



技術解説
生成AI/LLMの開発を加速するGPUクラスタ
Vol.1【後編】インターコネクトのトポロジーとシステム構成
2024.03.12

GPUエンジニア
大野 泰弘

サーバーエンジニア
力石 誠也

ネットワークエンジニア
古賀 祥治郎

帯域をフルに使えるspine-leaf型ネットワーク
前編では、生成AI/LLM(大規模言語モデル)の開発に関して、次の二点を説明しました。
- 数百GB以上に及ぶ大規模言語モデル全体がGPUのVRAMに収まるように、マルチノード化によってVRAMの総容量を増やす必要がある
- 性能を律速する要因のひとつになり得るGPU間のインターコネクトには、RDMA(GPUDirect)がサポートされオーバーヘッドの小さいInfiniBandが最適と考えられる
最初にネットワークトポロジーを取り上げます。マルチノードGPUシステムでは、あるノードとあるノードとの通信が他のノード間通信の帯域を制約しないように、ノンブロッキングの「スパインリーフ(spine-leaf)型ネットワーク」で構成します。
図1に、spine-leafの構成例を示します。
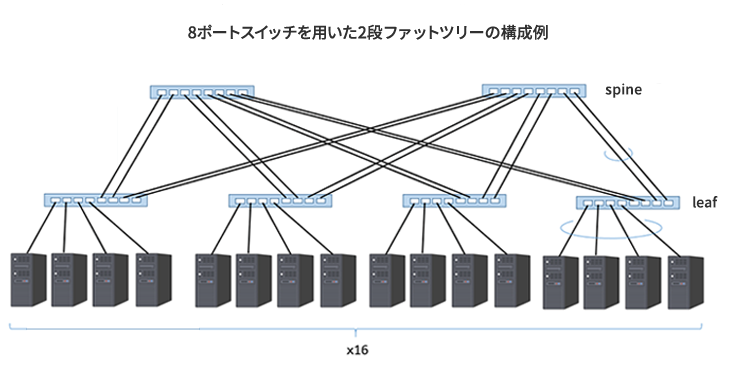
※上図はイメージです。実際には、サーバー・スイッチ間はフルメッシュで構成されます。
- リーフの1/2の台数をスパインに配置します(この例では4台:2台)
- リーフスイッチに接続されているノード数の1/2のケーブル数で、リーフとスパインのスイッチを接続します。
このような構成によって、たとえば任意のノードと任意のノードが通信を行っているときに、別のノードと別のノードとが帯域を制限されることなく同時に通信を行うことができます。
マルチノードGPUシステムの構成例
続いて、マルチノードGPUシステムを、ベアボーンサーバーを用いて組む場合と、NVIDIA DGX™ H100で組む場合について説明します。
(1) ベアボーンサーバーを用いる場合
SSuperMicroやDell、HPE、GIGABYTEなどのメーカーがNVIDIA H100 TensorコアGPUに対応したベアボーンサーバーを提供しています。ベアボーンで組むメリットは、性能、予算、設置スペース(ラック搭載高さ)などを考慮して、プロセッサー種別やメモリ容量を含め、さまざまな選択肢の中からカスタマイズが行えることです。
インターコネクトはPCIeスロットにInfiniBand HCA(Host Channel Adapter)を実装して構成します。搭載するGPU個数と同じポート数のInfiniBand HCAを揃えるのが性能的には理想ですので、ベアボーンの選定にあたってはPCIeのスロット数も重要です。
| ベアボーン |  |
|---|---|
 |
|
| GPU |  前述の8Uのベアボーンサーバー(AS-8125GS-TNHR/SYS-821GE-TNHR)の場合はSXMフォームファクター品、2Uのベアボーンサーバー(ARS-221GL-NR/SYS-221GE-NH)の場合はPCIeデュアルスロットフォームファクタ品を選択します。 |
| InfiniBand HCA |  ConnectX-7には、Infiniband NDR(400Gbps)品以外に、InfiniBand HDR(200Gbps)品などが展開されています。InfiniBand NDR対応品のSKUは、900-9X766-003N-SQ0(cryptなし)または900-9X766-003N-SR0(cryptあり)です。 |
| InfiniBandスイッチ |  2階層のスパインリーフの場合、前述の構成ルールに従えば、エッジ層のQuantum-2 QM9700の64ポートのうち、半分である32ポートをノード(GPU)の接続に、残り32ポートをコア層のQuantum-2 QM9700との接続に使用します。 |
| ケージ/トランシーバモジュール | 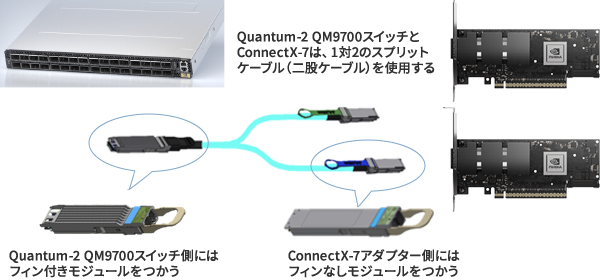
|
(2) DGX H100を用いる場合
NVIDIA DGX™ H100はNVIDIAが提供するきわめて強力なGPUサーバーで、ハードウェア、インターコネクト、およびソフトウェアともにセットアップされているため、最高クラスの性能が得られるとともにデプロイ期間の短縮が図れます。
ただし、ベアボーンサーバーで組む場合とは異なり、カスタマイズはできません。
| 本体 |  |
|---|---|
| GPU | SXMフォームファクターのNVIDIA H100 TensorコアGPUが8個搭載されています。 |
| InfiniBand HCA | ソケットダイレクト型のConnectX-7が8個搭載されています。
 ベアボーンサーバーで使用するPCIeフォームファクターのConnectX-7 HCAのOSFPコネクタは400Gbps×1ですが、DGX H100のOSFPコネクタは各コネクタあたり400Gbps×2となっているため、後述するように手配すべきケーブルが異なります。 |
| InfiniBandスイッチ |  |
| ケージ/トランシーバモジュール | 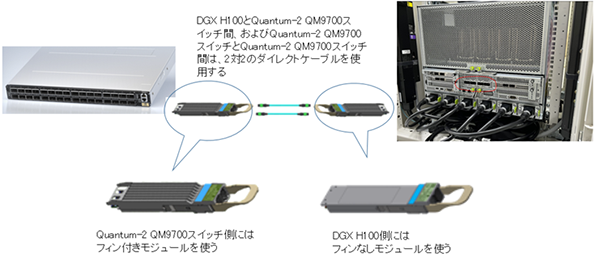
|
このようにインターコネクトの構成設計や選定は意外と面倒で、手配でもミスが生じやすいため注意が必要です。もちろんNTTPCでもご相談を承っています。
ノード内インターコネクトである「NVLink」がノード間にも拡張
本稿では触れませんでしたが、ノード内のGPU間のインターコネクトにはNVIDIA独自のNVLinkを使用します。NVIDIA H100 TensorコアGPUに対応した第4世代のNVLinkのデータレートは900GB/sときわめて高速です。なお、NVIDIAは2023年の国際学会「Hotchips」でNVLinkをノード内だけではなくノード間にも拡張するNVLinkとNVSwitchを発表しました。発売時期は発表されていませんが、いずれNVLinkとNVSwitchがノード間インターコネクトの標準になるかもしれません。
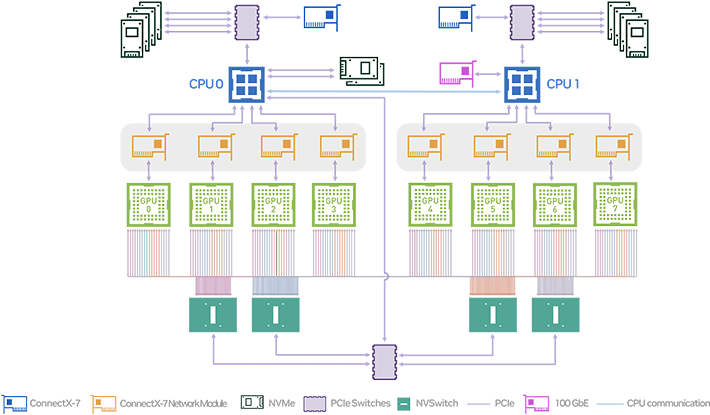
ノード内のGPU間を結ぶNVIDIA独自のNVLink(緑色の線)
出典元:NVIDIA DGX H100 System User Guide
外部ストレージとの接続は、専用のネットワークを用意しよう
ストレージシステムの構成やノードとの接続方法もシステム性能に影響を与えます。大規模言語モデルの開発において、外部ストレージは、学習用データセットや言語モデルの保存、トレーニング中の言語モデルのスナップショットの保存、データのノード間での共有などの役割を担います。
ストレージをハードディスク(HDD)で組むかNVMeなどのオールフラッシュ(NVMeなど)で組むかによってコストは大きく異なります。もちろん性能的にはオールフラッシュをお勧めします。その理由は、これまでも述べてきたように、もっとも重要な計算リソースであるGPUの利用率をできるだけ高く維持できるからです。
各ノードとストレージとの接続にはEthernetまたはInfinBandを使います。性能面ではやはりInfiniBandがお勧めですが、インターコネクトのInfinibandとはチャネルを分けて構成する必要があります。
ちなみにNVIDIAは、NVIDIA DGX H100に接続するストレージ製品のベンダーとして、PureStorage、ddn、VAST、NetApp、IBM、WEKAを推奨していますが、これら以外のベンダーの製品でももちろんかまいません。
外部ストレージの選定はややもすると後回しになりがちです。予算の配分を含めて、できるだけ早い段階で検討されることをお勧めします。
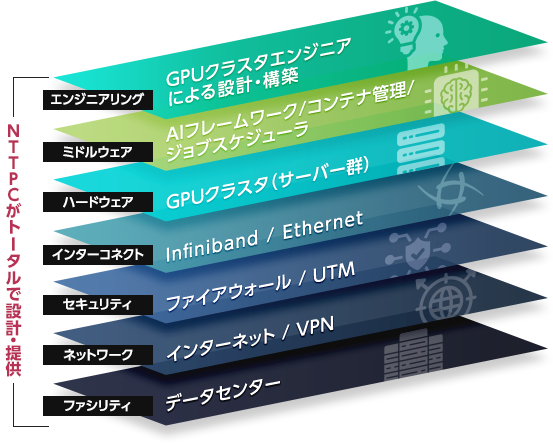
インターコネクトのまとめとNTTPCの強み
以上、前編と後編の2回にわたって、生成AI/LLM(大規模言語モデル)の開発に最適なマルチノードGPUシステムとインターコネクトについて紹介しました。繰り返しになりますが、マルチノードGPUシステムでは、GPUというもっとも重要でもっとも貴重なハードウェアリソースをいかに効率的に使うかが鍵になります。
その意味で、GPU間を結ぶインターコネクトにはできるだけオーバーヘッドの小さいテクノロジーを選択することが望ましいためInfiniBandがお勧めです。
NVIDIAのエリートパートナーであるNTTPCは、これまで1,200台以上のGPUサーバーを提供してきた実績を持っていますが、特にここ最近では生成AI/LLMの開発を対象にしたマルチノードGPUシステムが増加している状況です。実績の一部をご紹介します。
- NTT人間情報研究所:2023年11月に発表された、日本語に強く軽量・マルチモーダルが特長のNTT版LLM「tsuzumi」の研究開発基盤
- Spiral.AI株式会社:生成AI/LLMに特化したAIスタートアップで、独自言語モデルの開発基盤としてGPUクラスタを構築
- コンテンツプロバイダ:ヒューマンインタラクションをテーマとした研究所における言語 モデルの開発基盤
- 自動運転スタートアップ:LV5の実現に向けたマルチモーダルな独自言語モデルの開発基盤
また、NTTPCはキャリアとして30年以上のデータセンター運営も行っているため、電源、冷却、ラッキング、保守運用などのノウハウも持っています。特に、マルチノードGPUにおいて「設置環境」は非常に重要な要件となりますので、ラック/電力設計の観点からシステム構成を組める点は、NTTPCが選ばれる大きな理由となっています。
次回はGPUクラスタの運用管理に必要なNVIDIAソフトウエアについて解説します。