



技術解説
SlurmとKubernetesの比較:分散学習編
2025.08.15

GPUエンジニア
大野 泰弘

1. 概要
- Slurm:スーパーコンピュータで磨かれたHPC (High Performance Computing)用ジョブスケジューラ。軽量な設計でGPUを90%以上使い切った事例が多数報告されています。
- Kubernetes:コンテナの総合オーケストレーター。Webサービス運用やオートスケーリングに強い一方、学習ジョブ単体では設定が複雑になり性能が落ちることがあります。
- 比較
- LLMを最短時間・最小コストで学習したいだけならSlurmが近道。
- クラウド環境でのオートスケーリングや推論環境も一元化したい場合はKubernetes + Kubeflowの利用を検討するのが基本方針です。
2. 位置づけと設計思想
| 観点 | Slurm | Kubernetes |
|---|---|---|
| 主目的 | HPC ジョブの 高速実行と資源効率 | あらゆるコンテナワークロードの運用統合 |
| 初出年 | 2003 年(HPC向けに進化) | 2014 年(Google社内ツールをOSS化) |
| 中核機能 | ジョブキューイング・ノード/GPU きめ細かい割当 | コンテナライフサイクル管理・サービスディスカバリ |
SlurmはTop500スーパーコンピュータで長年採用され、数万ノード規模でも軽量に動くコントロールプレーンが特長です。(Slurm vs Kubernetes: Which to choose for model training)
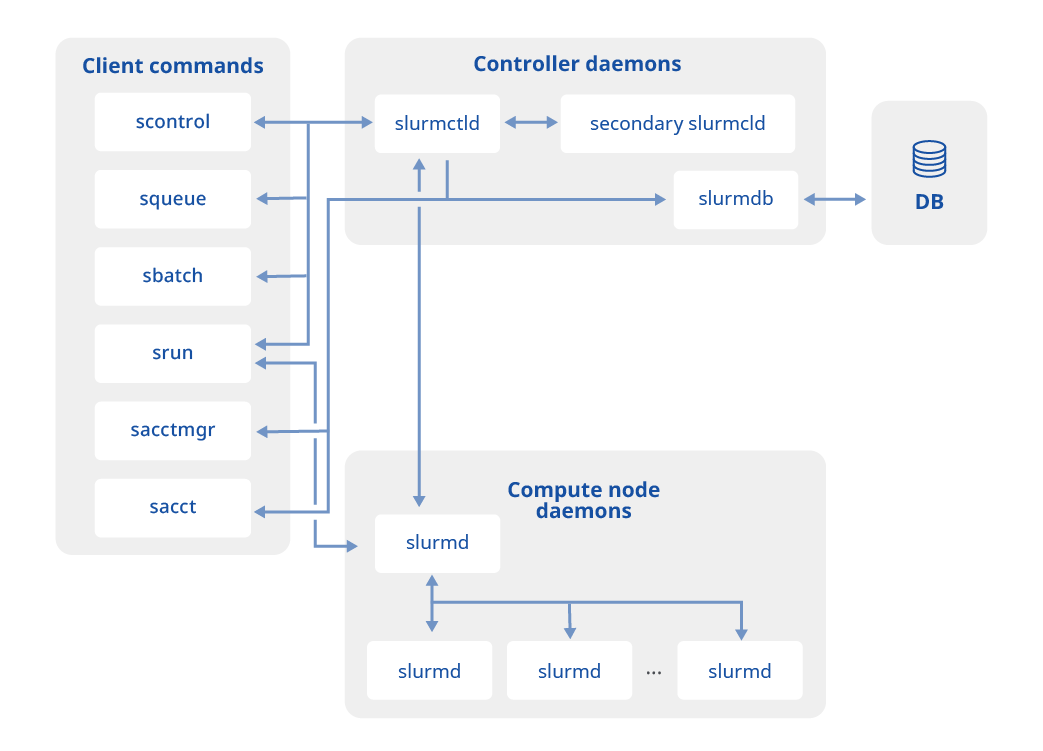
図1 Slurmの構成
一方Kubernetesは「ビルドしたコンテナをそのまま本番へ」というDevOps文脈で普及し、サービスディスカバリや自己修復を備えます。(Demystifying Kubernetes: how to get comfortable with complexity)
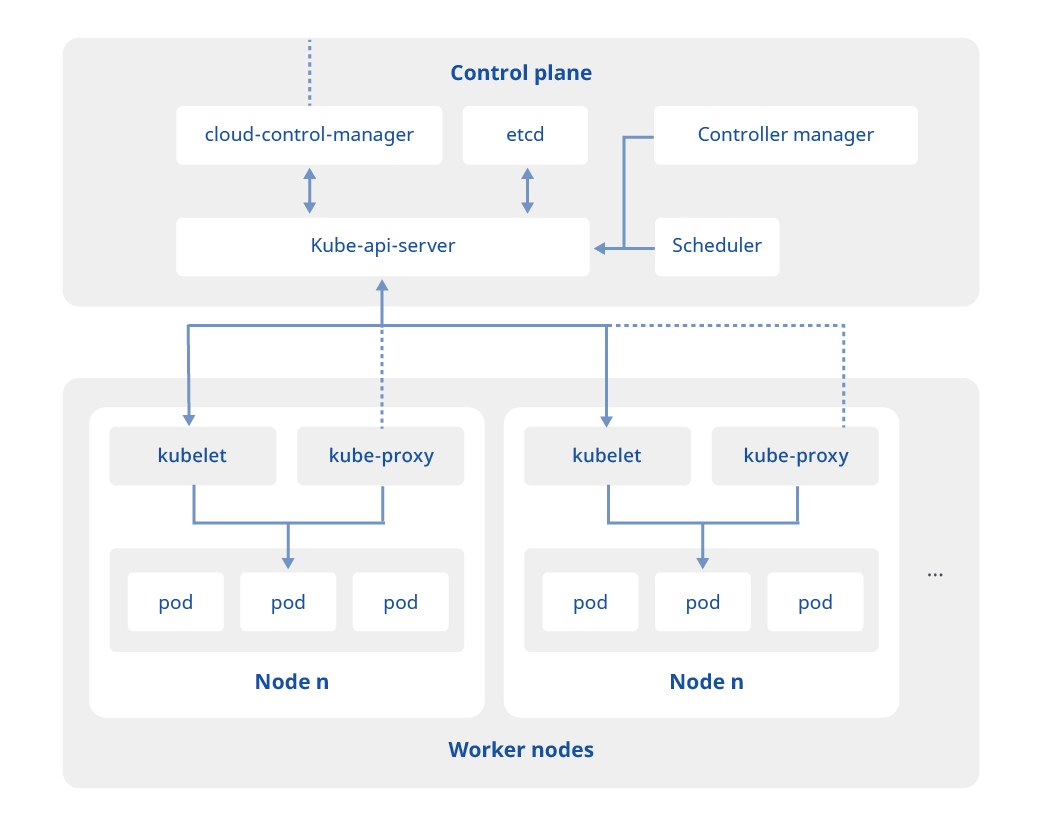
図2 Kubernetesの構成
3. スケジューラの性能・通信最適化
ジョブスケジューリングの効率
- Slurm:GPU 単位のパッキング、ノード間トポロジ認識、優先度アルゴリズム、予約機能がHPC向けに最適化されており、空きスロットをほぼゼロまで詰める実績があります。
- Kubernetes:デフォルトのスケジューラは CPU/メモリ中心で、GPUとの親和性を高めるには追加プラグインが必要。Kubeflow/KAI Scheduler 等でも Slurm 並みの密度を得るにはチューニングが不可欠です。 (https://github.com/NVIDIA/KAI-Scheduler)
ノード間通信
- Slurm × MPI/NCCL: srun で起動したプロセスに対してInfiniband&RDMAの最短パスを自動セットアップ。多数の研究機関で最小 1μs オーダーのレイテンシが報告されており、今日のデファクトスタンダードです。
- Kubernetes:MPI Operator や NCCL Fast-Socket DaemonSet を追加導入するが、20 % 近い性能低下を経験した事例も公開されています。 (Performance difference executing mpirun from launcher vs. inside pod)
4. 運用と開発コスト
構築
| コスト項目 | Slurm | Kubernetes |
|---|---|---|
| 必要台数 | 計算ノード + 管理ノード 1 台で開始可 | コントロールプレーン 3 台 + ワーカノード |
| 工数 | Slurmのインストール、単一の設定ファイル | CNI (ネットワーク)・CSI (ストレージ) など多層設定 |
保守
- Slurm:年1~2回の安定版アップグレード。設定ファイルは1か所。
- Kubernetes: マイナーリリースは年3回、EOLはメジャーアップデートから1年と早く、パッチ適用も月次。Operator/CRD、プラグインの互換性検証が欠かせない。やっと稼働したと思った頃には次のメジャーバージョンアップとなることも。(Kubernetes Release Cycle)
運用
| 項目 | Slurm | Kubernetes |
|---|---|---|
| ジョブ投入 | sbatch 数行のスクリプト | 複数 YAML/CRD (MPIJob, StatefulSet…) |
| デバッグ | squeue, sacct と単一ログ | kubectl で Pod 特定後、コンテナ内部のログを調査 |
| コントロールプレーン資源 | 数百 MB 程度 | etcd + API server で 数GB 消費例 |
- Kubernetesは 複雑な設定ファイル(YAML、CRD等)の管理は学習コストが非常に高く、 「開発者生産性のサイレントキラー」と指摘されることもあり、コミュニティでもJsonnet/CUEなど脱YAMLが議論されています。 (Rethinking Configuration - Beyond Declarative DSLs In Kubernetes)
- 一方、Slurm側は「設定ファイル一つ」「ログが一か所」に集約され、トラブル時のMTTR(平均復旧時間)が非常に短いことが評価されています。
5. エコシステムと拡張性
- Kubernetesの強み
- KubeflowやOpenShiftにより「学習 → 推論 → 運用」まで 1 プラットフォームで統合可能。 (How to use Kubeflow and the MPI Operator on OpenShift - Red Hat)
- クラウドのオートスケーラーと相性が良く、スポットノードを自動追加してコスト最適化できます。
- Slurmの強み
- NVIDIA Hopper GPU や NVIDIA Blackwell GPU のような最新ハードを早期サポート。NVIDIAがSlurm開発コミュニティを主導するSchedMD社に出資しており、意欲的な開発が行われています。
- コンテナにも対応。Singularity/Apptainerや、Pyxis + Enroot経由でネイティブ実行し、OSカーネル共有によるI/Oオーバーヘッドを最小化。
6. ROI
| コスト項目 | Slurm | Kubernetes |
|---|---|---|
| 初期セットアップ | Slurmdのインストール | マスター3台 + etcd + CNI + CSI |
| 維持運用 | シンプル(更新頻度低) | バージョンアップ毎に CRD 移行/CNI 互換検証 |
| GPU 利用率 | 実測 80~95 % 例多数 | 適切な Operator が無い場合 60~75 % に低下する報告 |
- Slurm は軽量なため 同じGPU台数でも総保有コスト(TCO)が低く、学習時間短縮で機会損失も抑制される傾向があります。
7. 推奨シナリオ
| シナリオ(利用シーン) | 適切なプラットフォーム | 理由 |
|---|---|---|
| オンプレまたは専用HPCクラスタでLLMトレーニング | Slurm | 通信最適化とGPU密集配置で学習時間を短縮 |
| クラウド主体でノードを頻繁に伸縮 | Kubernetes (+ Kubeflow) | ネイティブ Auto-scaling の恩恵大 |
| LLM学習後、同一基盤で推論サービスも運用 | Kubernetes | CI/CD, Service Mesh との統合が容易 |
| 社内にHPC文化が既にあり、運用人員が少数 | Slurm | 学習特化で管理負荷を最小化 |
8. まとめ
① 導入目的を明確に
- LLM分散学習を短時間かつ高いGPU利用率で遂行したいならSlurmが本命
- 学習後の推論運用やマイクロサービス統合も一気通貫に扱うならKubernetes
② TCO とリスク
- YAMLやOperator設計にかかる人的コストと性能ロスは、ハードウェアを追加投資するよりも高額になる可能性がある。
- Slurmなら既に枯れたHPCワークフローを流用でき、導入後すぐにモデル開発を開始可能。
③ ハイブリッドも視野
- 長時間学習はSlurmクラスタ、推論はKubernetesでスケールアウト、と役割分担する企業が今後スタンダード化の傾向。
現状のビジネス要件が「LLMをできる限り早く・安定して学習したい」のであれば、Slurm によるHPC流儀のジョブスケジューリングが最もコスト効果が高い選択肢です。Kubernetesを採用する際は、Kubeflow/MPI Operatorなど追加スタックにかかる学習コストと性能低下リスクを必ず事前試算し、GPU利用率が80%を下回らない設計検証を行ってから意思決定することを推奨します。