



性能検証
NVIDIA DGX™ A100徹底検証! Vol.2
2020.10.05

NTTPC GPUエンジニア

Vol.1記事では、
① ベンチマークソフト実行結果
② DGX A100をフルパワーで回した場合の消費電力
をまとめました。今回はA100の新機能である「MIG(Multi Instance GPU)」を検証していきます。
今回検証した項目は次の4点です。
③ MIG を利用したGPU分割の手順
④ MIGをDockerコンテナ上で利用してみる
⑤ MIGをSingularityコンテナ上で利用してみる
⑥ DGX A100のCUDAバージョン互換性確認
3. MIGを利用したGPU分割の手順
GPUを分割する手法として、MIGのほかに「NVIDIA 仮想 GPU (vGPU)」 があります。よくvGPU と MIGは混同されるのですが、MIGはGPU自体がもつ機能です。vGPUのように追加ライセンスの購入は必要ありません。2023年2月時点では、「NVIDIA A100 GPU」「NVIDIA A30 GPU」「NVIDIA H100GPU」の3種類のみで利用可能です。
さっそくMIG機能を使っていきましょう!
まず、デフォルトではMIGは無効化されているため、MIG機能を有効化する必要があります。
DGX A100には8基のGPUが搭載されていますが、すべてのGPUに対してMIGを有効にすることもできますし、特定のGPUのみMIGを有効化し、残りはそのまま使うということも可能です。
ただし、何らかのプロセスが GPU を利用しているとていると、MIG の有効・無効の切り替えができません。まずはモニタリングプロセスを停止しましょう。
1. いったんモニタリングを停止
$ sudo systemctl stop nvsm $ sudo systemctl stop dcgm
2. すべてのGPUのMIGを有効化する
$ sudo nvidia-smi -mig 1
3. 特定のGPUのみ有効化する
$ sudo nvidia-smi -i GPU-ID -mig 1
4. いったん停止していたモニタリングを再開
$ sudo systemctl start nvsm $ sudo systemctl start dcgm
また、MIGには大きく分けて下記2つの要素があります。
① GPU Instance
② GPU Compute Instance
まずは① GPU Instanceで大きな「パーティション」を作成し、次に②GPU Compute Instanceで具体的な割り当てスペックを決めていきます。
①のGPU Instanceでは、Streaming Multiprocessor、GPUメモリを分割します。これがいわゆる「パーティション」と呼ばれる概念です。GPUメモリはGPU Instance内で共有されます。
GPU Instanceの確認方法・作成方法は下記の通りです。
さきほどMIGを有効化したため、「nvidia-smi mig」コマンドが使えるようになっています。
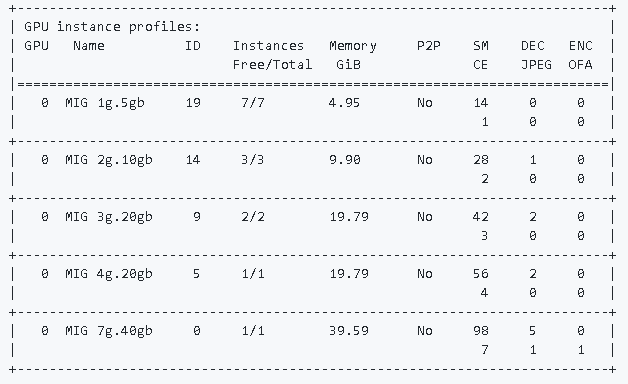
GPU Instance Profile listの確認
$ sudo nvidia-smi mig -lgip
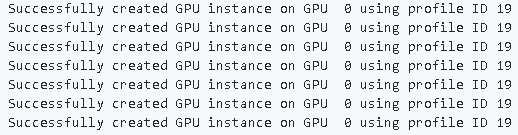
GPU Instanceの作成
$ sudo nvidia-smi mig -i 0 -cgi 19,19,19,19,19,19,19
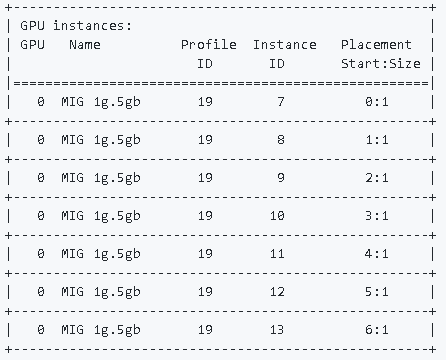
作成されたインスタンスの確認
$ sudo nvidia-smi mig -lgi
GPU Instanceの削除
nvidia-smi mig -i 0 -gi 0 -dgi
②のGPU Compute Instanceでは、Streaming MultiprocessorやGPU Enginesを分割します。これにより、①GPU Instanceで分割したパーティションの詳しいスペックを決めることができます。
ここで、MIGで設定できるインスタンスサイズの種類を説明します。下記のようなバリエーションがあります。
1g.5gb:1個のGPC / 5GB のメモリをもつ最小のインスタンス。A100なら最大 7 個作成可能。
2g.10gb:2個のGPC / 10GBメモリをもつインスタンス。
3g.20gb:3個のGPC / 20GBメモリ
・
・
・
7g.40gb:7個のGPC / 40GBメモリ。A100 (40GBメモリ版) をまるまる1つ占有するインスタンス。
どのインスタンスサイズにするか決まったら、GPU Compute Instanceを作っていきましょう。
例1)1q.5gb の場合
$ sudo nvidia-smi mig -lcip -i 0 -gi 7
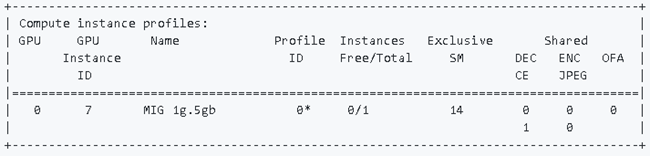
例2)3q.20gb の場合
$ sudo nvidia-smi mig -lcip -i 1 -gi 1
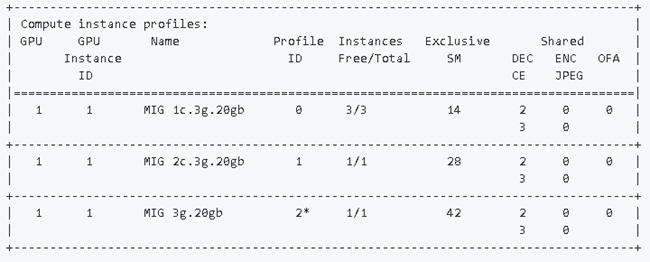
GPU Compute Instanceの作成
$ sudo nvidia-smi mig -cci 0 -gi 7 $ sudo nvidia-smi mig -cci 0,0,0 -gi 1
MIGの設定を行ったら、nvidia-smiコマンドで設定内容を確認しましょう。下記は実行画面です。
GPU列(赤枠)には、どの物理GPUカードを利用しているのかが表示されます。物理GPUにはGPU0~6まで連番がふられています。今回はGPU0とGPU1を使っていますね。

このように、MIGを使ってGPUの分割を行うことができました。ひとまずはMIGが使用できることを確認でき、一安心です。次回はMIGの動作検証を行っていきます。
4. MIGをDocker上で利用してみる
MIGで分割したGPUリソースを、Docker上で利用したいケースもよくあると思います。手順をおさえておきましょう。
Dockerの利用コマンド
sudo docker run --gpus '"device=0:0"' --rm -v $(pwd):/works nvcr.io/nvidia/pytorch:20.08-py3 python3 /works/examples/mnist/main.py
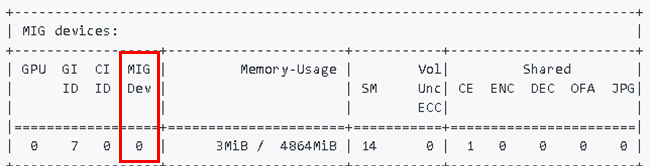
Docker19.03以降で実装された「-gpusオプション」でGPUを指定することで、Docker上でMIGを利用することができます。通常の(MIGでない)GPUを指定するときと同様に、deviceにnvidia-smiコマンドで表示されるgpuとmigidを渡します。MIGDev(赤枠)の列に表示されているのがmigidです。
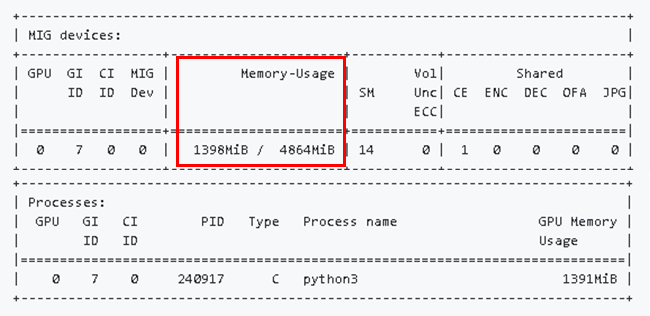
Dockerコンテナ上でmnistを実行したあとにnvidia-smiコマンドを再実行すると(図2)Memory-Usage列(赤枠)から、指定したGPUのメモリ使用量が上昇していることがわかります。
5. MIGをSingularity上で利用してみる
Singularityでも、MIGで分割したGPUの利用が可能かを試してみます。
Singularityの利用コマンド
SINGULARITYENV_CUDA_VISIBLE_DEVICES=MIG-GPU-4619c582-f7eb-6297-33f0-81d3c98c4981/8/0 singularity exec --nv --bind $(pwd):/works ngc_pytorch.sif python3 /works/examples/mnist/main.py
Singularityでは、Dockerと異なり環境変数でMIGを指定します。使用する環境変数は、上記コマンドでも使用されている”SINGULARITYENV_CUDA_VISIBLE_DEVICES”です。
この環境変数に
- MIG-GPU-UUID
- GPU instance ID
- compute instance ID
を指定してSingularityを実行することで、分割されたGPUを利用することができます。
それでは、各IDの確認方法を見ていきましょう。
まず、MIG-GPU-UUIDはおなじみnvidia-smiコマンドのLオプションで確認できます。
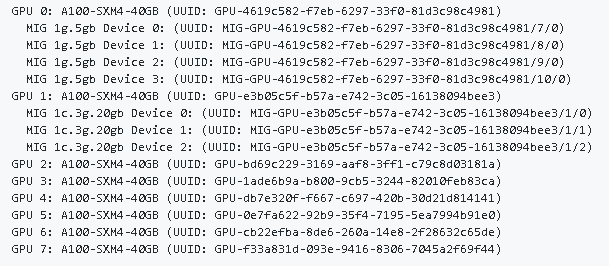
また、GPU instance IDとcompute instance IDは、同じくnvidia-smiコマンドでのGIID列(赤枠)、CIID列(青枠)がそれぞれ対応します。
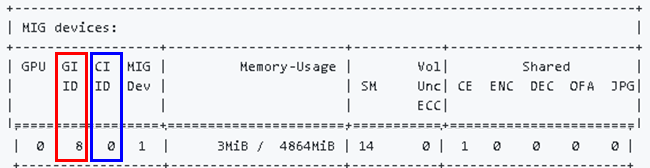
Dockerでテストした際と同じく、mnistを実行後にnvidia-smiコマンドを実行してみると、指定したGPUのメモリ使用量が上昇していることがわかります(赤枠)。Singularity実行時に指定したGPUをつかんでいることが確認できました。
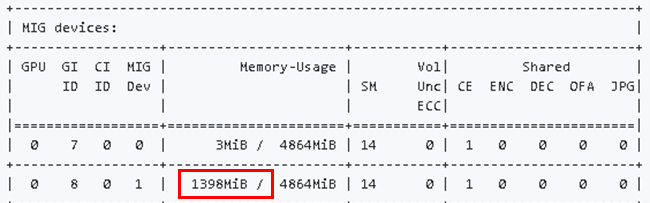
以上より、MIGで分割したGPUをコンテナ上で活用することができました。このあとは通常のDocker、Singularityイメージと同じように扱うことができます。
6. DGX A100のCUDAバージョン互換性確認
DGX A100の推奨CUDAバージョンはCUDA11系です。ただし、まだまだCUDA10系でのみで動くライブラリも多く存在しているため、下位バージョンとの互換性を確認したいと思います。
今回はCUDA10.1のコンテナイメージを使い、TensorFlowからGPUが取得できるかを検証しました。
Cuda10.1のコンテナからpythonを実行
docker run --gpus '"device=3"' -it --rm tensorflow/tensorflow:2.2.0-gpu python
pythonからGPUデバイス取得のコードを実行
>>> from tensorflow.python.client import device_lib >>> device_lib.list_local_devices()
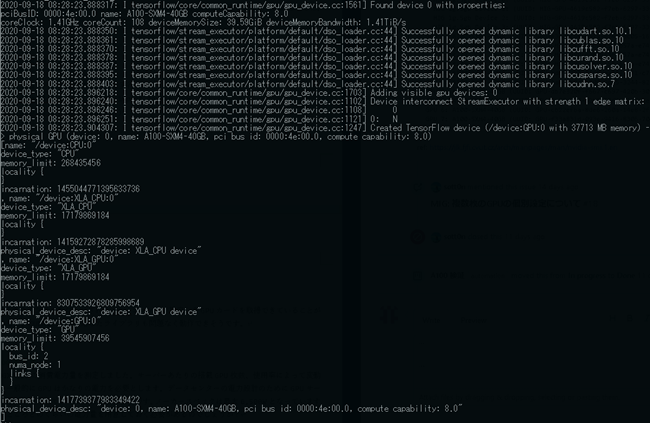
CUDA10系のライブラリがロードされ、—gpusコマンドで指定したGPUカードを取得できていることが確認できました。CUDA10.1に対応したライブラリもおおむね動作できそうです。
今回検証した結果は以上です。DGX A100の能力が伝わりましたでしょうか?本マシンの導入をお考えの方はぜひNTTPCまでお問い合せください!