



技術解説
生成AI/LLMの開発を加速するGPUクラスタ
Vol.1【前編】マルチノードGPUシステムとインターコネクト
2024.01.25

GPUエンジニア
大野 泰弘

サーバーエンジニア
力石 誠也

ネットワークエンジニア
古賀 祥治郎

大規模言語モデルの開発機運が高まる
2022年11月30日にOpenAI社が「ChatGPT」(図1)を公開したことをきっかけに、AIを取り巻く状況は大きく変わりました。それまでのAIとは一線を画すChatGPTの能力はさまざまなメディアで取り上げられ、「生成AI」という専門用語も一般的に使われるようになり、企業や行政機関でChatGPTを活用する動きも広がるなど、社会に大きな影響を与えています。
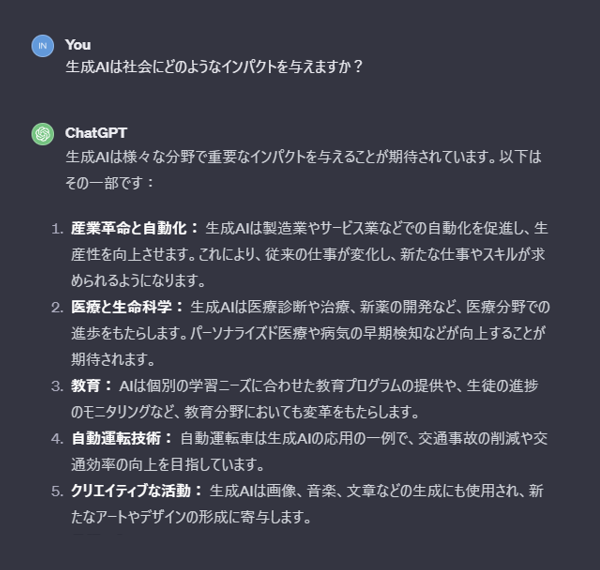
図1. 社会に衝撃を与えたOpenAI社の「ChatGPT」。
GPT-3.5という大規模言語モデルで構成されているほか、
さらに大規模のGPT-4を使った有料サービス「ChatPro」も提供されている。
ChatGPTを実現しているのがニューラルネットワークの一種である「transformer」で開発された「大規模言語モデル」(LLM:Large Language Model)です。学習に大量のテキストを使うことに加えて、パラメータ数(重みの次元数)をきわめて大きく設定しているのが従来の言語モデルとの違いです。ちなみに、ChatGPTに使われている大規模言語モデル「GPT-3.5」のパラメータ数は3550億と公表されています。
生成AIがもたらすさまざまな可能性を見据えて、AIベンチャーを中心に、自分たちで大規模言語モデルを開発しようという機運が高まってきました。他のサービスや大規模言語モデルを使わずに、敢えて独自のモデルを開発するのには次のような理由があると考えられます。
- 大規模言語モデルや関連技術を研究したい
- 英語を主な学習データとして開発された海外製の大規模言語モデルに対して、日本語を得意とする大規模言語モデルを開発したい
- 社内や組織内に蓄積されたデータを学習に活用したい(コールセンターにおけるカスタマーとのやりとりや、大病院における電子カルテなど)
- 他の事前学習済みモデルをベースにしながら、追加学習データを与える「継続事前学習」や「ファイン・チューニング」を行いたい
- テキストだけではなく画像や音声/音楽データなどを組み合わせたマルチモーダルな生成AIシステムを構築したい
大規模言語モデルの開発に適したマルチノードGPUシステム
大規模言語モデルを開発するには三つの要素が必要です。まずひとつめが学習データです。日本語に関しては、ライセンスが明らかなWikipediaや青空文庫のほか、大学や研究機関などが公開しているデータセットが一般に用いられます。また、社内や組織に蓄積されたデータも追加のデータセットとして使うことができるでしょう(個人情報などデータ利用に制約がある場合を除く)。ちなみに、OpenAIが2020年に開発した「GPT-3」の学習には570GBのデータが使われたと言われています。
もうひとつ大規模言語モデルの開発に必須となるのがパラメータ数です。入力データを分解したトークンをベクトル化した重みがパラメータであり、transformerにおいては語彙数や隠れ層数などによって決まります。
最後に必要になるのが計算リソースです。学習用データセットのサイズとパラメータ数の双方がきわめて大きいことが大規模言語モデルの条件になりますから、多くの計算リソースが必要になるであろうことは容易に想像がつきます。
OpenAI社が2020年に公表した論文「Scaling Laws for Neural Language Models」で、学習用データセットのトークン数、モデルのパラメータ数、および計算量のそれぞれが大きければ大きいほど、ある語句の次に登場するであろう語句を予測する能力が向上することが同社の経験則として示されています(図2)。
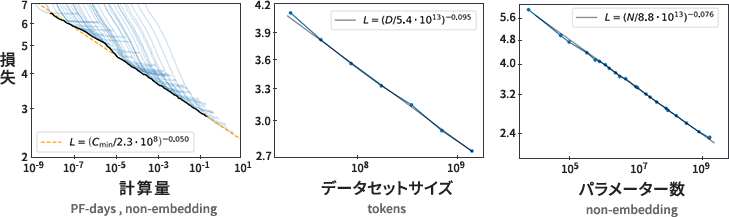
図2. OpenAI社が発表したスケーリング則。
トークン数、モデルのパラメータ数、および計算量のそれぞれを大きければ大きくするほど
テストロス(誤差)が小さくなることが同社の経験則として示された。
("Scaling Laws for Neural Language Models", J.Kaplan, et.al, 2020/1/23から引用)
すなわち、transformerの大半を占める行列積計算(テンソル計算)性能の高いGPUをできるだけ多く用意することが、大規模言語モデルの開発には必須と言えます。
ここで重要になるのがVRAM容量です。GPUでできるだけ高い性能を得るにはすべてのパラメータがVRAM上に置かれていることが望ましいのですが、各パラメータがFP32(4バイト)で記述されているとすると、単純にはパラメータ数の4倍のVRAM容量が必要になります。たとえば、GPT-3に相当する1750億パラメータをFP32で記述すると1750億×4B≒700GBが必要で、実際にGPT-3のサイズは900GBと言われています。
ただし、一台のサーバーに搭載できるGPUの個数には限りがあり、NVIDIA DGX™ H100の場合で、搭載されているNVIDIA H100 Tensor コア GPUは8基です(図3)。NVIDIA H100 GPUのVRAM容量は1基あたり80GBですので、8基を搭載したNVIDIA DGX™ H100でもトータルで640GBにしかなりません[*1]。単純計算では1200億から1300億パラメータ程度が限界になるでしょう。

図3. NVIDIA H100 Tensor コア GPUを8基搭載したNVIDIA DGX™ H100。
VRAMのトータル容量は80GB×8=640GBである。
ではどうすればいいかというと、ご賢察のとおり、複数台のGPUサーバーを並べた「マルチノードGPUシステム」(図4)を構成する以外に解決策はありません。
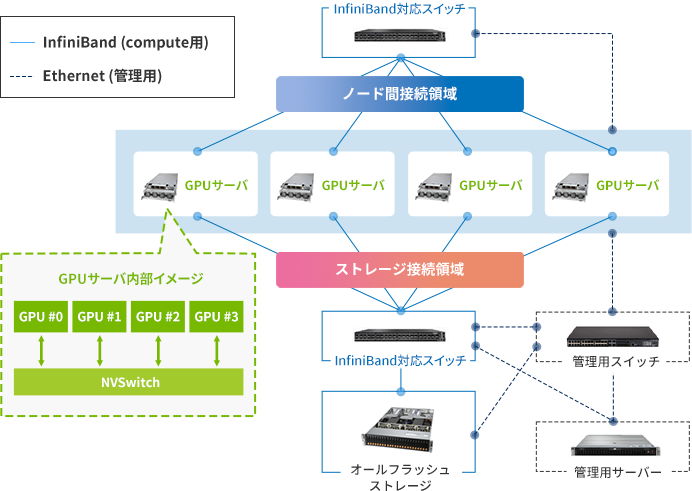
図4. マルチノードGPUシステムの構成例。「GPUクラスター」と呼ばれることもある。
実際に当社においてもマルチノードGPUシステムのお問合せや引き合いが多くなっており、構築実績も増えつつあります。
マルチノードGPUシステムの構築にあたっては、予算の中でできるだけ高い性能を得るためのサイジング(ノードの台数およびGPUの個数、インターコネクトやネットワークの選定とトポロジー設計、ストレージの選定など)や、設置環境(電源容量、空調、設置重量)、並列化手法、運用方法など、さまざまなポイントについて検討が必要です。本稿ではその中のノード間インターコネクトについて説明します。
*1: NVIDIAが2023年11月に発表したNVIDIA H200 Tensor コア GPUは、1基あたりのVRAM容量が141GBに拡張されています。NVIDIA H200 Tensor コア GPUの発売日は2024年1月時点で未定です。
性能を律速するノード間インターコネクト
マルチノードGPUシステムで大規模言語モデルを開発する場合、(1) ニューラルネットワークのレイヤーで分割する「パイプライン並列」と、(2) テンソル計算を分割する「テンソル並列」のふたつを適切に組み合わせる必要があります(図5)。いずれの並列も、モデルパラメータの同期、勾配データの集約、並列処理の中間結果の転送など、GPU間で多くの通信が発生します。そのため、GPU間を結ぶインターコネクトによって性能が律速されます。
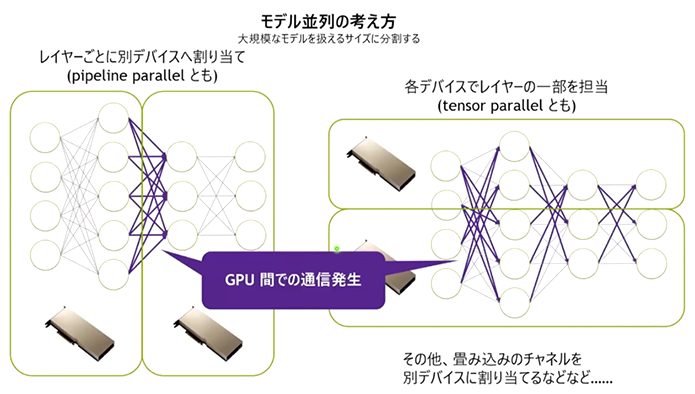
図5. パイプライン並列(左)とテンソル並列(右)の概念図と、GPU間のトラフィックのイメージ
では、マルチノードGPUシステムにおいて重要となるノード間のインターコネクトには何を選択すればいいのでしょうか。NTTPCがおすすめしているのが「InifiniBand」です(図6)。
InifiniBandは1990年代後半にインテルが主体となって開発されたインターコネクト・テクノロジーです。現在は業界団体のInfiniBand Trade Associationがエンハンスを担っていて、2024年1月時点で、54.54GbpsのFDR(Fourteen Data Rate)、100GbpsのEDR(Enhanced Data Rate)、200GbpsのHDR(High Data Rate)、400GbpsのNDR(Next Data Rate)が主に使われています(いずれも4レーン構成の場合)。

図6. サーバーノード側に実装するInifiniBand HCA(Host Channel Adapter)の例。
かつてはMellanox社が提供していたが、2020年4月にNVIDIAに買収されたため、
現在はNVIDIAから提供されている。写真は「NVIDIA ConnectX-7」。
InifiniBandの特長とEthernet(RoCE)との比較
EthernetもInifiniBandと同じように高速化に向けた技術開発が進められていて、すでに100Gbps、200Gbps、および400Gbpsが実用化されていますので、データレートとしてはInifiniBandと同等です。
ただしEthernetは、TCP/IPというプロトコルが標準で実装されていることもあり、レイテンシ(遅延)が大きく、ノード間インターコネクトとしては最適とは言えません。また、あるノードのデータを別のノードに転送するにはそれぞれのOSの介在を必要とするため、オーバーヘッドが大きくなってしまいます。
InifiniBandは、そうした課題を解決するために、あるノードのメモリの特定領域を、OSの介在なく、別のノードの特定領域に直接転送するRDMA(Remote Direct Memory Access)機能を当初から実装しています。このRDMAこそがInifiniBandの最大の特長と言えます。
ただし、従来のRDMAはサーバーのメインメモリのみを対象にしていました。GPUのVRAMの内容を別のノードのGPUのVRAMにコピーするには、VRAMの内容をまずメインメモリにコピーし、メインメモリの内容をRDMAによって別のノードのメインメモリに転送して、最後にVRAMにコピーする必要があったわけです。RDMAとはいえGPUの観点からは大きなオーバーヘッドが生じていました。
この課題に対応したのがNVIDIAです。InifiniBandのコントローラASICやアダプタを開発していたMellanox社(その後NVIDIAが買収)と共同で、RDMAの転送対象をVRAMに拡張した「GPUDirect v2」(現在v2表記はなく単に「GPUDirect」)を2011年にサポートしたのです(図7)。GPUDirectの登場によってマルチノードGPUシステムのスケーラビリティは大幅に向上しました。
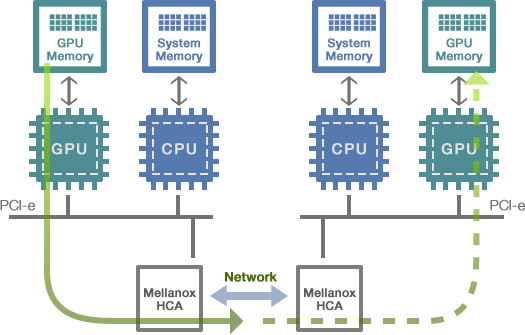
図7. GPUのVRAM間を直接転送するGPUDirectのイメージ。
メインメモリやOSを介することなくVRAM内のデータをオーバーヘッドなく転送できる。
ちなみに、InifiniBandのパケットをEthernet上にカプセル化するRoCE(RDMA over Converged Ethernet、ロッキー)と名付けられたプロトコルも開発されていて、インターコネクトの選定においては必ずといっていいほど「InifiniBand vs Ethernet(RoCE)」の比較が行われます。
RoCEにおいてもGPUDirectを利用できますが、ロスレスEthernetを構成する必要があり、通常のEthenetに比べて設定や運用の難易度が高くなります。また、InifiniBandパケットなどの知識も要求されます。スイッチのレイテンシもEthernetスイッチのほうがInifiniBandスイッチよりも一般に大きめです。
大規模言語モデルを開発するシステムにおいては、テンソル計算を行うGPUリソースがもっとも重要であり、すなわち、高額なGPUを遊ばせないためにも、GPUの使用率をいかに高めるかがシステム設計の鍵を握ります。こうした理由から、NTTPCでは、性能やスケーラビリティを追求するという観点からも、RoCE(Ethernet)ではなくInfiniBandをお勧めしています。
なお、GPU同士を結ぶインターコネクトのほかに、ノード同士を結ぶネットワークも必要です。たとえば、並列タスクの配分や同期、エラー発生時のノード切り離しやデータの修復、ノードの追加や削除などに必要なデータやプロセスのやりとりが主な役割です。こうしたノード間ネットワークには一般にEthenetが使われます。
次回はInfiniBandを使った実際の構成例やソリューション選定のポイントについて説明します。