



基礎知識
AIモデル推論の高速化を図る「AIアクセラレータ」の各ハードウェアと比較
2025.04.08

GPUエンジニア

パソコンやサーバーの心臓部とも言えるCPUは、どのようなアプリケーションにも対応できるように、汎用性や万能性を重視して設計されています。ブラウザ、メーラー、オフィスアプリケーション、データベース、ネットワーク処理など、さまざまなアプリケーションを利用できるのも汎用性の高さのおかげです。
その代わり、グラフィクス処理やAIの学習処理などはそれほど得意ではありません。動くことは動いても、満足のいく性能は得られません。
そこで、汎用性の高いCPUに、特定の処理に最適化したハードウェアを組み合わせる方法が開発されました。そうしたハードウェアを「アクセラレータ」(加速装置)と呼び、用途に応じたさまざまなアクセラレータが登場しています(表1)。
「AIアクセラレータ」はその名のとおり、AIの学習や推論の高速化を実現する専用ハードウェアです。ニューラルネットワーク処理を高速化することからNPU(Neural network Processing Unit)と呼ばれることもあります。GPU(Graphics Process Unit)は、画像処理やディープラーニング向けアクセラレータの中で最もスタンダードなハードウェアです。
表1. アクセラレータの例
| 略称 | 名称 | 主な機能や用途 |
|---|---|---|
| GPU | Graphics Processing Unit | グラフィクス処理やディープラーニング |
| FPU | Floating Point Unit | 浮動小数点演算 |
| NPU | Network Processing Unit | パケット処理など |
| DPU | Data Processing Unit | データトラフィック処理や暗号化処理 |
| DSP | Digital Signal Processor | 信号処理やオーディオ処理 |
| NPU | Neural network Processing Unit | ディープラーニングや生成AI |
AIアクセラレータの必要性とメリット
AIアクセラレータは学習処理および推論処理の高速化を実現する専用の回路で構成されています。汎用性の高いCPUとの違いは大きく次の3つです。
定性的な表現になりますが、ディープラーニングや生成AIの学習や推論の性能を最大化するようなアーキテクチャが採用されています。
数多くの演算回路(コア)を搭載していて、複数の演算を並列に処理することができます。たとえば、NVIDIA H100 Tensorコア GPU(SXM5ボードフォームファクター品種)の場合、演算の基本ユニットである FP32 CUDAコアは16,896個、積和演算ユニットであるTensorコアは576個にのぼります(図1)。
近年の研究でモデルの数値表現を落としても推論精度はそれほど低下しないことが分かっています。数値表現の種類が多いほどさまざまなチューニング(モデルの軽量化)に対応できます。アクセラレータにもよりますが、単精度浮動小数点(FP32)、倍精度浮動小数点(FP64)、半精度浮動小数点(FP16)、整数(INT8やINT4)などの数値表現がサポートされています。
AIアクセラレータとCPUとの直接的な性能比較はなかなか難しいのですが、数十倍から数千倍以上の性能差があると考えられます。つまり、大規模な学習や推論を行うにはAIアクセラレータは必須と言えます。
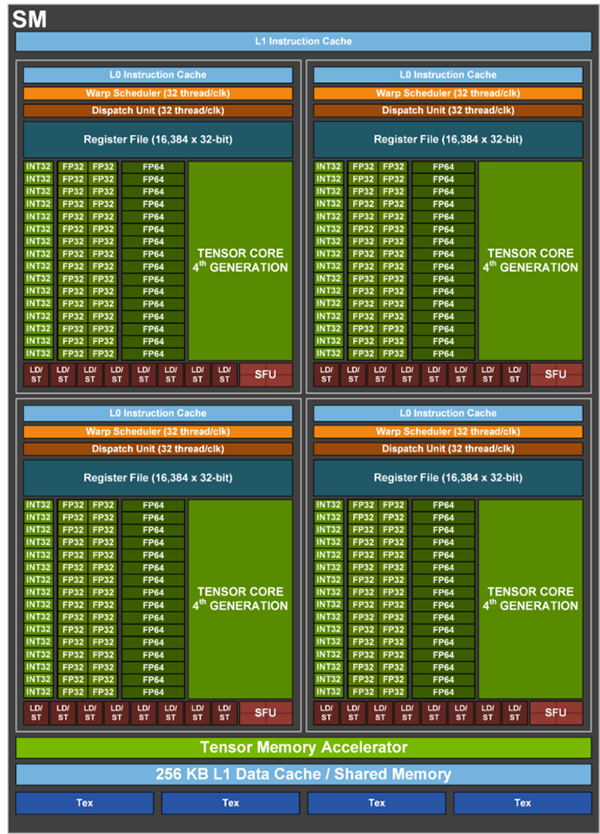
図1. NVIDIA H100 Tensorコア GPUの内部構成の一部
#基本的な演算ブロックであるSM(Streaming Multiprocessor)を
132個搭載している(SXM5ボードフォームファクター製品の場合)。
それぞれのSMは、図のように、FP64 CUDAコア×16個×4組、FP32 CUDAコア×32個×4組、
INT32 CUDAコア×16個×4組、および第4世代Tensorコア×1個×4組で構成されている。
【https://developer.nvidia.com/ja-jp/blog/nvidia-hopper-architecture-in-depth/】
次に、NVIDIA GPUのそれぞれの演算器が、どのような役割を持っているかを記します。
表2. NVIDIA GPUの演算器の役割
| コア種類 | 主な役割 | 概要 |
|---|---|---|
| CUDAコア | 汎用並列処理(グラフィックスレンダリング、物理シミュレーションなど) | CUDAプログラミングモデルを活用し、多数の小規模プロセッサが同時に多様な計算を実行するための基本ユニット |
| Tensorコア | AI・ディープラーニングの行列演算 | 高速な行列乗算と畳み込み演算を実現し、ニューラルネットワークのトレーニングや推論の効率を大幅に向上 |
| RTコア ※ | リアルタイムレイトレーシングの演算 | 光線追跡処理を専用に行い、リアルタイムで高品質なライティングや影、反射を計算することで、よりリアルな描画を実現 |
※H100にはRTコアは搭載されていない。
AIアクセラレータを用途で分類
ここまでは「AIアクセラレータ」という用語で一括りに説明してきましたが、実際にはひとつのアクセラレータですべてのニーズを満たすのは難しく、適材適所で使い分ける必要があります。そこで、サーバーやクラウド、パソコンやデジタル機器などのエッジ、および産業機器などでの使用に適したAIアクセラレータについて説明します。
LLMの開発に使うシステム、あるいは、大学の計算センターなど多数のユーザーが利用するシステムには、ハイエンドのAIアクセラレータが適します。学習に用いる大きなデータセットを扱えるだけの大容量メモリを備えていること、そしてなによりも積和などの演算性能が高いことが要件に挙げられます。
また、推論に時間をかけてより精度の高い答えを得る「Inference-Time Compute」や「リーズニング(reasoning)」といった技術が提唱されたことで、学習だけではなく推論においてもハイエンドAIアクセラレータの需要が高まりつつあります。
ハイエンド分野はNVIDIAのデータセンター向け製品が大きなシェアを持っています。Amazon、Microsoft、Googleは、自社のクラウドサービスで提供することを目的に、独自のAIアクセラレータを開発しています。
パソコン、スマートフォン、産業機器などのいわゆるエッジにもAIアクセラレータを搭載する動きが広がっています。用途は推論が主体です。
電力が潤沢に供給され冷却性能も高いサーバーシステムとは違って、消費電力が小さく発熱が少ないこと、回路サイズが小さいこと、コストが安いこと、といった要件が求められます。
エッジ向けのAIアクセラレータは群雄割拠で、さまざまなベンダーからソリューションが供給されています。単体デバイス型、CPU(SoC:System on a Chip)内蔵型、ボード提供型、USBアダプタ型などのバリエーションがあります。
また、NVIDIA GeForceやAMD RadeonなどのグラフィクスボードをAIアクセラレータとして使用する方法もあります。座標変換処理などを実行するシェーダー回路を数値演算に使う手法が2000年代半ばに考案されたことがきっかけになって、GPUはグラフィクスだけではなく、シミュレーション(CAE)、機械学習、ディープラーニング、さらには生成AIにも利用されるようになりました。上記のハイエンドAIアクセラレータが今もGPUと呼ばれているのは、そういった歴史があるからです。なお、GPUをグラフィクス以外の用途に使うことを「GPGPU(General-Purpose computing on Graphics Processing Units)」と呼ぶこともあります。
ハードウェアロジックをプログラミングできるFPGA(Field-Programmable Gate Array)をAIアクセレータとして使用する方法です。
① アルゴリズムに最適化したロジックを実装できること、② 他のハードウェア回路やSoCコアとの統合によって小型化や低消費電力化が図れること、③ 世代交代の早いAIアクセラレータとは違ってFPGA品種は長期供給が一般的であり、EOL(生産終了)を心配することなく最終製品を長期的にサポートできること、などがメリットです。FPGAは産業機器に広く用いられているほか、アルゴリズムの研究などにも用いられています。
大規模から小規模までさまざまな品種がラインアップされていますので、学習に適したハイエンドAIアクセレータから、エッジ用の小型AIアクセレータまで、幅広い実装が可能です。
表3. 用途で分類した代表的なAIアクセラレータの例
| 用途 | 代表的なAIアクセラレータ、メーカー |
|---|---|
| サーバー向け(主に学習) | ・NVIDIA H100/H200/B200 Tensorコア GPU ・AMD Instinct™ MI325X アクセラレータ ・Intel® Gaudi® 3 AI アクセラレーター ・Amazon AWS Trainium2 チップ ・Microsoft Azure Maia 100 AI Accelerator ・Google Cloud TPU Trillium |
| エッジ向け(推論) | ・NVIDIA Jetson(ボード)(図2) ・Google Coral Edge TPU USB Accelerator(USB) ・Intel® Core™ Ultra プロセッサー(NPU内蔵CPU) ・Apple M3 Ultra(Neural Engineコア内蔵CPU) ・Qualcomm Snapdragon 8 Gen3(Hexagon NPU内蔵CPU) ・AMD Versal AI Edge Series ・そのほか多数 |
| 産業機器向けや研究開発向け | ・AMD Versal AIコアシリーズ(旧Xilinx) ・Altera Agilex™ 7シリーズ |

図2. エッジ用AIアクセラレータのひとつであるNVIDIA Jetson Orin Nanoシリーズ
#INT8性能は67TOPS(8GB品)、消費電力は最大25W、アーキテクチャはAmpere世代である。
インテリジェントロボットなどへの搭載に適する。
AIアクセラレータを生かす開発環境
AIアクセラレータ(半導体)だけではAIアプリケーションを構築することはできません。その並列性を生かすプログラミングテクニック、並列コンパイラを含めた開発環境、基本的な機能を網羅したライブラリ群、開発のワークフロー全体をサポートするツールチェーンやフレームワークなどが揃っていることが重要です。また、コミュニティの活動が盛んであることもソフトウェア開発においては望ましいと言えます。
この領域で大きくリードしているのがNVIDIAです。プログラミング環境CUDAを筆頭に、LLMなどの開発をエンドツーエンドでサポートするクラウドネイティブの開発フレームワークNeMo Framework(図3)、LLMの学習に必要なライブラリで構成されたMegatron Core、トレーニング済みモデルなどのリソースを集めたNGC Catalogなどを、一部を除いて無償で提供しています。また、創薬に特化したクラウドサービスBioNemoなど、特定のアプリケーションを対象にした環境も豊富です。
AIアクセラレータを提供している他の半導体ベンダーもさまざまな環境を用意しています。AIアクセラレータの選定にあたってはツール環境についても検討すると良いでしょう。
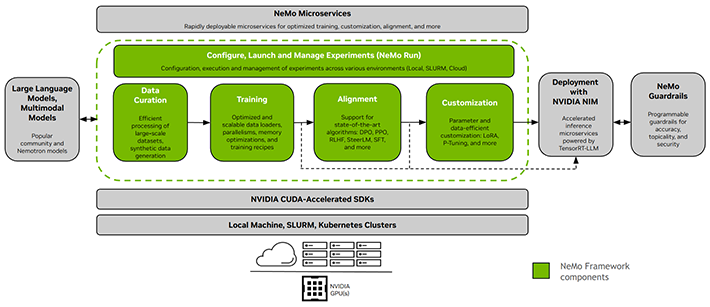
図3. LLMの開発をサポートするNeMo Frameworkの概要
#データキュレーション、トレーニング、アライメント、カスタマイゼーションなど、
さまざまなツールで構成されている(緑部分)。
【https://docs.nvidia.com/nemo-framework/user-guide/latest/overview.html】
AIアクセラレータの今後とまとめ
生成AIの普及を背景にAIアクセラレータの需要が急増しています。学習に適したハイエンドのAIアクセラレータと、エッジでの推論に適したローパワーのAIアクセラレータなど、ニーズや用途に応じたさまざまなAIアクセラレータが登場しています。
ハイエンド系は現在のところNVIDIAが圧倒的なシェアを獲得しています。GPGPUとしての使い方が始まった2000年代半ばから続くノウハウとエコシステム、カスタマーベース(顧客のソフトウェア資産や知見)、業界をリードする性能、充実した開発環境、膨大な投資による継続的な新製品投入、などがその理由です。実質的にほぼ一択と考えていいでしょう。ちなみに同社は、CPUにアクセラレータを組み合わせたシステムを「アクセラレーテッド・コンピュータ」(またはアクセラレーテッド・コンピューティング)と位置付けています(図4)。
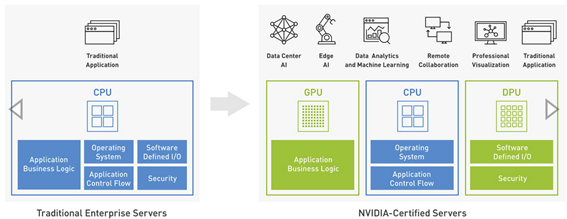
図4. NVIDIAが示すアクセラレーテッド・コンピュータ(コンピューティング)
#汎用性の高いCPUを中心に、AIを加速するGPUやデータ処理を
加速するDPUを配置したアーキテクチャを提唱している。
【https://blogs.nvidia.co.jp/blog/what-is-accelerated-computing/】
一方のエッジ向けはさまざまな選択肢があります。推論をエッジだけで完結するのかクラウドに渡して答えをもらうのか、許容される電力や発熱はどれぐらいか、回路サイズの制約はあるかなど、アプリケーションごとにニーズが異なるためです。基本的にはプロセッサやマイコンに内蔵される方向に進んでいくでしょう。
独自のAIアクセラレータの開発に取り組んでいるAIスタートアップも少なくありません(たとえば、日本のPreferred Networks、カナダのUntether AIやTenstorrent、アメリカのCerebras SystemsやSambaNova Systemsなど)。こうした企業から革新的なAIアクセラレータ製品が発表されて、勢力図が塗り替わる可能性もあります。
生成AIアプリケーションの拡大と合わせて、AIアクセラレータの開発競争は引き続きホットな話題です。これからも注目していきたいと思います。
NTTPCは、ミッションクリティカルな商用AIサービスから、高いパフォーマンスが求められる研究開発基盤に至るまで、用途・予算に合わせた適切なAI基盤の設計・構築が可能です。GPUの導入を検討されている企業の方は、お気軽にお問い合わせください。
※NVIDIA、CUDA、GeForce、Jetsonは、米国およびその他の国におけるNVIDIA Corporationの商標または登録商標です。
※Amazon、AWSは、米国その他の諸国における、Amazon.com,Inc.またはその関連会社の商標です。
※Microsoft、Azureは、米国Microsoft Corporationの米国およびその他の国における登録商標または商標です。
※Google、Google Cloudは、Google Inc.の登録商標です。
※AMDは、Advanced Micro Devices,Inc.の商標です。
※インテルおよびIntel、Gaudi、Intel Core、Agilex、Alteraは、アメリカ合衆国およびその他の国におけるIntel Corporationまたはその子会社の商標または登録商標です。
※Appleは、Apple Inc.の商標です。
※Qualcomm、Snapdragonは、Qualcomm Incorporatedの商標です。
※本記事は2025年3月末時点の情報に基づいています。製品に関わる情報等は予告なく変更される場合がありますので、あらかじめご了承ください。製品名などは各社の商標または登録商標です。