



基礎知識
生成AI/LLMの開発・学習に欠かせないGPUクラスタについて
2025.04.18

GPUエンジニア

学習済みの「基盤モデル」を使って、文章、画像、映像、音声などを生成する「生成AI」が私たちの社会や暮らしに急速な勢いで浸透しています。ChatGPTのような対話型の人工知能チャットボット、AI翻訳サービス、自動生成されたイラスト、合成された音声などのさまざまな生成物がビジネスで活用されるケースも増えています。
この生成AIはどんなコンピューティング環境で動いているのでしょうか?今回は、生成AIのトレーニング・開発に欠かせない「GPUクラスタ」について解説します。
生成AI/LLMにおいて欠かせないインフラとしてのGPUクラスタ
生成AIアプリケーションを実現しているのが「基盤モデル」です。基盤モデルのうち、自然言語の生成に特化したモデルを「大規模言語モデル(LLM:Large language Models)」と呼びます[*1]。LLMは学術論文やインターネット上の情報などの大量のテキストデータを使ってトレーニングされています。このLLMに、自然言語による入力(プロンプト)を与えて、文章、要約、プログラムなどを出力させる機能を持たせたものが、たとえばChatGPTなどの生成AIアプリケーションです。生成AIとLLMはときには混同して使われがちですが、その違いを図1に示します。
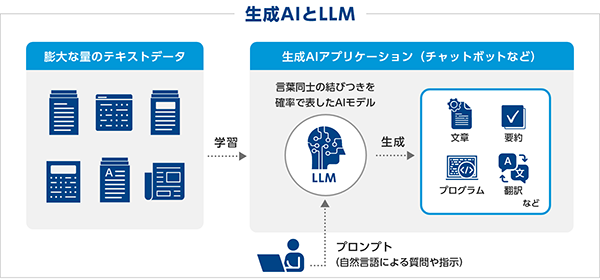
図1. 生成AIとLLMの関係。生成AIアプリケーションの一部を構成するのがLLM。
プロンプトを与えると、文章、プログラム、要約文などが生成される。
基盤モデルを開発するには膨大な計算量が必要です。LLMの場合、あらゆる単語を対象に、次に現れる単語の出現確率を求めます。その計算に適しているのが行列演算性能の高いGPUです。大規模な基盤モデルのトレーニングでは、NVIDIA B200 Tensor Core GPUや、NVIDIA H200 Tensor Core GPUなど、高いメモリを有するGPUを複数枚搭載したサーバーが用いられています。
しかし、モデルサイズが大きくなると、複数枚の高性能GPUを搭載したサーバーであっても、計算時間が非常に長くなるケースが出てきます。
そうした課題を解決するのが、複数のGPUサーバーを並列に構成してさらなる高速化を実現する「GPUクラスタ」(図2)なのです。

図2. 複数のGPUサーバーで構成した「GPUクラスタ」
実例を挙げてみましょう。Meta社が提供している言語モデル「LLaMA-65B」(650億パラメータ)のトレーニングには、NVIDIA A100 TensorコアGPUを2,048基使って21日間を要したと言われています[*2]。また、パラメータ数が1.8兆と推測されているOpenAI社の「GPT-4」を作るには、25,000基のNVIDIA A100 TensorコアGPUを使って90日から100日もの時間が必要だったとの情報もあります[*3]。
逆に言えば、こうしたLLMのトレーニングを1台のGPUサーバーのみで行おうとすると年単位の時間が掛かってしまうわけで、とても現実的ではありません。その意味でGPUクラスタは、基盤モデル開発における必須のインフラと言えるでしょう。
また、「混合専門家(MOE:Mixture-of-Experts)モデル」、「ファインチューニング」、「検索拡張生成(RAG:Retrieval-Augmented Generation)」など、計算パワーを求められる研究や開発にも好適です。そのほか、GPUクラスタは、構造解析、流体解析、宇宙物理、原子力工学、分子動力学、量子科学、材料工学、気象解析など、生成AI以外の機械学習などの用途でも使われています。
[*1] 基盤モデルのうち自然言語に特化したモデルを大規模言語モデルと呼ぶことが一般的ですが、基盤モデルと大規模言語モデルとはそもそも定義が異なるという見方もあります。
[*2] https://ai.meta.com/blog/supercomputer-meta-research-supercluster-2023/
[*3] GPT-4のリーク情報が https://semianalysis.com/2023/07/10/gpt-4-architecture-infrastructure/ の有料部分に掲載され、Xなどで拡散されました。
大規模言語モデル(LLM)とGPUクラスタ
LLMを含む大規模基盤モデルの開発では、計算量を増やせば増やすほど、トレーニングデータサイズを大きくすればするほど、パラメータ数を増やせば増やすほど、優れたモデルが得られることがOpenAIでの研究による経験則(スケーリング則)として知られています[*4][*5]。
2025年現在は、小量のデータセットや少ないパラメータで精度の高いLLMを開発したり、推論処理が軽くて済む小規模言語モデル(SLM:Small Language Models)を開発する動きも盛んですが、大まかな方向としては「物量勝負」と考えて間違いないでしょう。
計算資源がとにかく欲しい、あればあるだけいい、というのが研究者や開発者のニーズであり、それに応えられるのが大規模なGPUクラスタと言えます。性能の高さを生かして、複数の基盤モデルをトライアンドエラーで開発して評価したり、複数のプロジェクトチームが並行して利用することも可能です。
GPUクラスタのもうひとつのメリットが、多くのGPUメモリ容量を確保できることです。トレーニング用データのほか、トレーニングの過程で生成される中間ファイル、最終モデルなど、すべてをGPUメモリ上に置くことで、性能を低下させる要因のひとつであるCPU側メモリとの転送ボトルネックを抑えられます。
たとえば、1,750億パラメータのGPT-3のトレーニングデータサイズは570GB、モデルの大きさは800GBと言われています。中間ファイルなどを考慮しなくても、両者だけで1.4TBのGPUメモリが必要です。
もちろん、GPUのメモリサイズは世代とともに大きくなっています。たとえば、GPT-3が開発された当時に最新だったNVIDIA V100 Tensor Core GPUのGPUメモリ容量は32GBでしたが、現在のNVIDIA H200 Tensor Core GPUでは141GBに、NVIDIA B200 Tensor Core GPUでは192GBに拡張されています[*6]。
しかし、NVIDIA B200 GPUを8基搭載したGPUサーバーでもGPUメモリの総容量は1.5TB(192GB×8)にしかなりません。さらに大容量のGPUメモリが必要な用途で利用する場合、メモリを確保する方法がGPUクラスタなのです。
[*4] Scaling Laws for Neural Language Models (J.Kaplan, S.McCandlish, et al., 2020)
[*5] 計算量を増やして学習時間を長くすればするほどモデルの精度が上がる、というスケーリング則は、最近では限界にきているという説もあるようです。
参考:https://garymarcus.substack.com/p/a-new-ai-scaling-law-shell-game
[*6] NVIDIA GPUには帯域幅の広いメモリ(HBM:High Bandwidth Memory)がチップレベルで実装されている。CPU側のメインメモリを介さずにすべての処理をGPUメモリ上で実行することが性能的には理想。
GPUクラスタを構築する技術的ポイント
性能的にはメリットの多いGPUクラスタですが、構築や運用は決して簡単ではなく、サーバーハードウェア、ネットワーク(インターコネクト)、ストレージ、セキュリティ、冷却や空調、電力、設置、システム管理など、幅広い分野の知識と経験が求められます。
なんといっても単体のサーバーを導入する場合に比べて費用が高くなります。数千万円~規模によっては数百億円を超えることもあります。たとえば、国立研究開発法人 産業技術総合研究所が2025年1月に提供を開始した国内最大規模のGPUクラスタ「ABCI 3.0」[*7](NVIDIA H200 SXM5 TensorコアGPU×6,128基)の調達額はおよそ350億円だったそうです。
予算をはじめとするさまざまな制約の中でいかに性能を最大化するか、および、開発者や研究者などのユーザーにとっていかに使いやすいシステムを作るかが、クラスタ設計者にとっての腕の見せ所と言えるかもしれません。
ハードウェア的には、性能や調達性を考慮してGPUは何にするか、サーバー筐体はどのメーカー・型番を選定するか、設置環境をふまえ、冷却方式は水冷 or 空冷、インターコネクトには何を使うか、ネットワークトポロジーはどうするか、ストレージはどのぐらいの容量を用意するか、などがポイントになるでしょう。
システムの運用管理も課題のひとつです。サーバーのプロビジョニング、ログの収集や稼働監視、ソフトウェアのバージョン管理、セキュリティ対策、エラー発生時の切り離し、リソースの分割、ジョブのスケジューリング、負荷調整、ユーザー管理など、やるべきことはたくさんあります。
また、実行環境を構成するにはコンテナを使う方法が効率的であり、コンテナ管理ツールであるKubernetesなどの活用も必要です。
本来の目的である基盤モデルの開発に集中するために、GPUクラスタの構築や運用を外部に委託する方法もあります。
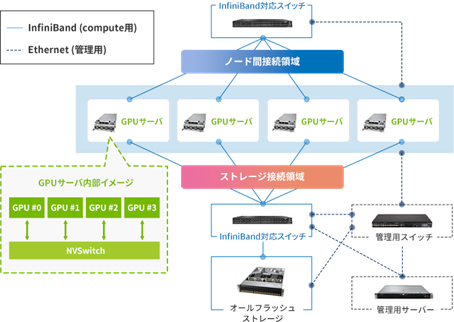
図3. GPUサーバー4台で構成したGPUクラスタの例
なお、GPUクラスタの構築、インターコネクト、運用管理、およびKubernetesを使ったコンテナ環境の構築に関する技術的な説明は、過去に公開したコラムで詳しく解説していますので、合わせてご参照ください。
生成AI/LLMの開発を加速するGPUクラスタに関連する記事
- Vol.1【前編】マルチノードGPUシステムとインターコネクト
- Vol.1【後編】インターコネクトのトポロジーとシステム構成
- Vol.2:NVIDIA Base Command Manager ™ によるGPUクラスタの運用管理
- Kubernetesを使ってGPUサーバークラスターを構築してみた
[*7] https://monoist.itmedia.co.jp/mn/articles/2501/24/news099.html
GPUクラスタの活用事例
GPUクラスタは、前述した産業技術総合研究所の「ABCI 3.0」のほか、いくつかの大学が導入しています。
また、GPUクラスタを提供する国内のデータセンター事業者も増えています。
民間企業では、完全自動運転の実現を目指すTuring(チューリング)株式会社、IQではなく「EQ」重視のLLMを開発するSpiralAI株式会社、軽量でマルチモーダルな国産LLM「tsuzumi」を開発したNTT人間情報研究所などがGPUクラスタを導入し、独自LLMの研究開発や生成AIサービスの提供に活用しています。
外部のGPUクラウドサービスを利用するのではなく自社でGPUクラスタを持つことには、外部サービスに制約されず必要な計算資源を確保しやすい、自社のニーズに合わせた構築や運用が可能、などのメリットがあり、活用の自由度を高めて企業としての競争力強化につなげています。
NTTPCのGPUクラスタ導入事例
まとめ
本記事では、複数のGPUサーバーを並列化したGPUクラスタについて、大規模言語モデル(LLM)を含む基盤モデルの開発に適しており、きわめて高い性能を実現できることや、構築のポイント、活用事例などを説明しました。
生成AIが社会に大きな影響を及ぼしつつある今、基盤モデルを中心とした生成AI関連技術は国家レベルの競争力を左右するほど重要という見方もあります。日本政府も「AI戦略会議」の中で、生成AIの開発力強化を重点施策として打ち出していて、その一環として計算資源の増強が重要であると唱えています[*8]。
基盤モデルの研究開発や生成AIを活用した新しいアプリケーションの創出を進めるためにも、GPUクラスタは今後ますます重要になってくるでしょう。
GPUクラスタの導入をお考えの方は、実績に裏打ちされた設計・構築ノウハウを持つNTTPCにご相談ください。
[*8] 令和6年版科学技術・イノベーション白書 第2章「我が国におけるAI関連研究開発の取組」(2024年)、内閣府 AI戦略会議 第9回資料「AI戦略の課題と対応」(2024年5月)、など