



技術解説
ディープラーニングで
“道路のひび割れ”を検知する
2018.10.25

サービスクリエーション本部
アプリケーションエンジニア
石井 誉仁

1. はじめに
最近では、AI や Deep Learning というキーワードをよく耳にするようになり、Deep Learningの仕組みについて理解されている方も増えてきていると思います。
一方で、「どんな課題が解決できるのか」「どんな領域に適用できるのか」と言ったDeep Learningの活用方法については、具体的なイメージが浮かばないという方も多いのではないでしょうか。
そこで、今回は Deep Learning の技術を活用した事例として、画像における“道路のひび割れ検知”の実現について紹介していきます。
2. モチベーション
今回、事例として紹介する“道路のひび割れ検知”ですが、このテーマを設定した理由について簡単に説明します。
国や地方自治体が管理している道路ですが、1970年代の高度経済成長時代に集中的に整備されてきました。それから半世紀以上が経過した道路は経年劣化による老朽化が進み、交通事故の原因となるポットホール ( pot hole ) が発生しがちです。
そのため、道路の表面を形成する舗装において、継続的なメンテナンスサイクルを確立し、より効率的に管理していくことが求められていますが、現実には舗装点検に関する統一的なデータの取得が行われておらず、適切な予防保全および修繕の取り組みも十分に行われていないのが実情です。
特に地方自治体に関しては、財政的な制約が年々大きくなっている背景もあり、道路の保全や修繕のための継続的な点検を十分に行うことができないという課題を抱えています。
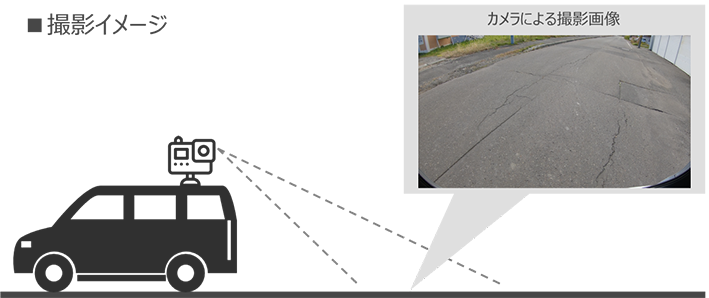
そこで、我々は一般的に市販されている比較的安価なカメラを利用して道路の画像を撮影し、画像から道路の状態を可視化・把握することによって、コストをかけずに統一的かつ継続的な点検の実現を目指していきたいと考えるようになりました。
3. 目指したゴール
“道路のひび割れ検知”というテーマに対して、地方自治体の実務担当者が求める課題は大きく2つあると我々は考えました。それは次の2点です。
- 高いコストをかけずに、継続的に道路の状況を把握する
- 限られた予算の中で道路を修繕するため、優先的に対応すべき道路を把握する
1つ目の課題に対しては、モチベーションの項でも少し述べたように、一般的に市販されているカメラで撮影する動画像から道路の路面状況を分析して状態を把握することができれば解決できると考えました。
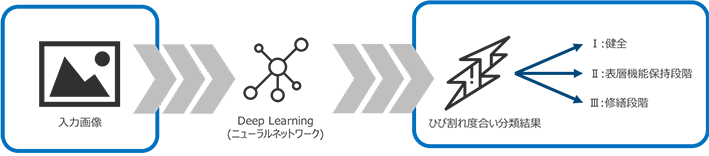
そこで、Deep Learningの技術によって画像中から道路のひび割れ箇所を検出することを試みました。
2つ目の課題は、ひび割れ箇所を検出して可視化するだけでは道路の専門家でもない限り次へのアクションへ繋がらない、つまり、ひび割れ度合いを定量的に判断して「対処すべきか否か」を提示しなければ管理者が判別しなければならず、管理者の負担が大きいと考えました。
そこで、平成28年に国土交通省によって制定された舗装点検要領[1] *に従い、ひび割れ度合いの損傷評価を3段階で分類することによって管理者にとって有益な道路状況把握を実現し、限られた予算の中での優先的に対応するべき道路の把握を実現することを試みました。
次に、舗装点検要領に記載してある分類区分をまとめておきます。
| 判定区分 | 説明 | 損傷イメージ |
|---|---|---|
| I:健全(ひび割れ率0 ~20%程度) |
・ひび割れの発生が認められない:0% ・縦断方向に1本連続的に発生:10% ・左右両輪の通過部で縦断方向に1本ずつ連続的に発生:20% ・評価単位区間内で片側の車輪通過部で複数本又は亀甲状に発生:20% |
 |
| II:表層機能保持段階 (ひび割れ率20~ 40%程度) |
・ひび割れが左右両輪の通過部で発生し、かつ片側の車輪通過部ではひび割れが縦横に派生するなど複数本発生:30% ・ひび割れが左右両輪の通過部で発生し、かつ片側の車輪通過部ではひび割れが亀甲状に発生:40% |
 |
| III:修繕段階(ひび割 れ率40%程度以上) |
・ひび割れが左右両輪の通過部でそれぞれ亀甲状に発生:50%~60% ・ひび割れが車線内全面に渡り亀甲状に発生:概ね80~100% |
 |
上記2つの課題を解決するというゴール設定について説明したので、道路画像を入力として与えると、国土交通省が提示している分類指標が出力されるという仕組みの実現を目指していきます。具体的な実現方法については次から解説していきたいと思います。
4. データの準備
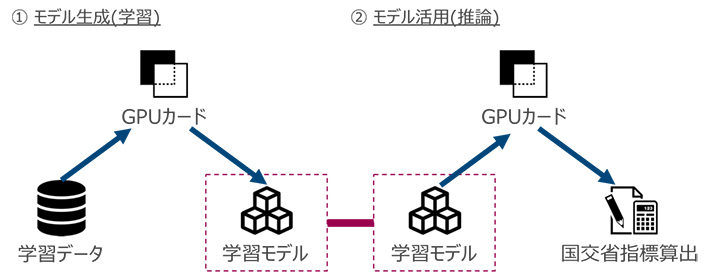
入力画像から道路のひび割れを検出するためには、 Deep Learning による学習モデルの生成を行う必要があります。そして、生成された学習モデルを利用して画像中のひび割れを検知する推論を行います。
Deep Learning の学習には大量のデータが必要であることは皆さんすでにご存知のことかと思います。今回は実際に道路の動画を撮影することでデータを収集し、ひび割れや道路を撮影した動画のフレーム画像からデータセットを作成して準備しました。ひび割れを検知するモデルを作成するのに利用したデータセットは次になります。
| クラス分類 | データ数 | アノテーションラベル |
|---|---|---|
| 正常道路 | 20000枚 | 0 |
| ひび割れ道路 | 20000枚 | 1 |
| その他 | 20000枚 | 2 |
また、今回は学習モデルの精度評価をするのとは別に、学習モデルを組み込んだ検知プロセス全体 ( 検知プロセスについては後述します ) の精度評価を行う必要があります。そのため、上記のデータセットとは別に国土交通省の評価基準に従って、人手で分類した300枚の正解ラベル付きテストデータセットを用意しました。
この点に関して、ニューラルネットワークの出力層の値を国土交通省の指標にすればよいのでは? との声が聞こえてきそうですが、正解ラベルを付与する際の正確性を担保できなかったために、ひび割れかどうかの分類を出力結果としています。
それでは、これらのデータセットを活用して実際に構築した検知の仕組みについて次項で説明していきます。

5. 検知プロセス
今回の検知プロセスですが、次のようなプロセスでひび割れ検知を実現しています。大きく分けて2段階の構成を採用しています。
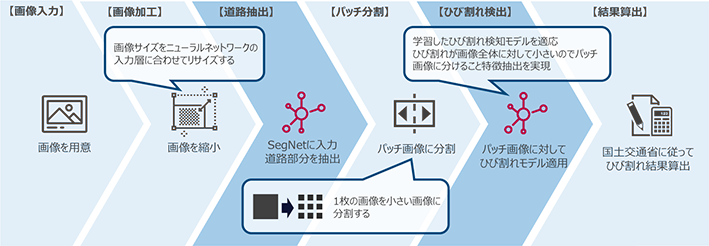
1つ目のプロセスは道路を抽出するプロセスです。入力として与える画像に依存しますが、画像中には道路の部分以外にも背景などのノイズが含まれる可能性が想定されます。そこで、画像中から道路部分を識別するために道路のセグメントを推論するSegNetと呼ばれるニューラルネットワークを活用しています。これにより、入力される画像に道路以外のものが写っていたとしても対応可能になります。

そして、2つ目のプロセスが本命であるひび割れ部分を識別するプロセスです。1枚の画像中に含まれるひび割れは非常に小さいものになってしまう傾向があります。通常のConvolutinal Neural Networkによる畳み込み処理を適用してしまうと、この小さいひび割れの特徴が畳み込みによって失われてしまうために検出できないという問題があります。
そこで、画像中に含まれるひび割れの特徴を大きくするために、パッチと呼ばれる小さい画像に分割し、そのパッチ画像に対してニューラルネットワークを適用することで特徴抽出を可能にしています。
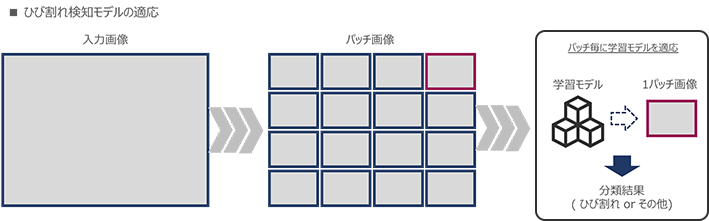
このような検知プロセスを経て、最終的に2つのプロセスから得られた道路とひび割れの割合の結果を元に、国土交通省の指標を算出しています。
6. 学習モデル
前項の検知プロセスでは、大きく2段階のニューラルネットワークを利用していることを説明しました。それぞれについて少し解説をしたいと思います。
SegNet
SegNet[2] *とは、2015年にケンブリッジ大学のAlex Kendallらが論文発表した、画素単位のセマンティック・セグメンテーションを実現する深層畳み込みニューラルネットワークアーキテクチャです。このニューラルネットワークのアーキテクチャは、encoderネットワークに相当するdecoderネットワークと、それに続くSoftmaxレイヤーからなる構造で定義されており、encoderネットワーク内でMaxPoolingする際に指定しているインデックスをdecoderネットワーク内でUpSamplingする際のインデックスとして利用することで、高速かつ省メモリでパフォーマンスを維持しつつ実用的なセグメンテーションを実現します。
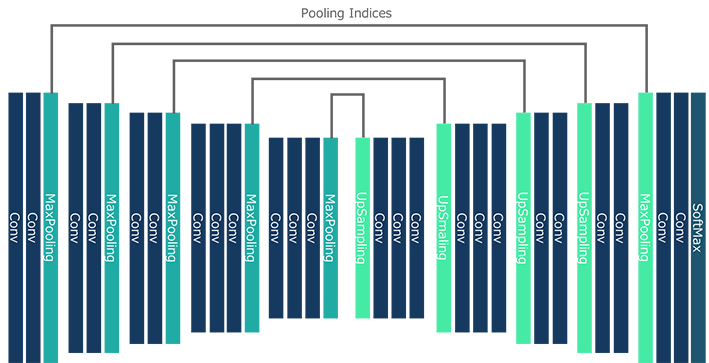
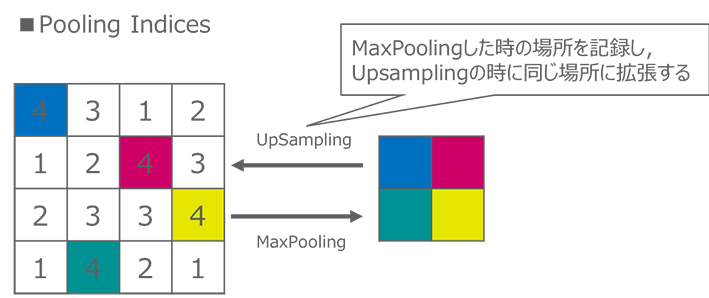
また、学習時に利用するデータセットの各クラスのピクセル数にばらつきがある場合、ピクセル数が大きいものに結果が牽引されてしまうため、実際のピクセル数に応じてソフトマックスレイヤーでのクロスエントロピー誤差を計算する際に重み付けをすることで正確なセグメンテーションを図っています。
ひび割れ検知モデル(CNN)
パッチ画像に対してひび割れかどうかを判別するためのモデルは、一般的なCNNを使って学習モデルを作成しました。作成したニューラルネットワークの構成は次の通りです。

今回はConv層を2層連続で定義することで、非線形のデータ対応と計算コストを削除することを可能にしています。また、道路の画像は基本的にグレーの一様の画像であるため、過学習を回避するためにDropout層を適切に設けています。
最後の層では、出力されたパラメーターをFlatten層で平滑化して全結合層にパラメーターを渡すことで、バッチサイズの影響を受けないようにしています。
7. 学習とGPU
これまでに説明してきたデータセットと学習モデルを用いて、学習を行っていきたいと思います。
SegNetはchainercv[3] *というライブラリで学習済みモデルを提供しており、今回はそちらを利用するため、ひび割れ検知モデルのみを学習させました。学習環境として利用したハードウェアおよびソフトウェアスペックは次のとおりです。
ハードウェアスペック
| カテゴリ | 名称 | 内容 |
|---|---|---|
| サーバ | SuperMicro | CPU:Xeon E5-2667 v4 メモリ:32GB(DDR4-2400) × 8枚 SSD:960GB |
| GPU | Tesla P100 PCIe | 12GB × 1枚 |
ソフトウェアスペック
| 名称 | カテゴリ | バージョン |
|---|---|---|
| Ubuntu | OS | 16.04 LTS 64bit |
| Cuda | MW | 8.0 |
| cuDNN | MW | 5.1 |
| tensorflow | FW | 1.4.1 |
| Keras | FW | 2.3.1 |
| chainer | FW | 3.3.0 |
※ OS(オペレーションシステム),MW(ミドルウェア),FW(フレームワーク)
今回の学習では、Pythonライブラリであるscikit-learnにあるtraintestsplit関数を利用して準備したデータを8対2の割合で分割して、8割を学習データ、2割をテストデータとして利用しました。
学習の際に設定したバッチサイズは20、エポック数は50、オプティマイザーはAdamとしています。学習結果は次に示すとおりになりました。
| エポック数 | 実行時間(s) | accuracy | validation accuracy |
|---|---|---|---|
| 50 | 2205 | 0.9112 | 0.8989 |
accuracyは学習データに対する分類精度を示す値、validation accuracyはテストデータに対する学習モデルの汎化性能を示す値になります。つまり、未知のデータに対しても9割弱の分類精度を出す学習モデルを生成できたということになります。
これでセグメンテーションを実現する学習モデルとひび割れを検出する学習モデルの準備が整いました。次項では2つの学習モデルを組み込んだ検知プロセス全体の精度について説明していきたいと思います。
8. 精度と評価
前項までに説明してきた検知プロセスの流れに従って、入力として与えた画像から国土交通省が提示する指標を算出した結果を評価していきます。
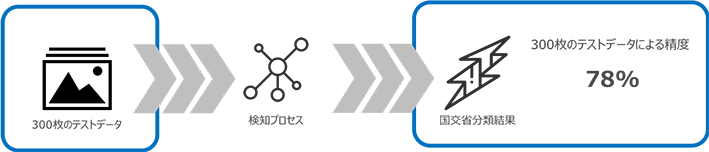
舗装点検要領に従ってアノテーションを実施した300枚の画像データを、入力として検知プロセスに与えた際の出力結果と正解ラベルとの分類結果がどれくらい一致するかを比較してみました。
結果はaccuracyが78%となりました。これより、検知プロセスを介した画像の出力結果は8割弱の信頼性があるということが言えます。
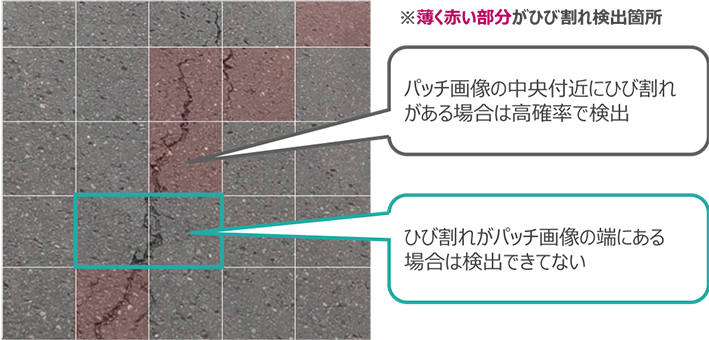
ひび割れモデル単体での精度が9割弱であるのに対して、検知プロセスの精度が8割弱であることに対する考察としては、検知プロセスで実施したパッチ画像への分割に原因があると考えられます。
パッチ画像に分割した際に、特定のパッチ画像によってはひび割れの位置が分割された画像の端にくるという場合があります。調べてみると、この場合の学習モデルの精度は著しく落ちるということが分かりました。このため、検知プロセスでは学習モデル単体の時より精度が落ちていたと考えられます。
これを解決する方法としては、ひび割れ検知モデルの学習モデルを生成する際に利用したデータセットに、複数のひび割れが画像の端に位置する画像を追加して再学習しなおすか、ゼロパディングの領域を多く設けて画像の端の畳み込まれる回数を多くし、画像端の特徴を考慮するように調整することが考えられます。
また、学習モデルではなく、パッチ画像に分割する際の分割方法を工夫する対応も考えられますので、状況に応じて解決策を選択することで精度をより向上させることができそうです。
まだまだ課題はありますが、検知プロセスによって画像から国土交通省が提示している指標をある程度の精度で算出することができました。今後の改良でより精度を高めていきたいと思います。
9. NTTPCでの実演
NTTPCの本社 ( 東京都港区西新橋2-14-1 興和西新橋ビルB棟 ) 6F受付の待合スペースには、お客さまが操作できるデモ端末がいくつか用意されており、その中に今回取り組んだ「道路ひび割れ検知」の内容を体験できるWebアプリケーションを展示しております。ご興味がある方はお越しの際に、ぜひご覧になってください。
10. まとめ
Deep Learning の活用事例として、画像中の“道路のひび割れ検知”を実世界の課題解決テーマとして、データ準備から学習モデルの定義、検知プロセスといったフェーズごとに解説しました。
今回紹介した事例というのは Deep Learning の活用方法の中のごく一部にしかすぎません。Deep Learning はさまざまな領域の多くの課題を解決する手段となり得る可能性を秘めています。特に、今回の事例でも紹介したように複数のニューラルネットの学習モデルを組み合わせることで現在抱えている課題を解決することにつながるかもしれません。
Deep Learning の秘めた可能性を引き出すことは「新しい価値を創造し、お客さまと社会におけるイノベーションを推進する」という事業ビジョンを掲げる、我々NTTPCの役目でもあります。
NTTPCでは、今後も継続的にDeep Learning の活用方法や課題解決に向けた取り組みを加速させて、さらなるイノベーションの実現に向けて取り組んでいきたいと思います。
参考URL
[1]: 舗装点検要領、http://www.mlit.go.jp/road/ir/ir-council/pdf/yobo28_10.pdf
[2]: SegNet、http://mi.eng.cam.ac.uk/projects/segnet/
[3]: chainercv、https://chainercv.readthedocs.io/en/stable/