



技術解説
ディープラーニングによる
画像の拡大技術
2018.09.28

サービスクリエーション本部
データサイエンティスト
組橋 祐亮

1. はじめに
前回の記事では、思い出写真を「撮り直す」というコンセプトで画像をきれいに拡大するサービスである「スーパーリテイク™」について紹介しました。
今回の記事では、「スーパーリテイク™」でも用いられているディープラーニングを用いた画像の拡大技術について紹介したいと思います。
本記事は、
1.補間法による従来の画像拡大
2.ディープラーニング(CNN)を用いた画像拡大
3.より高度なGANを用いた画像拡大
の三部構成となっています。
2. 従来の画像拡大技術
まず、ディープラーニングを用いた画像の拡大技術の話をする前に、ディープラーニングを用いていない従来の拡大技術について少し触れたいと思います。
皆さんは、画像を拡大するときどのような方法で拡大を行いますか?
MacやWindowsに付属しているソフトウェアを使うでしょうか。それともGIMPやPhotoshopのような画像処理用のソフトウェアを使うでしょうか。もしくは、エンジニアであれば、OpenCVのようなライブラリを使ってプログラムを書くこともあるかもしれません。
いずれのソフトウェア/ライブラリでも、補間アルゴリズムによる画像拡大を行っています。補間アルゴリズムでもっとも容易なアルゴリズムの1つに、最近傍法 ( Nearest Neighbor法 ) と呼ばれる手法があります。これは、拡大した点の画素値を、最近傍 ( もっとも近く点 ) の画素値をそのまま用いる方法です。
Nearest Neighbor法は高速な手法ですが、品質はあまりよくありません。そこで近くの1点を用いるのではなく、近傍4点を用いた線形補間を行うBilinear法や4×4の近傍領域において隣接点までの距離に応じた重みを用いた補間を行うbicubic法を用いることで、計算量は増えますが画像の品質を向上させることができます。
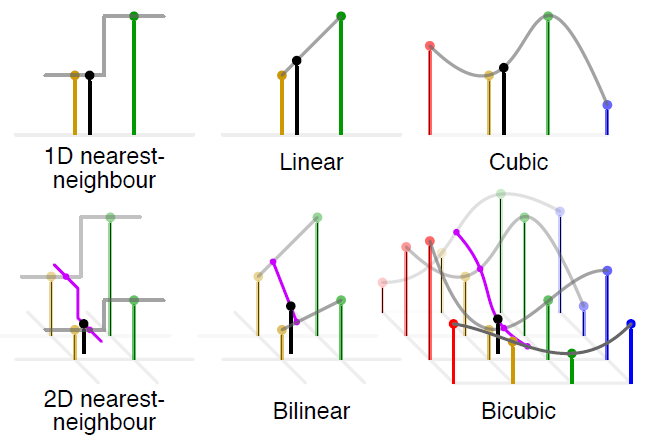
出典:Bicubic interpolation - Wikipedia
上図は補間のイメージを表したもので、黒色が補間された点で、黄色/緑色/赤色/青色が補間に用いられた点です。線の高さは画素値を表します。 また、もう少し高度なLanczos法と呼ばれるアルゴリズムもありますが、詳細は割愛します。これらの手法は次の表のようにまとめることができます。 ※1
| アルゴリズム名 | 画像の品質 | 処理速度 | 補間方法 |
|---|---|---|---|
| Nearest Neighbor |
悪い | 速い | もっとも近い点をそのまま用いる |
| Bilinear | やや悪い | やや速い | 近傍4点から線形補間を行う |
| bicubic | やや良い | やや遅い | 4×4の近傍領域の点を用いる |
| Lanczos-N | 良い | 遅い | 2Nx2Nの近傍点を用いる(Nは3か4であることが多い) |
これらのアルゴリズムは、GIMPやPhotoshopのような画像処理ソフトウェアであれば、画像を拡大する際に選択できます。上の表を参考に、用途に応じてアルゴリズムを選択すると良いでしょう。
それぞれのアルゴリズムで画像を拡大した結果は次のとおりです。

また、OpenCVやPillowなどのライブラリではデフォルトがBilinearになっていることが多いため注意が必要です。その他のアルゴリズムを用いる場合は引数で指定する必要があります。
次のものは、PythonでOpenCVとPillowを用いた画像拡大のコード例です。
import cv2 img = cv2.imread('/path/to/input.jpg') # Bilinear法(デフォルト) cv2.resize(img, (256, 256)) # bicubic法 cv2.resize(img, (256, 256), cv2.INTER_CUBIC)
cv2.INTER_CUBICと引数に指定することでbicubic法を用いたリサイズを行うことができます。 OpenCVでその他のアルゴリズムを用いる場合は、こちらをご参照ください。
from PIL import Image img = Image.open('/path/to/input.jpg') # Bilinear法(デフォルト) img = img.resize((256, 256)) # bicubic法 img = img.resize((256, 256), Image.BICUBIC)
Image.BICUBICと引数に指定することでbicubic法を用いたリサイズを行うことができます。
Pillowでその他のアルゴリズムを用いる場合は、こちらをご参照ください。
3. 超解像による画像拡大
3.1 超解像とは
これまでみてきた従来の画像拡大は、いずれも補間アルゴリズムを用いていました。前述の拡大結果の画像のように補間による拡大では、ボケやジャギーによる画像の劣化が否めません。
このような画像の劣化は補間アルゴリズムでは元画像に含まれる画素を利用しているため、どうしても発生してしまいます。そこで、補間ではなく元の画像に含まれない高周波成分の推定を行うことを考えます。これは、画像の解像度を向上させることを意味し、このような手法を超解像といいます。
ちなみに、画像における周波数とは、1画素動いたときに画素値がどれくらい変化するかを表します。つまり、高周波成分は次の画像でのように、細かい領域や複雑な領域になります。

複数の低解像度画像から1枚の高解像度画像を生成する手法もありますが、本記事は1枚の低解像度画像から1枚の高解像度画像を生成する問題 ( 単一画像の超解像 ) を扱います。
単一画像の超解像を実現する方法として、同じ画像の内部類似性を用いる方法やあらかじめ低解像度と高解像度の画像のペアから写像関数を学習する方法があります。
後者の方法を用いる代表的な手法に、 2008年に提案されたスパースコーディングベースの手法 ※2 があります。詳細は割愛しますが、辞書の学習に重きをおいているため、その他のステップ ( 前処理や後処理など ) は最適化されていないという問題があります。
3.2 CNNを用いた超解像
スパースコーディングベースの手法のように複数のステップがあるため、全体の最適化が行われていないといった問題を解決するため方法として、畳み込みニューラルネットワーク ( CNN ) を用いて入力画像と出力画像の写像を直接行うアイデアがあります。
このアイデアを実現したSuper-Resolution Convolutional Neural Network ( SRCNN ) ※3 は、2014年に発表されディープラーニングによる超解像の起点になりました。
SRCNNは以下のような3層の畳み込みニューラルネットワークで構成されます。Bicubicで拡大した低解像度の画像を入力とし、入力画像をこのネットワークに通すことで高解像度の画像が出力されるように学習を行います。
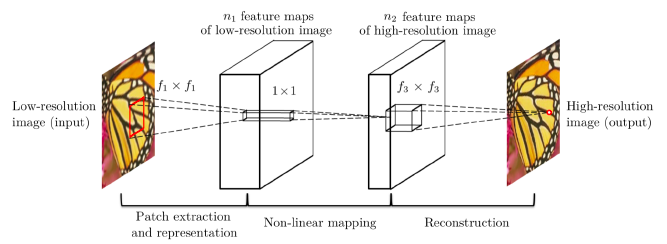
出典: Image Super-Resolution Using Deep Convolutional Networks
ネットワークの損失関数には、低解像度の画像を超解像した画像と元の高解像度の画像 ( 正解画像 ) の平均二乗誤差 ( MSE ) が使われています。この誤差が小さくなるようにネットワークの重みの学習を行います。
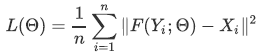
結果は、次の図で示すように、Bicubicのような補間法やスパースコーディングベースの手法 ( SC ) に比べてSRCNNは品質の高い画像の出力に成功しています。
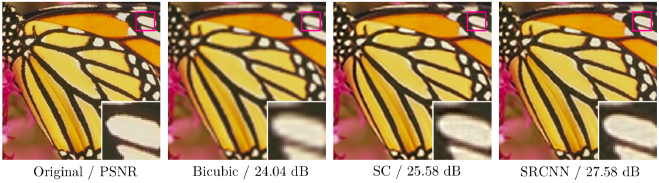
出典: Image Super-Resolution Using Deep Convolutional Networks
PSNRは、Peak Signal to Noise Ratioの略で画像の劣化を表す代表的な評価指標 ※4 です。
PSNRはMSEを用いて、次のように定義されています。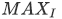 は画像に含まれる画素値の最大値です。一般に255です。
は画像に含まれる画素値の最大値です。一般に255です。
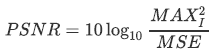
この指標は高いほど品質が良く、JPEGなどの非可逆圧縮では30~50dB程度になると言われています。
また、論文の著者の実験では、SCに比べ精度だけでなく処理速度も高速であることが示されています。CPUを利用してSCでは1枚あたり1分以上かかるのに対して、SRCNNでは1秒未満で推定が可能です。
4. GANを用いた超解像
SRCNNが世に出て以来、ディープラーニングを用いた超解像の論文が多く発表されました。
bicubicのような補間ベースの手法やスパースコーディングベースの手法に比べ精度の向上はしましたが、まだぼやける箇所があったりと十分ではありません。そこで、この節では、GAN ※5 という画像生成技術を用いた超解像 ( SRGAN )について紹介します。
SRGANの発表以前、SRCNNをはじめとするCNNによる超解像手法は、一般に低解像度の画像と元の高解像度の画像とのMSEの最小化を最適化の目標としています。
前述したとおりPSNRはMSEを用いた評価指標であり、MSEの最小化はPSNRの最大化を行う上で都合が良い方法です。しかし、PSNRは必ずしも人間の知覚と一致しません。具体的には次の画像では、bicubicの方がこれから紹介するSRGANに比べPSNRの値が高くなっていますが、人間の目ではSRGANの方がぼやけておらず良い画像であると感じる人が多いでしょう。

※ ( ) 内の左の値がPSNRで、右の値がSSIMという別の評価指標です。
出典: Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial
Network
MSEのような画素単位の損失関数は、テクスチャのような高周波成分を再現することが難しいといった問題があります。これは次の図のように、MSEベースの手法の場合、高周波成分を有する複数の画像を用いて平均的な解を求めるためです。
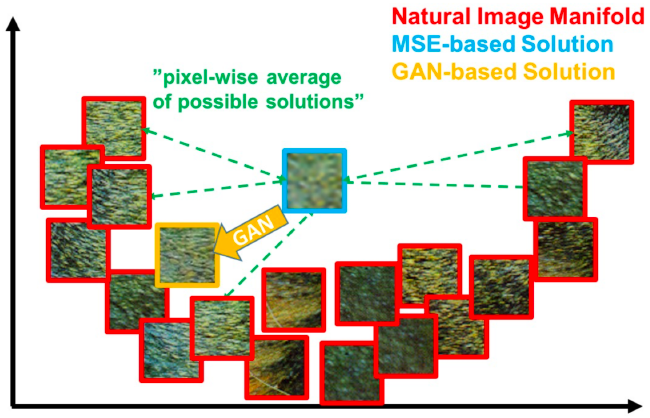
出典: Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
そこで、上図のGANベースのように、多様性のある自然画像に近づけるような学習を行うSRGANが2017年に提案されました。
SRGANでは、
- ネットワークに、深いネットワークでも精度の高い学習が可能なResNet
- 損失関数に、GANベースのAdversarial LossとVGG ※6 ベースのContent Lossの2種類を組み合わせた知覚損失
を導入することで、より自然な超解像画像の生成を実現しています。
4.1 GAN
SRGANの話をする前に、GANについて軽く触れておきます。GANは、Generative Adversarial Networks ( 敵性的生成ネットワーク ) の略で、データを学習し似たような新しいデータを生成する手法です。

※右端の列が生成されたデータで、隣の列がもっとも近い学習データです。
出典: Generative Adversarial Networks
GANはもっとも注目を浴びている技術の1つであり、2014年に発表されて以降、多くの関連論文が発表されています。GAN ZooというさまざまなGANの関連論文をまとめたページによると、現在では関連論文の数は400を超えています。
GANの応用例として、線画から着色を行うPaintsChainerやGANで作曲された音楽などもあります。
GANには、 Generator ( 生成器 )とDiscriminator ( 判別器 )の2つネットワークがあります。
次の図のように、GeneratorはDiscriminatorに本物と誤認識させるような画像を生成し、Discriminatorは本物か偽物かを見分ける役割があります。2つのネットワークが敵対しながら学習していきます。よく偽札作りとそれを見分ける警察のようないたちごっこの関係に例えられます。
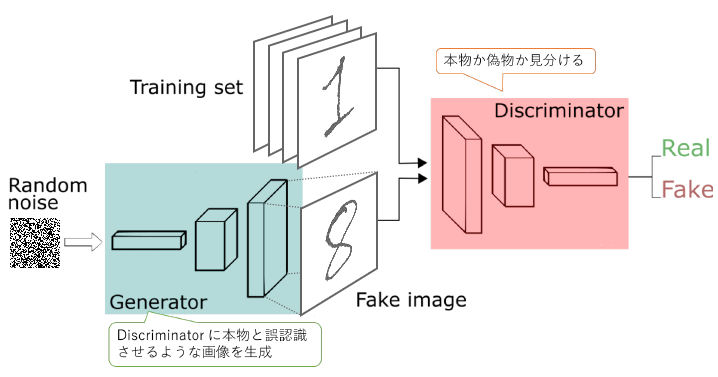
損失関数は、次のような式になります。
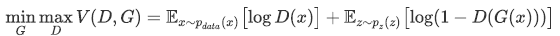
右辺の第1項は、 Discriminator が本物データを本物と判別する期待値で、第2項は偽物データを偽物と判別する期待値です。
なので、Discriminatorのネットワークは正しく判別したいので上記の式を最大化しようとしますが、逆にGeneratorのネットワークは誤認識させたいので上記の式を最小化しようとします。
DiscriminatorとGeneratorのネットワークにCNNを用いたのが、DCGANで、Generatorのネットワークは次のような構造になります。
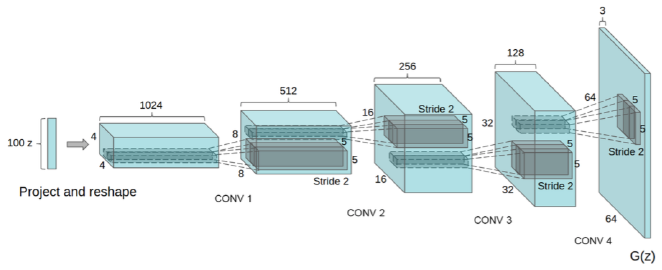
出典: Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
4.2 SRGAN
それでは、SRGANについて紹介したいと思います。
超解像の目的は、低解像度の画像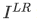 が与えられたとき、高解像度の画像
が与えられたとき、高解像度の画像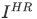 に対応する超解像画像
に対応する超解像画像 を推定することです。
を推定することです。
通常のGANではランダムノイズを入力として Generator が画像を生成していましたが、SRGANでは、を入力として Generator がを生成することに置き換えます。
次の図のように、本物の高解像度画像かGeneratorが生成した超解像画像かを見分けるように学習されたDiscriminatorを騙すようにGeneratorを学習します。
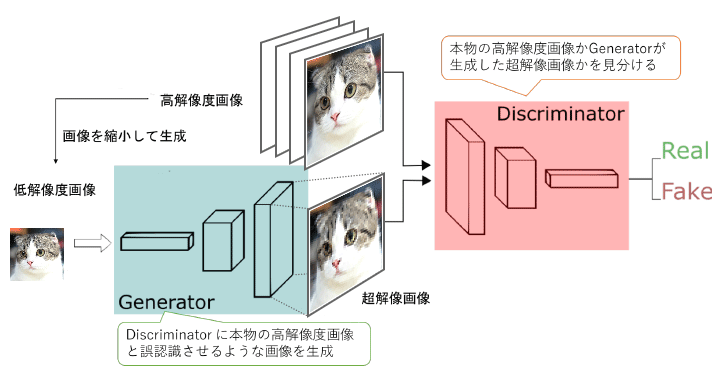
4.2.1 ネットワーク構成
GeneratorとDiscriminatorのネットワーク構成は次の図のようになります。
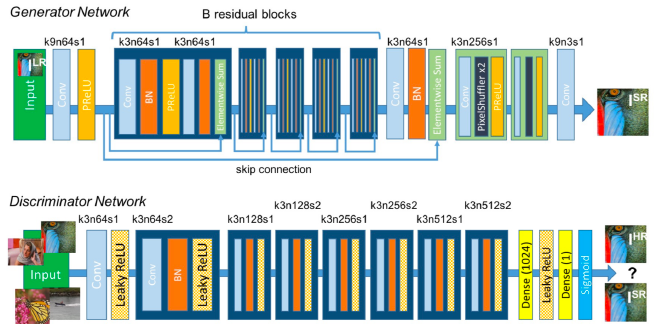
出典: Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Generatorネットワークでは、ResNetと呼ばれるネットワークが用いられています。
ResNet※7は、Residual Networkの略で、その名のとおり残差を用いたネットワークです。深いネットワークで精度が劣化する問題を防ぐため、ネットワークの残差関数を学習するよう再構成します。
いくつかの層において、直接最適な写像になるよう学習するのではなく、残差の写像が最適になるよう学習します。つまり、入力画像が求める画像になるような写像をネットワークが担うのではなく、残差画像になる写像をネットワークが行い、入力画像を足し合わせて求める画像が得られるようにします。
求める写像を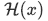 とすると、入力
とすると、入力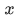 との残差は
との残差は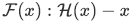 と表すことができ、元の写像は
と表すことができ、元の写像は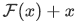 となります。これは次の図のようにショートカット接続 ( skip connection )を行うことで実現できます。
となります。これは次の図のようにショートカット接続 ( skip connection )を行うことで実現できます。
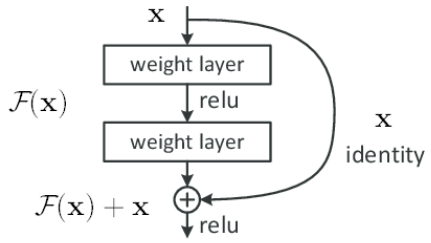
出典: Deep Residual Learning for Image Recognition
このショートカット接続を用いて複数の層を1つにまとめたものをResidualブロックと呼びます。このResidualブロックをいくつか用いたネットワークがResNetです。
4.2.2 損失関数
SRGANではより人間の感覚に近い知覚損失というもの定義しこれを損失関数に用います。具体的には、VGGベースのContent LossとGANベースのAdversarial Lossの2種類の損失関数を組み合わたものをGeneratorネットワークの損失関数とします。
MSEベースの損失関数では、画素単位の損失関数であるため、PSNRは高いが高周波成分がうまく復元できずぼやけた画像になるといった問題がありました。
そこでVGGを用いた損失を定義します。VGGもResNetと同じく有名なCNNの1つであり、ここでは事前に学習済みのモデルを利用します。
MSEベースの損失関数は、低解像度画像からGenerator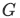 で生成された超解像画像
で生成された超解像画像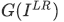 と正解画像となる高解像度画像との画素単位での誤差を求めるものでした。
と正解画像となる高解像度画像との画素単位での誤差を求めるものでした。
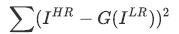
VGGベースの損失関数 ( Content Loss )では、とをVGGのネットワーク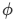 に通した出力の誤差を用います。
に通した出力の誤差を用います。
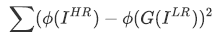
VGGのネットワークは画像分類を行う出力層まで通すのではく、中間層で得られる特徴マップを用います。CNNの中間層は画像の特徴を捉えており、これを利用することで人間の知覚に近い損失関数が定義できます。
GANベースの損失関数 ( Adversarial Loss )は、Generatorへの入力がランダムノイズからに変わるだけで通常のGANと同じです。
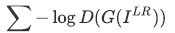
2つの損失関数の組み合わせる比率ですが、1:1ではなく1:10-3と論文に記載があります。このあたりのチューニングは結果をみて変える必要がありそうです。
4.2.3 評価
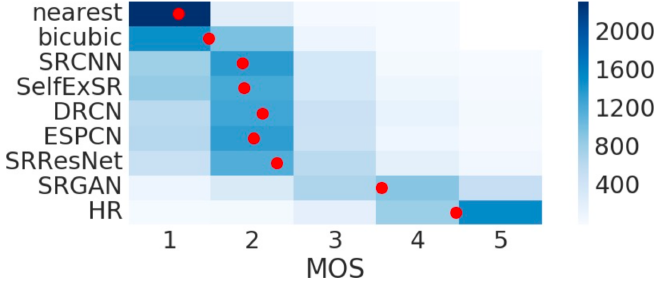
評価は、PSNRだけでなくMOS ( mean opinion score )テストによる評価を行っています。MOSテストは人間が画像の品質を5段階で評価しその平均点を用いる方法です。
結果は次の図となります。赤の点が平均点で色はサンプル数を示します。SRGANが正解画像 ( HR ) を除き最も高い値となっています。
出典: Deep Residual Learning for Image Recognition
5. まとめ
本記事では、画像拡大技術のこれまでの流れを追いながら、
1. さまざまな製品にも活用されているbicubic法をはじめとする補間法
2. ディープラーニングを用いた超解像を行うSRCNN
3. より人間の感覚に近い綺麗な拡大が可能なGANを用いた超解像を実現するSRGAN
の3点について紹介しました。
※1. 画像の品質や処理速度は相対的なものです。処理速度は遅いものでもSRCNNなどよりは高速です。
※2. Image Super-Resolution as Sparse Representation of Raw Image Patches, http://www.ifp.illinois.edu/~jyang29/papers/CVPR08-SR.pdf
※3. Image Super-Resolution Using Deep Convolutional Networks, https://arxiv.org/abs/1501.00092
※4. その他にもSSIM ( structural similarity ) といった評価指標もありますが本記事では触れません。
※5. Generative Adversarial Networks, https://arxiv.org/abs/1406.2661
※6. Very Deep Convolutional Networks for Large-Scale Image Recognition, https://arxiv.org/abs/1409.1556
※7. Deep Residual Learning for Image Recognition, https://arxiv.org/abs/1512.03385
※Macは、米国および他の国々で登録されたApple Inc.の商標です。
※Windowsは、米国Microsoft Corporationの米国、日本およびその他の国における登録商標または商標です。
※Photoshopは、Adobe Systems Incorporatedの米国およびその他の国における登録商標または商標です。