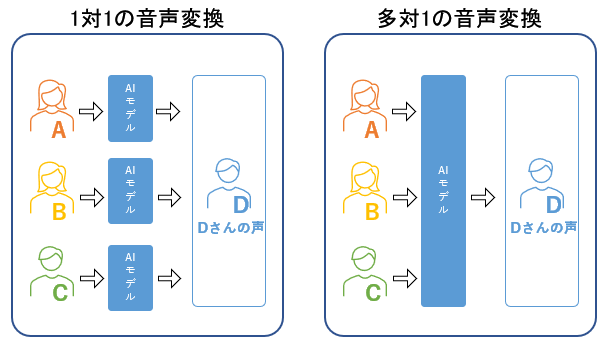
図3「1対1音声変換と多対1音声変換」
多対1の音声変換のデモ音声
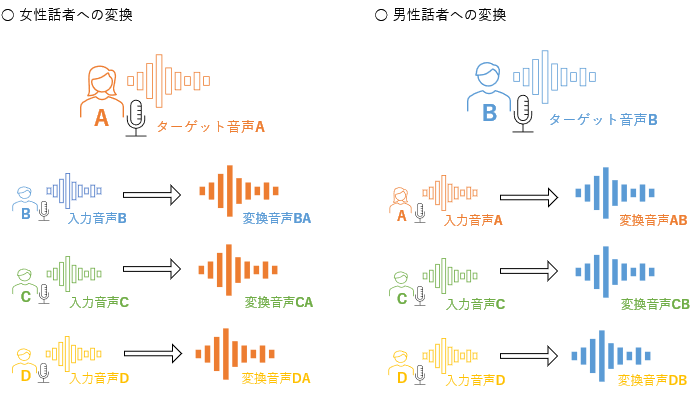
図4「入力音声と変換音声の関係」
音声:変換音声
| ◯女性話者への変換 ターゲット音声A |
入力音声B |
変換音声BA |
|---|---|---|
| 入力音声C |
変換音声CA |
|
| 入力音声D |
変換音声DA |
|
| ◯男性話者への変換 ターゲット音声B |
入力音声A |
変換音声AB |
| 入力音声C |
変換音声CB |
|
| 入力音声D |
変換音声DB |
上記は変換先として男性・女性各1名の音声(ターゲット音声)を設定し、マイクから入力された音声(入力音声)をリアルタイムで変換した音声(変換音声)です。各ターゲット音声に対し、3名分の入力音声を変換しています。
同じターゲット音声を設定した変換音声は、入力音声の性別や話速に関わらず同じような音声に変換されており、多対1の変換が実現できていることがお分かりになるかと思います。
この多対1の音声変換は、NTT研究所の技術を活用して作成した2種類の音声変換AIにより実現しています。
1つ目は”AttS2Svc(以下、S2S)”という技術です。音声の系列変換を行うことで、音声変換をリアルタイムで行うことができるAIモデルを作成することができます。S2Sでは、入力音声の抑揚や話速も含めた高品質な音声変換が可能です。
2つ目は”WaveCycleGAN(以下、WCG)”という技術です。敵対的学習を行うことで合成音声に「自然なゆらぎ」を与えるAIモデルを作成することができます。
この2種類のAIを組み合わせることで、デモ音声を作成しています。
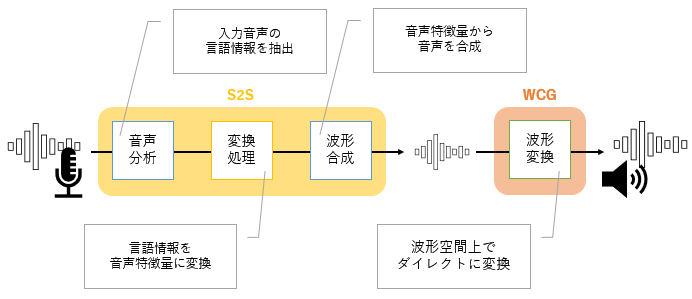
図5:音声変換の仕組み
ただし、我々が作成したAIモデルによる変換音声は、ターゲット音声との類似度が「ある程度似ている」というレベルにとどまっています。入力音声の汎化状態を保ちながら、ターゲット音声との類似度がより高い変換を行うことができるよう、音声変換AIを改善していく必要があります。
このような技術を活用することで、「全ての声を理想の声に変える」というアイデアを実現できないか検討しております。
ここまで、音声変換技術にフォーカスした内容を記載してきましたが、次に音声変換技術の活用アイデアであるVOICE MARTについて紹介します。
VOICE MART〜あらゆる声が動き出す、声のマーケット〜
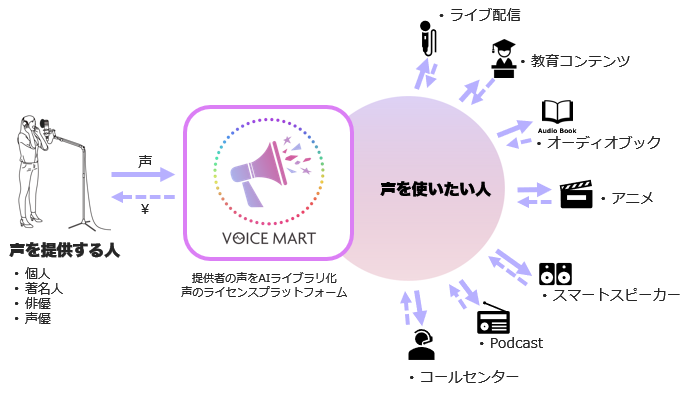
図6「VOICE MARTのコンセプト」
上記で紹介したディープラーニングによる音声変換技術を活用し、「すべての声を理想の声に変えられるプラットフォーム」であるVOICE MARTを考えています。利用イメージとしては、VOICE MARTに「声を提供する人」が声ライブラリを登録し「声を使いたい人」がそれを利用できるというものです。
現在、音声変換はVTuberのような動画配信者の利用やTV番組、カラオケで利用されてますが、今後音声変換の精度が向上することで様々なユースケースが増えていくと思っています。
音声変換の音声はText to Speechの合成音声と違い、双方向の音声コミュニケーションに向いているため、次の図のようなユースケースが増えていくと考えています。
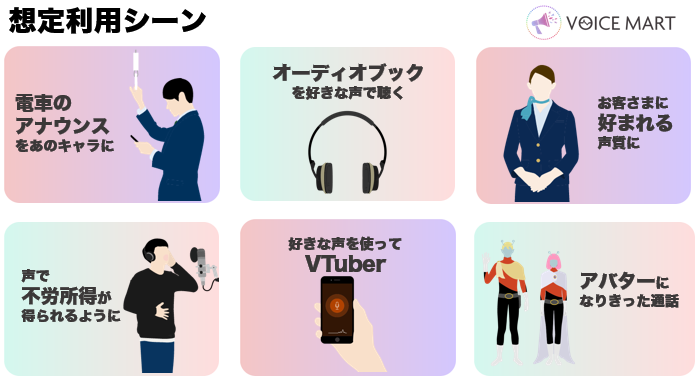
図7:想定ユースケース
- 電車のアナウンスの音声をとあるキャラクターの音声に変換することで、その電車の中はただの移動手段からテーマパークのような別空間に
- 好きな声を使ってVTuberになることで、キャラクターになりきった配信ができるように
- 声優が声を提供することで自分の時間を使わずとも声で不労所得が得られるように
NTTPCでは上記のようなユースケースを含め、音声変換技術の活用について日々検討しています。技術ドリブンで新しいサービスを作るというのは非常に苦労の連続ですが、様々なところから皆さまのご意見やアドバイスを賜りながらブラッシュアップしていければと思っています。
もしご興味のある方がいらっしゃいましたら、ぜひお問い合わせください!
まとめ
ディープラーニングを用いた音声変換技術とその活用アイデアVOICE MARTを紹介しました。今の音声変換技術の状況や活用方法について、皆さまのご参考になれば幸いです。