



技術解説
SlackとGitlabでのデータ分析プロセス
~ KaggleのWSDM Cup 2018への参加を例に ~
2018.05.31

サービスクリエーション本部
データサイエンティスト
組橋 祐亮

データ分析コンペティションサイトKaggleで開催されたWSDM Cup 2018に2名のチームで参加したので、そのとき得られたデータ分析プロセスに関するノウハウを紹介します。
<Kaggle と WSDM Cup>
Kaggleとは
まずはじめにKaggleについてですが、Kaggleは2017年にGoogleが買収した世界最大のデータ分析コンペティションプラットフォームです。世界中で50万人以上のデータサイエンティストが利用しているそうです。
コンペティションの中には企業が主催し優秀者に賞金(優勝賞金100万ドルのコンペティションが開催されたこともあります)を出すものがあれば、今回のWSDM Cupのように、国際会議に併設されるものあったりします。日本では、リクルートやメルカリがコンペティションを主催していました。
参加者同士で、コンペティションに関するディスカッションやコードを共有する場もあり、他の参加者の考え方ややり方を閲覧するだけでも、勉強になります。
Kaggleとデータ分析プロセス
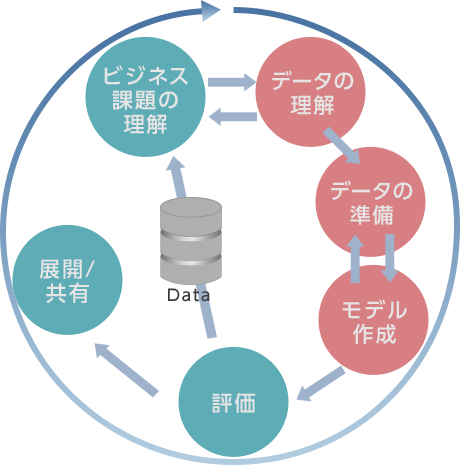
Kaggleでは、事前にデータと課題が与えられており、評価基準も決まっているので、データ分析プロセス(CRISP-DM)でいうところの、「データ理解」「データ準備(特に前処理)」「モデル作成」の3つを中心に行うことになります。
WSDM Cup 2018
今回、取り組んだWSDM Cup 2018は、Web検索とデータマイニング分野のトップカンファレンスであるWSDMが主催するコンペティションです。
WSDM Cup 2018では、台湾を中心として、主にアジアで展開されている定額音楽配信サービスのKKBOXがデータを提供しており、
- 解約予測
- ユーザUが購読期限後に、解約するかどうかの2クラス分類問題
- 音楽レコメンド
- ユーザUが1度聞いた音楽Xを1ヵ月以内に再び聞くかどうかの2クラス分類問題
- AUCで評価
の2種類の課題がありました。このうち、音楽レコメンドの方に参加し、約1ヵ月半取り組みました。
<データ分析プロセス>
全体の流れ
今回の分析の全体の流れは次のとおりです。
- 準備
- チーム内で方針の策定や環境の準備
- データ理解
- データの可視化などで、データの特徴を理解
- データ準備(前処理)
- 検証用のベースモデルとベースデータを決定
- いろいろ特徴量を作って試す
- モデル作成
- 作った特徴量から良い特徴量を選択
- パラメータチューニング
- アンサンブル
準備
チーム内のコミュニケーションとしては、原則Slack上で行うこととし、コード管理とタスク管理にはGitLabを用いることにしました。
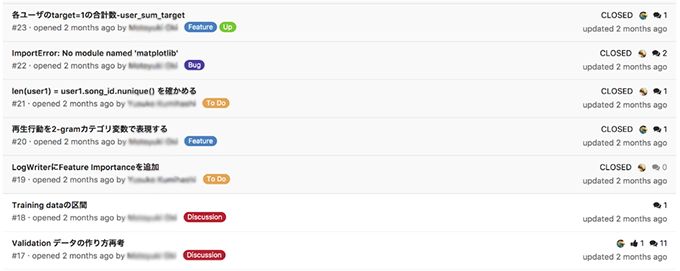
GitLabのIssueでは、
- タスク
- バグ
- ディスカッション
- 特徴量の検討
などをタグで区別し、まとめて管理しました。
また、SlackとGitLabを連携させ、Slackだけを確認すれば済むようにしました。
比較的データサイズが小さいコンペティションであったため、共通の分析環境は用意せず、個別の環境で分析を実施しました。
データの前処理(特徴量作成)
特徴量の作成(Feature Engineeringともいいます)は、データ分析において最も重要なプロセスの1つで、分析精度に大きく影響します。今回の分析でも特徴量作成に全体の50%以上の時間を費やしたと思います。
新しく考えた特徴量を加えた場合、ベースとなるスコアより上がったか下がったかをもとにその特徴量の有効性を検証します。ベーススコアは、固定したベースモデルとベースデータで計算します。
ベースモデルは、seed値含めてパラメータを固定したXgboostを採用しました。ベースデータには、主催者側が用意したデータ(4つのファイルに分かれているので、マージ)をTrain / Validationデータに分割し、pickle化しました。また、全く同じ結果になるようにデータの行と列の並び順をソートして固定しました。
このように、複数人で分析する場合は、だれが実行しても同じ結果になるようにする必要があります。
ちなみに、ベーススコアは次のようになりました。
train auc:0.832, valid auc:0.688
特徴量作成の流れは次のようになります。
- GitLabのIssueを起票
- 特徴量の実装
- 実装した特徴量を追加して学習
- 結果をIssueに投稿
- コードのマージとディスカッション
次に、それぞれについて簡単に紹介します。
Issue起票
ディスカッションして洗い出したり、各々がデータを眺めながら有効そうな特徴量を考えます。そして、管理しやすいように、特徴量1つにつきIssueを1つ起票します。
特徴量の実装
考えた特徴量を実装します。特徴量の部分以外は共通のコードを用いるようにしたので、ここで実装する内容は、データ(pandas形式のtrainとtest)を受け取って、特徴量を1列追加した返す関数のみです。
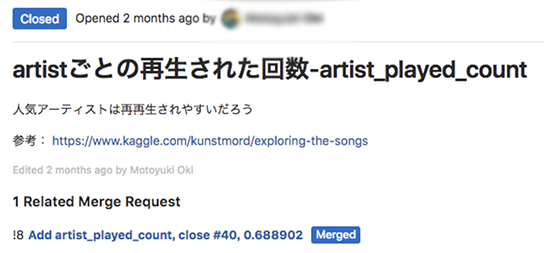
「artistごとの再生された回数」といった特徴量を追加するコード例は次のようになります。
import pandas as pd
class ArtistPlayedCount(object):
def get_feature(self, train, test):
train_size = pd.DataFrame(
{'artist_played_count': train.groupby('artist_name').size()}).reset_index()
train = train.merge(train_size, on='artist_name', how='left')
test_size = pd.DataFrame(
{'artist_played_count': test.groupby('artist_name').size()}).reset_index()
test = test.merge(test_size, on='artist_name', how='left')
features = {
'artist_played_count': (train['artist_played_count'], test['artist_played_count'])}
return features
学習
学習に用いる特徴量が記載された設定ファイルを書き換え、
python train_xgb.py
のように、学習コードを実行して待つだけです。
学習コードでは次の内容を行っています。
- ベースデータの読み込み
- パラメータの読み込み
- パラメータは、Xgboostのパラメータやどの特徴量を使うかなど
- データの前処理(特徴量の追加や選択)
- 特徴量の追加は、getattr()をつかって個別の関数を呼ぶ
- Xgboostで学習
- 結果の出力
結果は、再現できるように / 管理しやすいように、1つのフォルダに、用いたパラメータ、学習過程のスコア、学習済みモデル、submissionファイルなどを格納します。学習済みモデルは、保存したけど後から使うことはありませんでした。
result/20171130T230258 ├── args.json # 実行時の引数 ├── command.txt # 実行時のコマンド ├── result.json # 学習結果のスコア ├── submission.csv.gz # kaggleへ投稿する用のsubmissionファイル ├── xgb.model # 学習済みモデル(バイナリ) ├── xgb_fscore.json # 特徴量ごとのスコア ├── xgb_fscore.png # 特徴量ごとのスコアを可視化した画像 └── xgb_params.json # xgboostのパラメータ
学習
学習が終わったら、結果をIssueに投稿します。
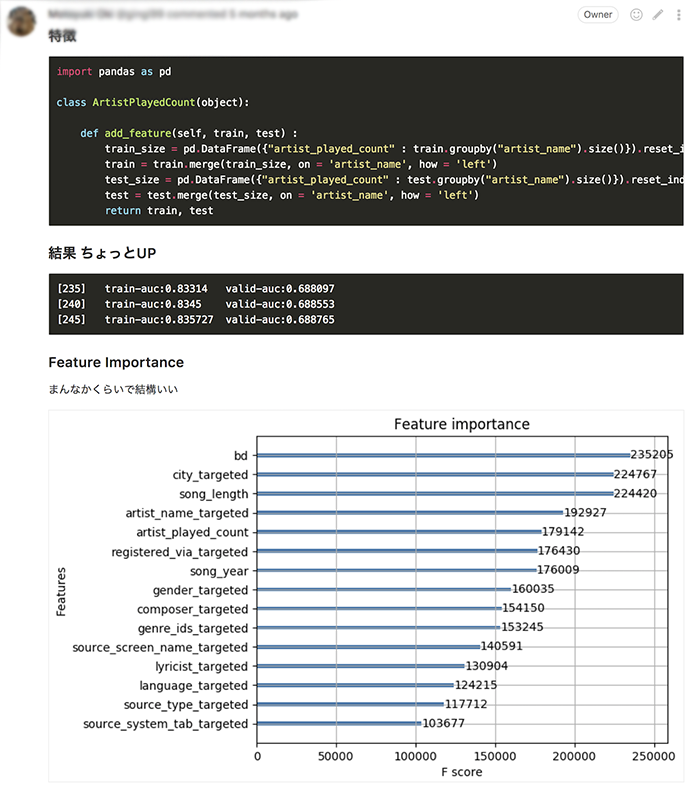
コードのマージ
結果の他に、特徴量を追加するコードや結果をプッシュし、別のメンバーが確認してマージします。コミットメッセージにスコアを書いておくと分かりやすいです。
モデル作成
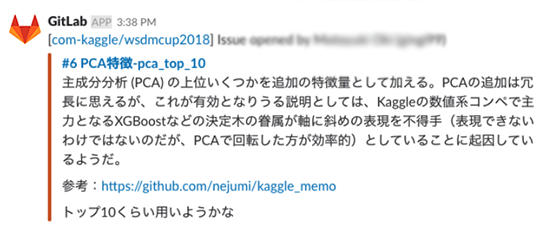
特徴量の作成が終わったら、モデルの作成に入ります。まず、有効な特徴量を選択します。今回作成した特徴量のうち、ベーススコアより上がった特徴量は46個であり、有効な特徴量の組み合わせを全通り(246246)調べるのは現実的ではありません。そこで、次のように確率的に選択する手法をとりました。
- すべての特徴量を Faとし、追加する特徴量の数m ( 1≤m≤|Fa| ) をランダムに決める
- 各特徴量の確率に基づき、 m 個を学習に用いる特徴量 Ft とする
- 確率は、すべての特徴量Faから、fiが選ばれる確率(fiのスコア)/(∑fiのスコア) とする
- スコアは、XgboostにおけるFeature importanceの値を用いる
- FtFt を用いて学習
- 1.~3.を繰り返す
次に、選ばれた特徴量を用いて、Xgboostのパラメータチューニング行いました。最後に、seed値を変えて複数の実験を行い、その結果の平均を最終的な出力(アンサンブル)としました。
また、最終的なフォルダ構成は、次のようになりました。
.
├── README.md
├── config
│ ├── base_data.yaml.example
│ ├── feature_scores.yaml.example
│ ├── use_features.yaml.example
│ ├── xgb_params.yaml.example
│ └── xgb_params_grid.yaml.example
├── create_base_data.py
├── create_ensemble.py
├── create_score_file.py
├── data
├── notebooks
├── requirements.txt
├── result
│ ├── 20171128T225710
│ ├── 20171129T224104
│ ├── 20171130T093356
| ...
├── train_xgb.py
└── src
├── __init__.py
├── feature_selector.py
├── features
│ ├── __init__.py
│ ├── artist_played_count.py
│ ├── count_encode.py
│ ├── days_membership.py
| ...
├── log_writer.py
├── target_encoder.py
└── target_sum_encoder.py
<まとめ>
KaggleのWSDM Cup 2018への参加を例に、データ分析プロセスの実例について紹介しました。最終結果は352/1081(Top33%)と、少し残念な結果に終わってしまいしたが、タスクの共通化/自動化や管理方法などに試行錯誤しながら取り込むことで、ノウハウを蓄積することができました。