



基礎知識
ディープラーニングにGPUが求められる理由・ビジネスにおける活用方法
2025.04.15

GPUエンジニア

ディープラーニング(深層学習)は、画像認識や自然言語処理、音声解析など様々な分野で活用されていますが、その実行のためには膨大な計算処理が必要です。特に、ニューラルネットワークの学習や推論では、大量の行列演算を高速に処理する能力が求められ、従来のCPU(中央処理装置)だけでは膨大な計算時間がかかることがあります。
そこで不可欠となるのがGPU(画像処理装置)です。もともとはグラフィック処理向けに開発されたGPUですが、その並列計算能力はディープラーニングの要求に対応し、現在ではAI開発の必須インフラとなっています。
本記事では、企業のAI導入やシステム構築に携わる方向けに、GPUがディープラーニングに求められる理由と、ビジネスにおけるGPUの最適な活用方法についてわかりやすく解説します。
NTTPCは、お客さまの用途に最適なGPUソリューションをご提案します。
GPUソリューションをご検討中の企業様は、お気軽にご相談ください。
目次:
- ディープラーニングとGPUの基礎知識
1.1 ディープラーニングとは:人間のように学習するAIの仕組み
1.2 ディープラーニングの主なプロセス:入力から出力までの流れ
1.3 GPUとは:AI処理を支える高性能ハードウェアの特徴 - ディープラーニングにGPUが必要な4つの理由
2.1 計算速度:並列処理による高速な学習と推論
2.2 メモリ性能:VRAMによる大規模データの高速処理
2.3 最適化技術:専用ハードウェアによる行列・テンソル演算の効率化
2.4 拡張性:分散学習とフレームワーク対応によるスケーラビリティの確保 - GPUによるディープラーニング高速化の手法
3.1 データローディングの最適化:学習の待機時間を減らしスループットを向上
3.2 半精度(FP16)やINT8の活用:軽量・高速・小メモリな学習と推論を実現
3.3 分散学習の活用:複数GPUによる大規模モデルの高速学習 - まとめ
1. ディープラーニングとGPUの基礎知識
ディープラーニングとGPUは密接に関連しており、ディープラーニングの計算処理を高速化する上でGPUの活用が不可欠です。まず、それぞれの基本的な特性および用語について説明します。
1.1 ディープラーニングとは
ディープラーニングは、機械学習の一分野であり、多層のニューラルネットワークを用いてデータから自動的に特徴を抽出・学習する手法です。従来のルールベースのアルゴリズムとは異なり、膨大なデータからパターンを学習し、高度な認識や予測を行うことができます。
1.2 ディープラーニングの主なプロセス
ディープラーニングの処理は、主に3つのプロセスに分けられます。
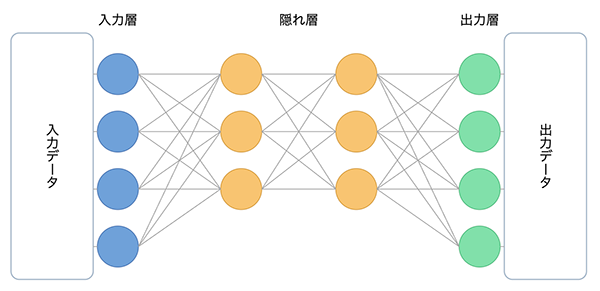
図1.ディープラーニングの主なプロセス
- データの入力(入力層):画像・テキスト・音声データを数値化し、モデルに入力する。
- 特徴量の抽出(中間層/隠れ層):複数の層(レイヤー)がデータの特徴を段階的に抽出し、重みを最適化する。
- データの出力(出力層):入力データの特徴に基づいた分類・予測・生成などの処理結果となるデータを出力する。
これらのプロセスには、大量のデータ処理が必要になり、特に特徴量の抽出では、層を重ねることでより高次元な特徴を抽出できるようになり、複雑なパターンや関係性の学習が可能となります。
しかしながらこれらの処理は、GPUを用いなければ現実的な時間での処理が難しく、ビジネスの場でディープラーニングを効率的に活用するには、GPUの導入が不可欠です。
1.3 GPUとは
GPUは、もともとコンピュータグラフィックス処理のために開発されました。しかし、数千~数万のコアを活用した並列計算が可能なアーキテクチャが、ディープラーニングの計算処理にも極めて有効であることが判明し、AI計算の中核技術として活用されるようになりました。
2. ディープラーニングにGPUが必要な4つの理由
ディープラーニングの学習や推論には膨大な計算が必要となり、高速かつ効率的に処理するためにはGPUの活用が不可欠です。ここでは、「なぜディープラーニングにGPUが必要なのか?」 について、以下の表にある4つの観点から理由を解説します。
| 観点 | GPUが必要な理由 |
|---|---|
| 計算速度 | 並列処理・低精度演算 |
| メモリ性能 | VRAMの大容量・高速メモリアクセス |
| 最適化技術 | 行列・テンソル演算の最適化 |
| 拡張性 | 分散学習のサポート・フレームワークとの親和性 |
2.1 計算速度:並列処理による高速な学習と推論
ディープラーニングでは、大量のデータを処理し、膨大な計算を繰り返すことで精度を向上させます。しかし、従来のCPUは、逐次処理(1つのタスクを順番に処理)のため、大規模な学習には時間がかかりすぎるという課題がありました。
GPUによる解決策
GPUは、数千~数万個のコアを活用した並列処理(複数のタスクを同時に処理)が可能なため、CPUと比較して圧倒的な計算速度を実現できます。
大規模な並列処理
- GPUは一度に多数の演算を処理できるため、ディープラーニングの学習時間を大幅に短縮できます。
- 例えば、画像認識や自然言語処理(NLP)のモデルでは、1つの学習をCPUで処理すると数週間かかることもありますが、GPUを活用することで数日~数時間に短縮できます。
低精度演算※1の活用
- GPUは、FP16(半精度浮動小数点)やINT8(整数演算)などの低精度演算を活用し、学習や推論の処理速度を向上させることができます。
- 特に推論時には、INT8による量子化を利用することで、軽量なモデルを高速かつ省電力で動作させることが可能になります。
※1 低精度演算とは?
低精度演算とは、計算精度を意図的に下げることで、メモリ使用量を減らし演算速度を向上させ、消費電力を抑える技術です。
2.2 メモリ性能:VRAMによる大規模データの高速処理
ディープラーニングでは、大量のデータとモデルのパラメータを一時的に保存しながら計算を進めるため、メモリ性能(VRAM※2)が重要な役割を果たします。
※2 VRAM(Video RAM)とは?
VRAMとは、GPUに搭載されている専用のメモリです。
ディープラーニングの計算では、大量のデータやモデルのパラメータを保持しながら、高速に処理を行う必要があります。
GPUによる解決策
GPUにはVRAMが搭載されており、CPUのメインメモリ(RAM)に比べて高速なデータ転送と大容量のストレージを実現しています。
VRAMの大容量と高速メモリアクセス
- GPUのVRAMは、CPUのRAMよりも帯域幅が広く、学習データやモデルの重みをスムーズに処理できます。
- 特に、大規模なディープラーニングモデル(GPT-4o、Stable Diffusion など)では、モデルのサイズが数十GB以上になることがあり、十分なVRAMがなければ計算が停止してしまいます。
高解像度データの処理
- 画像解析や動画解析では、高解像度データをリアルタイムで処理する必要があります。
- GPUのVRAMを活用することで、高精細な画像・映像データを効率的に処理し、応答速度を向上させることができます。
2.3 最適化技術:専用ハードウェアによる計算の効率化
ディープラーニングでは、行列演算およびテンソル演算※3が頻繁に行われます。特に、ニューラルネットワークの各層で行われる畳み込み演算や行列の乗算は計算負荷が高く、一般的なCPUでは処理が追いつきません。
※3 行列演算・テンソル演算とは?
行列演算とは、数値データを行と列の形(行列)で表現し、掛け算や加算を行う計算 です。さらに、行列を拡張した多次元データを扱う計算が「テンソル演算」 で、ディープラーニングでは画像やテキストなどの複雑なデータ処理に活用されます。
GPUによる解決策
ディープラーニング向けに最適化された演算ユニットを搭載したGPUを利用することで、高速かつ効率的に学習や推論を行うことが可能です。
行列・テンソル演算の最適化
- GPUは、行列演算に対応したNVIDIAが開発したプラットフォームであるCUDA※4を活用することで、ディープラーニングの計算を最適化できます。
※4 Tensor Core、CUDAとは?
Tensor CoreとCUDAは、どちらもNVIDIAが開発した技術で、ディープラーニングの計算を高速化するために使われています。
Tensor Core
行列演算を最適化する専用ハードウェアで、ディープラーニングの学習や推論の処理速度を向上させます。
CUDA
GPU向けの並列計算プラットフォームで、プログラミングを通じてGPUの計算能力を最大限に活用し、ディープラーニングや科学計算などの大規模データ処理を効率化します。
2.4 拡張性:分散学習とフレームワークの最適化
ディープラーニングモデルの規模が拡大するにつれ、単一のGPUでは処理が困難になるケースが増加します。
GPUによる解決策
GPUは、複数のデバイスを組み合わせて並列処理を行う分散学習※5や、ディープラーニングフレームワークとの統合により、より大規模な学習が可能になります。
分散学習のサポート
- 複数のGPUを活用することで、大規模なモデルの学習を高速化できます。
- データ並列、モデル並列、パイプライン並列などの手法を組み合わせることで、モデルのスケールアップが可能になります。
- 例えば、GPT-4oのような大規模言語モデルでは、数千台のGPUを使った分散学習が必要になります。
ディープラーニング向けフレームワークとの親和性
- 機械学習を行う際には、一般的に「ディープラーニングフレームワーク」と呼ばれるツールを活用します。これらのフレームワークはあらかじめ多くの機能が実装されており、自分で処理の一部を追加・実装するだけで、一定の品質を持つプログラムを効率的に構築することができます。
- 代表的なフレームワークに、Googleが開発した「TensorFlow」や旧Facebookが開発を主導した「PyTorch」などがあります。TensorFlowは大規模なデータ処理に強く、商用利用しやすい点が特長です。一方、PyTorchは柔軟性が高く、研究用途で広く使用されています。
- TensorFlowやPyTorch※6などの主要なフレームワークは、GPU向けに最適化されており、CUDAなどのライブラリを活用して処理を高速化できます。
- 開発者は特別な設定をしなくても、GPUを活用した最適な環境を利用できるため、AI開発の効率が向上します。
※5 分散学習とは?
分散学習とは、複数のGPUやクラウド環境を活用し、ディープラーニングの計算を分散して並列実行する手法です。
※6 機械学習を行う際には、一般的に「ディープラーニングフレームワーク」と呼ばれるツールを活用します。これらのフレームワークはあらかじめ多くの機能が実装されており、自分で処理の一部を追加・実装するだけで、一定の品質を持つプログラムを効率的に構築することができます。
代表的なフレームワークには、Googleが開発した「TensorFlow」と、Meta(旧Facebook)が開発した「PyTorch」があります。TensorFlowは大規模なデータ処理に強く、商用利用しやすい点が特長です。一方、PyTorchは柔軟性が高く、研究用途で広く使用されています。
上記のように、ディープラーニングの計算負荷を軽減し、より高速で高精度なモデルを開発するためには、GPUの活用が不可欠 です。GPUの特性を理解し、適切な環境を選択することで、AIの活用をさらに加速させることができるでしょう。
3. GPUによるディープラーニング高速化の手法

GPUの性能を最大限に引き出し、ディープラーニングの学習や推論を効率的に行うためには、適切な最適化手法を活用することが重要です。GPUの計算能力を活かしながら、メモリの効率的な利用や演算精度の調整、複数のGPUを活用した並列学習を導入することで、処理時間を短縮し、パフォーマンスを向上させることができます。
3.1 データローディングの最適化
ディープラーニングの学習では、データローディング(大量のデータをGPUに読み込み)を行い、処理する必要があります。データの読み込みが最適化されない場合、GPUが計算を待つ時間が長くなり、パフォーマンスが低下します。そのため、ミニバッチサイズ※7の調整やデータの前処理を最適化することが重要です。
※7 ミニバッチサイズとは?
モデルが一度に処理するデータの単位です。バッチサイズが大きいほど学習の並列処理が効率的に進みますが、VRAMの使用量も増加します。
ミニバッチサイズの調整
適切なサイズの選び方
- VRAMに余裕がある場合:できるだけ大きなバッチサイズを設定し、学習速度を向上させます。
- VRAMが不足する場合:小さめのバッチサイズを設定し、モデルの安定性を優先させます。
データの前処理をGPU側で実行
ボトルネックを回避するための工夫
- データの前処理(画像のリサイズ、正規化、データ拡張など)をCPUで実行すると、データ転送の遅延が発生し、GPUが待機する時間が長くなります。
- GPU上でデータ前処理を並列実行することで、学習のスループットを向上が期待されます。
PyTorchやTensorFlowの活用
- PyTorchの DataLoader に num_workers を設定することで、データの読み込みを並列化し、学習プロセスをスムーズにします。
- TensorFlowの tf.data API を活用し、データのパイプラインを最適化させます。
3.2 半精度(FP16)やINT8の活用
GPUは、計算精度を調整することで、メモリ使用量を抑えつつ、計算速度を向上させることができます。
学習時の計算をFP16で実施する
FP16(半精度浮動小数点)の特徴
- FP32(単精度浮動小数点)に比べてメモリ使用量を半減できるため、大きなバッチサイズで学習が可能になります。
- NVIDIA GPUの場合、Tensor Coreに対応したGPUを活用することで、FP16演算が高速化されます。
浮動小数点のビット数と違いとは?
- 浮動小数点形式には、FP32・FP16のほか、近年ではFP8やFP4なども登場しており、用途に応じて使い分けられています。
- 「FP」の後ろに付く数字(4、8、16、32など)は、その数値を何ビットで表現するかを示しており、ビット数が小さいほど処理は軽く高速になりますが、その分、数値の表現精度は下がるというトレードオフがあります。
活用方法
- PyTorchのAMP(Automatic Mixed Precision)を使用することで、自動的に適切な精度で演算を実行し、精度と速度のバランスを最適化できます。
- TensorFlowのMixed Precision APIを利用し、演算の一部をFP16に変換することで、メモリ負荷を軽減しながら高速な学習を実現できます。
推論時にINT8に量子化
INT8(8ビット整数演算)の特徴
- INT8に量子化することで推論の処理速度をさらに向上できます。
- モデルのサイズが圧縮されるため、組み込み機器やエッジデバイスでも動作しやすくなります。
活用方法
- TensorFlowのTFLite(TensorFlow Lite)を使い、モデルをINT8に変換することで、モバイルやIoTデバイス向けの軽量なAIを実装可能です。
- NVIDIA TensorRTを使用し、学習済みモデルを最適化することで、推論速度を大幅に向上させることができます。
3.3 分散学習の活用
複数のGPUを活用する分散学習を導入することで、学習時間の短縮や大規模モデルの学習が可能になります。学習の手法は大きく3つに分けられます。
データ並列学習(Data Parallelism)
概要
- 同じモデルを複数のGPUで並列に学習し、それぞれのGPUが異なるミニバッチを処理する方式です。
- 各GPUが計算した勾配を同期し、最終的なモデルの更新に反映します。
活用例
- 大規模な画像認識モデル(ResNet、EfficientNetなど)の学習に適しており、学習時間を短縮できます。
モデル並列学習(Model Parallelism)
概要
- モデルの異なる部分を各GPUに分割し、それぞれが異なる演算を担当する方式です。
- モデルサイズが大きすぎて単一のGPUに収まらない場合に有効です。
活用例
- 大規模言語モデル(LLM:GPT-4o、BERTなど)の学習で、巨大なニューラルネットワークを複数のGPUに分散して処理することができます。
パイプライン並列学習(Pipeline Parallelism)
概要
- モデルを複数のステージに分け、各ステージを異なるGPUが担当する方式です。
- 各GPUが順番に処理を引き継ぐことで、学習の負荷を分散し、VRAMの使用量を抑えながら大規模なモデルを学習できます。
- GPU間でデータが流れるように処理されるため、スループットが向上し、計算効率を最大化できます。
活用例
- Transformerモデルなど、シーケンシャルな処理が必要なモデル(順序が重要なモデル)に適しており、大規模な自然言語処理モデルの学習に利用されます。
- 例えば、GPT-4oのような大規模言語モデルでは、エンコーダ層・デコーダ層を異なるGPUに配置し、計算負荷を分散することで、学習プロセスを効率化できます。
GPUの性能を最大限に活かすためには、データの読み込みを最適化し、計算精度を調整しながら、必要に応じて複数のGPUを活用することが重要です。
適切な最適化手法を導入することで、GPUのリソースを無駄なく活用し、効率的なAI開発を進めていきましょう。
4. まとめ
ディープラーニングの発展に伴い、GPUの重要性はさらに高まっています。本記事では、GPUがディープラーニングに適している理由から、適切なGPUの選び方、GPUの最適化手法までを詳しく解説しました。
GPUを導入する際は、学習タスクの規模、リアルタイム処理の必要性、コストなどを考慮し、最適なインフラを設計することが求められます。
NTTPCでは、ミッションクリティカルな商用AIサービスから、高性能が求められるディープラーニングの活用、研究開発基盤の構築まで、用途や予算に合わせた適切なAI基盤の設計・構築が可能です。GPU導入をご検討の企業様は、お気軽にご相談ください。
※NVIDIA、CUDAは、米国およびその他の国におけるNVIDIA Corporationの商標または登録商標です。
※TensorFlow、GoogleはGoogle LLCの登録商標です。
※FacebookはMeta Platforms, Inc.の登録商標です。