



トレンド
【イベント参加レポート】DDN主催『AI Data Summit Tokyo』 ~生成AIに求められる次世代インフラとデータ基盤~
2025.10.30

ネットワークエンジニア
有年 梨沙子

GPUエンジニア
井上 颯斗

2025年9月9日、紀尾井カンファレンスにて「AI Data Summit Tokyo」が開催されました。主催はデータストレージ分野のグローバルリーダー、株式会社データダイレクト・ネットワークス・ジャパン(以下DDN Japan)です。
当日はDDNやパートナー企業から、生成AIが「学習から推論へ」と移行する中で求められる次世代インフラとデータ基盤についてのセッションが行われました。イベントのアジェンダは以下の通りです。

イベントアジェンダ
セミナー後には来場者同士がコミュニケーションできるネットワーキングも開かれ、交流を通じて様々な知見を得ることができました。
本記事では、各セッションをダイジェストで振り返りながら、特に気になった点を深堀りしてお届けします。
【目次】
- 「AI Data Summit Tokyo」とは
- セミナー紹介
2-1 AI 今と未来 ― データ基盤の視点から(DDN Japan)
2-2 国産生成AI『Sarashina』の現在地とこれから(SB Intuitions株式会社)
2-3 進化するAIを支える次世代のデータプラットフォーム(DataDirect Networks, Inc)
2-4 生成AIおよび推論モデルを高効率に処理する基盤としてのNVIDIA Dynamo(NVIDIA)
2-5 生成AIシステム構築における技術選定と研究開発(NTTドコモビジネス株式会社)
2-6 生成AIインフラの進化:学習から推論へ、ストレージが担う役割とDDNの取り組み(DDN Japan) - まとめ
1. 「AI Data Summit Tokyo」とは

2. セミナー紹介
本イベントは、生成AIやLLMの実装が進むなかで、「学習から推論への最適化」を支える次世代データ基盤の姿をテーマに開催されました。
会場は紀尾井カンファレンス。100名を超える参加者が集まり、GPU・ストレージ・ネットワークを組み合わせた最新の技術トレンドや研究開発事例が、国内外の企業や研究者による講演形式で紹介されました。
2-1 AI 今と未来 ― データ基盤の視点から DDN Japan 代表取締役社長 Robert Triendl 氏
オープニングの基調講演を飾ったのはDDN Japan代表取締役社長のRobert Triendl氏です。流暢な日本語で講演されていたため、英語が苦手な私たちでも安心して聞くことができました。
本講演では、日本での20年の歩みを振り返りながら、日本市場がDDN全世界売上の15〜20%を占めるまでに成長していることが紹介されました。

講演スライドp.7より引用
中でも印象的だったのが、「今後3年間で日本への投資を倍増し、アプリ開発を直接支援する新プログラムを展開する。また、2026年にはクラウド実証プログラムも開始する」という発表です。日本市場に本気で取り組む姿勢が強く印象づけられました。
こうした後押しも受けて、これからさらに日本のAI市場は拡大・進化していくと思います。開発基盤への投資を拡大することで、日本のAI研究開発がさらに進み、結果的に私たちも高性能かつコストパフォーマンスにすぐれたAIモデルの恩恵を受けられる未来に期待したいと思いました。
もちろん、私たちNTTPCもパートナー企業と密に連携し、お客様により良い価値提供ができるように取り組んでいく所存です。
2-2 国産生成AI『Sarashina』の現在地とこれから SB Intuitions株式会社 取締役 兼 CIO 折原 大樹氏
次のユーザーセッションでは、ソフトバンクグループが手掛ける日本語に特化した国産生成AI「Sarashina」の開発状況が解説されました。
2024年度に4,000億パラメータの Sarashina2 を公開し、日本語理解・生成で高い性能を発揮。2025年度の商用化を目指しています。
さらに、マルチモーダル領域にも挑戦中で、画像理解対応の「Sarashina2-vision」 や3D再構成技術を開発。折原氏は、将来的には金融・法律・製薬・公共など、専門領域ごとに特化したAIエージェントへ発展させる構想を語りました。
また、「LLMは海外依存でよいのか」という問いかけとともに提示された国産最大級のAI計算基盤(NVIDIA DGX™ B200を活用、1兆パラメータ規模を目指す)への投資姿勢は、参加者に強い印象を残しました。
個人的にも、この“国産にこだわって開発する”というスタンスにはとても好感を持ちました。英語モデルでは対応が難しい日本語特有の表現や文脈に最初から高い精度で対応でき、国内の企業・自治体も安心してデータを活用できます。また、導入・運用コストの削減も期待できると考えています。
2-3 進化するAIを支える次世代のデータプラットフォーム DataDirect Networks, Inc CTO Sven Oehme 氏
続いてDataDirect Networks, IncのCTO、Sven Oehme氏が登壇し、DDNの新製品開発ポートフォリオを紹介しました。
同氏が主に紹介したのは次世代ストレージ「DDN Infinia」(以下Infinia)です。
DDN Infinia
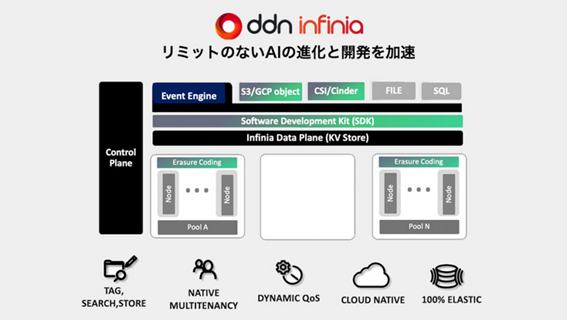
Infiniaは、生成AIや大規模言語モデルの学習・推論やRAGなどのワークフロー向けに設計された次世代データインテリジェンス基盤です。
主な特長として
- ノード追加による性能・容量の拡張性の高さ
- GPU直結RDMAゼロコピーI/Oによる低レイテンシと高スループット
- オブジェクトサイズ・メタデータの制限なし、無制限のタグ付けによるリアルタイム検索
等が挙げられます。
大規模AIモデルを学習する際には、学習が途中で止まっても再開できるよう、定期的にチェックポイントをストレージに書き込む処理が行われます。これまでのAI開発におけるストレージは、そのタイミングでのみ活用されるいわば”バックアップ”のような用途に留まっていました。
しかし、Infiniaはストレージを単なるデータ保存装置から、AI処理パイプラインの一部として推論環境でも活躍するデータインテリジェンス基盤に進化させています。
Infiniaが推論に優れている理由は、その拡張性と効率性にあります。
生成AIには、途中の計算結果をGPUに保存して再利用することで反応速度を速める「KVキャッシュ」という考え方があります。このKVキャッシュが大きければ大きいほど推論速度は上がるため、より早くより大きなデータが処理できます。ですがいくらKVキャッシュが大きくても、キャッシュ保存先とGPUの間の通信速度が遅いと読み書きに無駄な時間を食うこととなり、結果的にAI実行速度が落ちてしまいます。
オープンソースソフトウェアの「LMCache」などを利用し、メモリの保存先をスループットが高い順に階層化して管理している方も多いのではないでしょうか。メモリ保存先として外部ストレージを指定する場合、ストレージへの通信速度がボトルネックになり全体性能が落ちるという課題がありました。
しかし、InfiniaはGPU直結RDMAゼロコピーI/Oによって、通信の低レイテンシと高いスループットを実現させることでこの課題を解決し、より大きなデータを扱えるようになりました。加えてスケールアウト構成により、ラックスケールで最大100PB級まで拡張可能とのこと! AI推論用の大規模データセットを単一基盤上で扱うことも夢ではありません。すべての領域を推論に利用できるとなれば、AI性能はぐんと上がることが期待できます。
講演でも、ストレージは単なるデータの置き場ではなく、アプリやAI処理と直結し、ワークフローを自動化・加速する“アクティブなデータ基盤”へと進化していることが強調されました。
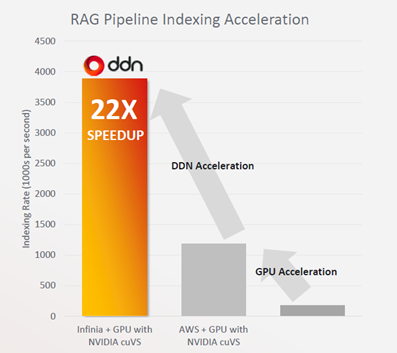
講演スライドp.10より引用
特に注目を集めたのは、AWS S3と比べた検証において、NVIDIA NIMおよびcuVSを組み合わせたRAGパイプライン処理で最大22倍の速度向上を実現したこと、にもかかわらずコストは約半分に抑えられているという検証事例です。
今回初めてInfiniaという製品を知りましたが、データ基盤の役割が「AIを加速する主役」に変わり、AIのスピードを左右する要になる存在だと強く感じました。
なお本イベント当日、DDNよりInfiniaの国内販売開始が正式発表されました(販売開始:2025年9月9日、出荷開始:11月予定)。アプライアンス形式での提供で、パートナー経由での販売となるとのことです。導入をご検討の方はぜひ当社までお問い合わせください。
参考:プレスリリース
DDN Infinia SDK
前述したDDN Infiniaに加えて、エンジニアのためのSDK「DDN Infinia SDK」も提供されることが発表されました。
Infinia SDKとは、開発者がInfiniaを直接制御・活用できるようにするためのソフトウェア開発キットです。
Infinia SDKの特長としては
- S3やPOSIX、NFS層を介さず、アプリケーションからネイティブにGPU/CPUメモリへアクセス可能。
- C++、Python、Go、Rust、Javaなどの主要言語に対応
- 主要なAIフレームワークへの組み込みも容易
等が挙げられます。
従来のようにS3 APIやNFSマウントを介してデータを読み書きする場合、プロトコル変換やカーネルI/Oなどの処理に時間がかかり、GPUの計算処理に対してデータ供給が追いつかずに処理待ち状態が生じることがありました。
しかしInfinia SDKでは、これらの中間層を排除することで、GPUメモリとストレージ間を直接結び、ゼロコピーアクセスをするアーキテクチャとなっています。これにより、AIトレーニングや大規模データ解析、生成AIモデルの推論処理において、データ転送のオーバーヘッドを最小化し、大幅なスループット向上とレイテンシ削減を実現しています。
2025年12月末日(延長する場合があります)まで、DDNではAIアプリケーション開発支援プログラムを提供されているとのこと。なんとInfiniaとSDKが無償提供(!)という大盤振る舞いで、今後私たちもぜひ触ってみたいと思います。
本セッション後の休憩時間には、参加者に温かいコーヒーと美味しい焼き菓子が振舞われました。嬉しいおもてなしに感謝です!長丁場のセッションも集中して聴き続けることができました。
2-4 生成AIおよび推論モデルを高効率に処理する基盤としてのNVIDIA Dynamo NVIDIA ソリューションアーキテクト 山崎和博 氏
続くパートナーセッションでは、NVIDIAから最新の推論基盤 「NVIDIA Dynamo」 が紹介されました。
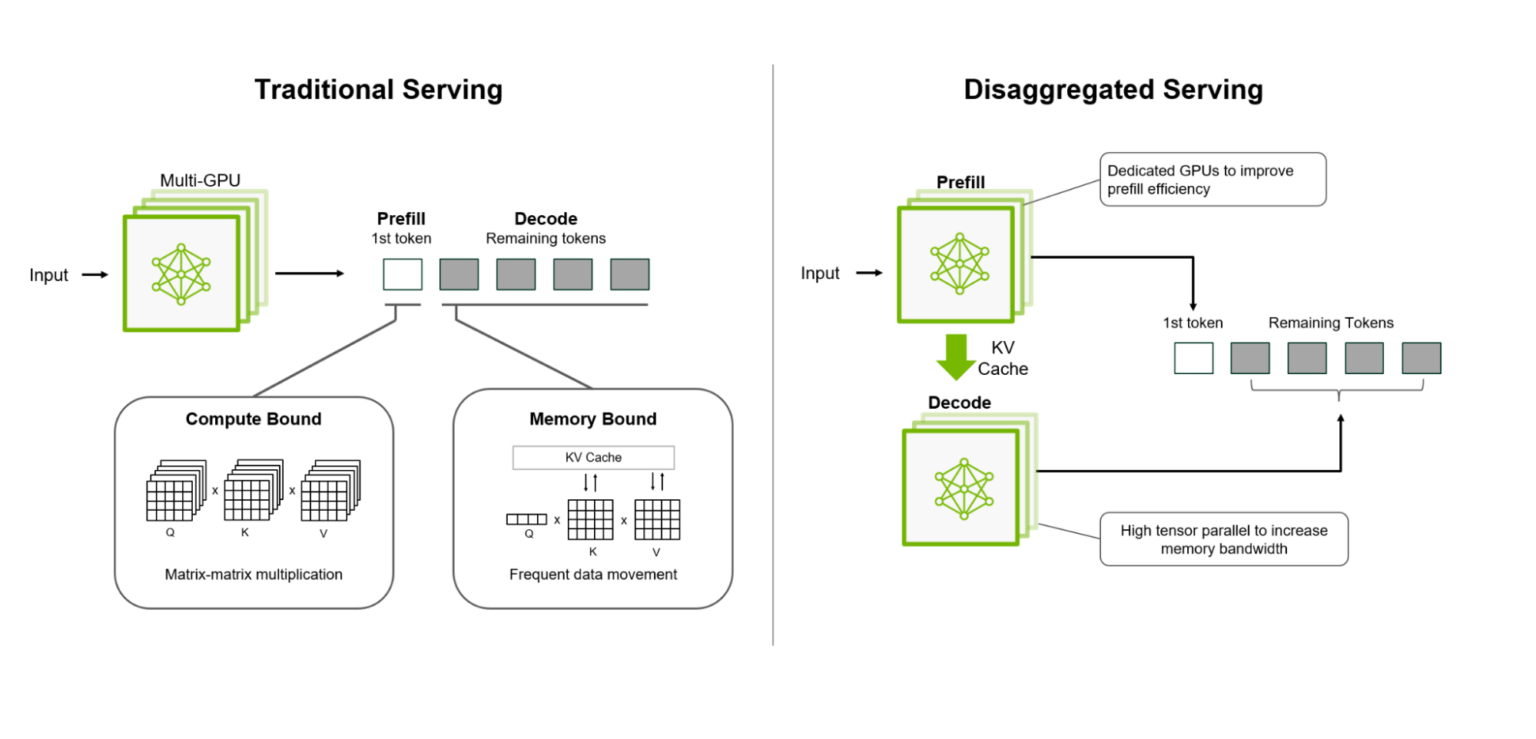
引用:NVIDIA Technical Blog
Figure 1. Disaggregated serving separates prefill and
decode on different GPUs to optimize performance
AI開発において、GPUとストレージは切っても切り離せない関係にあります。DynamoはNVIDIA GPUを利用したAI推論速度を加速するための最適化技術です。以下のような4つの機能を持っています。
① スマートルーター
それぞれのGPUに搭載されているKVキャッシュの中身を参照し、その中で最もヒット率の高いGPUにルーティングしてくれる便利な機能です。
身近な例でいうと、会社の中で「技術的な相談がしたい」と考えた際に、「人事部のAさん、経理部門のBさん、エンジニアのCさんのうち、適任者はエンジニアのCさんだ」と判断するように、ユーザーのリクエストに一番早く回答できるGPUをソフトウェアが選んでくれるイメージです。
② GPUプランナー
与えられているGPUリソースを、リクエストに応じてGPUリソースを動的に割り当てる機能です。
生成AIでは、ユーザーの入力をトークン化して機械が処理できる形にするプレフィル処理と、プレフィル処理で生成されたトークンから次のトークンを予測して出力するデコード処理という二つの処理が行われています。基本的にプレフィル処理の方が計算量は多く、多くのGPU稼働が必要になります。さらに、プレフィル処理はデコード処理に先行して行われるため、処理が遅いと全体の処理性能を落とす原因になってしまいます。
GPUプランナー機能では、そうした事態を防ぐためにそれぞれの処理のGPU稼働率を観察し、時にはデコード処理をしているGPUをプレフィル処理に割り当て直したりする、いわば”現場監督”のような役割を果たしてくれます。
③ KVキャッシュマネージャー
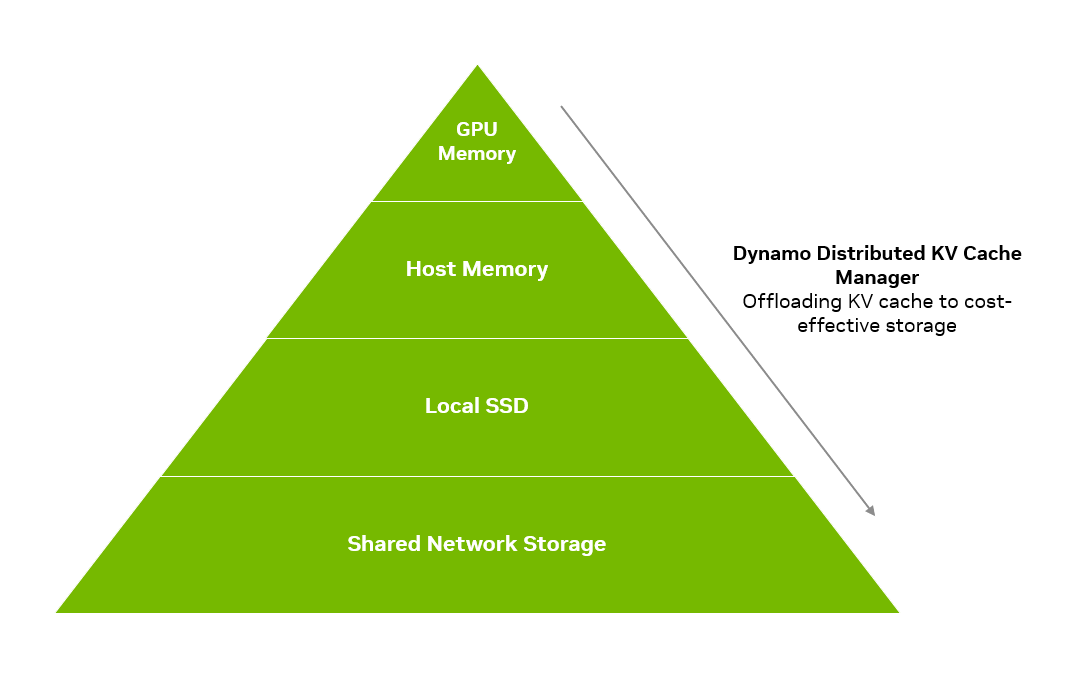
引用元::NVIDIA Technical Blog
Figure 6. NVIDIA Dynamo Distributed KV Cache Manager
offloads less frequently accessed KV cache
to more economical memory hierarchies
KVキャッシュ内の中間状態データを、上の図のようにGPUメモリからのスループットの高い順にストレージにオフロードしてくれる機能です。これによってより多くのKVキャッシュの保持が可能になり、応答速度が向上します。
④ NVIDIA Interface Transfer Library(略称:NIXL)
推論で利用されるデータ転送に最適化された低遅延通信ライブラリです。
異なるデータパス間でも一貫したAPIを使用することで異なるメモリ、SSD、ネットワークストレージとの互換性をサポートしてくれるため、データの変換処理や形式違いによる処理待ちリスクが低下します。
このように、NVIDIA Dynamoは単なるGPU制御ソフトではなく、AI推論のパフォーマンスをシステム全体で最適化するための統合基盤です。推論コストを抑えつつスループットを大幅に拡大することができ、大規模なリーズニングモデルも効率よく動かせる点が強調されました
スマートルーターによる負荷分散やGPUプランナーによるリソース再割り当ての説明は、NVIDIA Dynamoならではの特色であり、多くのエンジニアが熱心にメモを取るなど実務適用への関心の高さが感じられました。
推論処理のあらゆるボトルネックにアプローチするこのような設計思想は、今後のAIインフラ設計における新たな指針となっていくと期待しています。
2-5 生成AIシステム構築における技術選定と研究開発 NTTドコモビジネス株式会社 露崎浩太 氏・紀本雅大 氏
通信キャリアならではの研究開発の取り組みと、社内複数部門が利用する大規模データ基盤の検証について紹介されました。
同社では、NTTグループが開発した国産LLM「tsuzumi🄬」において、TensorRT-LLMやNVIDIA NIM™を活用した推論高速化検証を実施しています。さらにIOWN APN を活用し、三鷹・秋葉原・川崎の各所に点在するデータセンターを高速ネットワークでつなぎ、拠点間分散学習の実証を進めています。
加えて、同社が導入したInfiniaのS3互換ストレージでの検証結果も共有されました。
中でも特に強調されていたのが「AIシステムは複雑である」という前提で
① どのレイヤの技術が必要なのかを捉える
② API経由で使えるSaaSは複雑性を排除できるため、低コストで済むなら積極的に使う
③どんな技術に基づいたプロダクトなのか、検証を通じて技術を理解する
ということです。
生成AI技術は複数の要素が複雑に組み合わさっているため、自社で手を入れる範囲と外部を活用する範囲を見極めることが肝心なのだと感じました。
実際のインフラ構築と研究を並行しながら「どのレイヤでどの技術を採用すべきか」を見極める姿勢がとても印象に残りました。
2-6 生成AIインフラの進化:学習から推論へ、ストレージが担う役割とDDNの取り組み DDN Japan 井原修一 氏
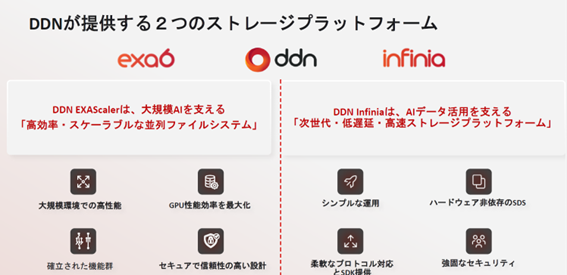
講演スライドp.2より引用
最後に登壇した井原氏は、あらためて生成AI基盤を支えるストレージの重要性を解説しました。
特に、DDNストレージがAI基盤に採用されるポイントとして
- EXAScaler による高速チェックポイント処理(数百秒→数十秒)
- KVキャッシュのオフロードによる推論効率改善とユーザー収容数拡大
- Blackwell世代DGXクラスタを支えるストレージ性能の重要性
などが挙げられました。
「GPUの性能を引き出すには、データ入出力のボトルネックを解消することこそが鍵」というメッセージが強く印象に残りました。
3. まとめ ― データ基盤がAI進化のカギに
昨今のAIの急速な進化を支える一翼として、データ基盤は重要な役割を担っています。
今回のイベントで発表された内容のサマリは以下の通りです。
- DDNの Infinia が示した“アクティブに動く”ストレージ
- ソフトバンクグループのLLM 「Sarashina」 の挑戦
- NVIDIA Dynamoによる大規模推論の効率化
- NTTグループでの 通信×AI を活かした分散学習へのチャレンジ
- DDN EXAScalerによるGPU効率の向上
なお、本イベントはアーカイブ配信を行っています。ぜひ以下リンクより登録のうえご視聴ください。
セッション収録動画:https://ddn.co.jp/ai-data-summit-tokyo/
各セッションはいずれも満席で、AIインフラへの関心と期待の高さが強く感じられました。
私たちが現在検証中の新しい技術や、各社のこれからのAI事業に対するアプローチの話など、当社としても興味が尽きない話ばかりでした。
主催社発表だけでなく、「AI推論をいかに効率的にするか」という共通課題に対して、それぞれ異なる角度から挑戦するパートナー企業が複数登壇されていたのが印象的でした。
加えて、自身がまだまだ知らない技術の話も多く出てきたことで、生成AIの発展スピードは非常に速く、今後もこうした技術動向を追うことは欠かせないと改めて実感しました。
本イベントへの参加を通して、私たちの業務やシステムにどう応用できるか実践的な視点で考えることができ、非常に勉強になりました。今後のデータ基盤の進化に期待しています。
今回得た知見を今後の業務や提案活動にも活かし、AI時代の変化を支える一員として成長していきたいと思います!
※本記事は2025年9月時点の情報に基づいています。製品に関わる情報等は予告なく変更される場合がありますので、あらかじめご了承ください。各プロダクトの仕様・機能については、メーカーが公表している最新の情報が優先されます。
※「NVIDIA」は米国およびその他の国における NVIDIA Corporation の商標または登録商標です。
※「DDN」「EXAScaler」は米国DataDirect Networksが所有する商標または登録商標です。
※「Sarashina」は、SB Intuitions株式会社の商標または登録商標です。