AI / IoTのプラットフォームに NTTPCが選ばれる3つの理由
Reason 1
NVIDIA認定 エリートパートナー
『Best NPN of the Year』を2年連続で受賞
NTTPCは、NVIDIAのパートナー認定制度NPN (NVIDIA Partner Network)において、「DGX AI Compute Systems」「Compute」コンピテンシーで最上位レベルの「エリートパートナー」に認定されています。
「NVIDIA Partner Network Award」において、NVIDIA Partner Networkパートナーに贈られる国内最高のアワード『Best NPN of the Year』を2025年、2026年に連続受賞しました。さらに、NTTPC社員2名が、今回特別賞として卓越した技術力を持つエンジニアに贈られる『Best Personal Award』を受賞しています。
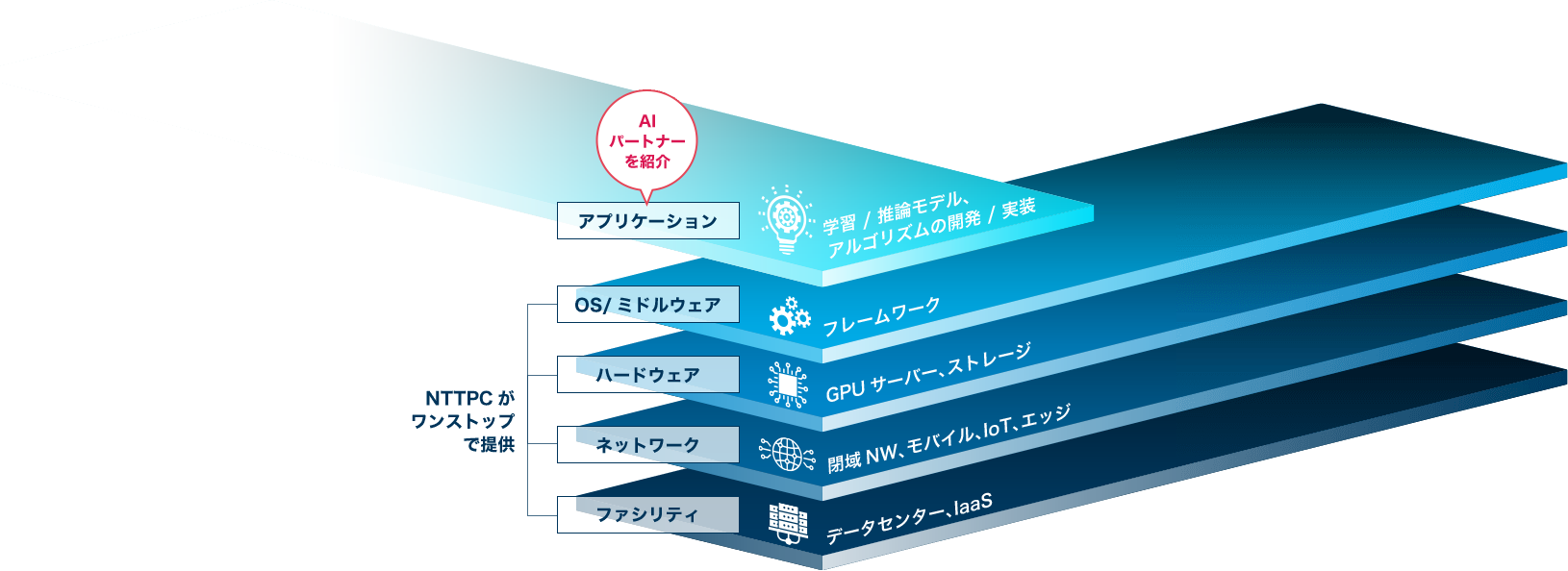
一方、GPUサーバー、ストレージ、ネットワーク等においては、マルチベンダーで多様なメーカーの製品を取り扱っており、お客さまの要件に合わせて最適な選択と組み合わせでの提案・構築を行うことが可能です。
Reason 2
生成AI/LLM開発に欠かせない
GPUクラスタ基盤の設計・構築ノウハウ
膨大なパラメータ数を持つ生成AI/LLMの学習基盤には、非常に高速な計算処理システムが求められるため、複数台のGPUサーバーによる分散処理が可能な「GPUクラスタ」の実装が必要不可欠です。
大規模なGPUクラスタの構築(※図1)は、サーバー単体の設計だけでなく、ノード間通信を高速化するためのインターコネクトやロスなくストレージと接続する技術、複数ユーザでクラスタを共有するためのマネジメントツールなど、ハードウェアからソフトウェア、ネットワークまで、多方面のエンジニアリングスキルを総動員した、いわば“総合格闘技”といえます。
単に複数のGPUを接続するだけでは、パケットロスやストレージ読み書き時の遅延などの要因により、クラスタ全体のパフォーマンスを引き出すことはできません。チューニングを行わない場合、性能は85%程度まで低下してしまう(※図2)とも言われています。
統合的なクラスタ設計・構築ノウハウを保有するNTTPCエンジニアが、大規模かつ複雑なジョブを実行可能なAI開発基盤をお求めのお客さまニーズに寄り添い、適切なチューニングを行うことで、GPUクラスタのパフォーマンスを最大化します。
NTT人間情報研究所さまが開発した国産LLM「tsuzumi🄬」のGPUプラットフォームをはじめ、さまざまなお客様へのGPUクラスタ導入実績を誇ります。
実績に裏打ちされた設計・構築ノウハウを持つNTTPCにお任せください。
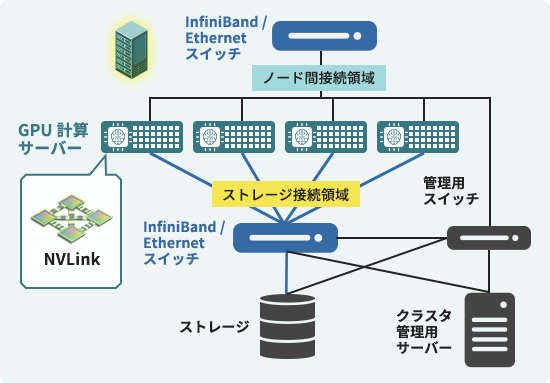
※図1

※図2
GPUクラスタ 導入事例



GPUクラスタ 技術コラム

生成AI/LLMの開発を加速するGPUクラスタ Vol.2:NVIDIA Base Command Manager ™ によるGPUクラスタの運用管理
2024.04.10
これまで2回にわたって、GPUクラスタ(マルチノードGPUシステム)におけるインターコネクトについて、その重要性や構成方法の一端を紹介しました。今回はGPUクラスタを効率的に利用するために不可欠な運用管理について取り上げたいと思います。

生成AI/LLMの開発を加速するGPUクラスタ Vol.1【後編】インターコネクトのトポロジーとシステム構成
2024.03.12
前編に続き、後編ではマルチノードGPUシステム向けのインターコネクトの具体的な構成方法を紹介します!

生成AI/LLMの開発を加速するGPUクラスタ Vol.1【前編】マルチノードGPUシステムとインターコネクト
2024.01.25
生成AIの実現に必要となる大規模言語モデル(LLM)。その開発に適した高速なマルチノードGPUシステム構築のポイントを紹介します!
Reason 3
GPUサーバーを効率的に運用する
インフラ環境をトータルで設計・提供
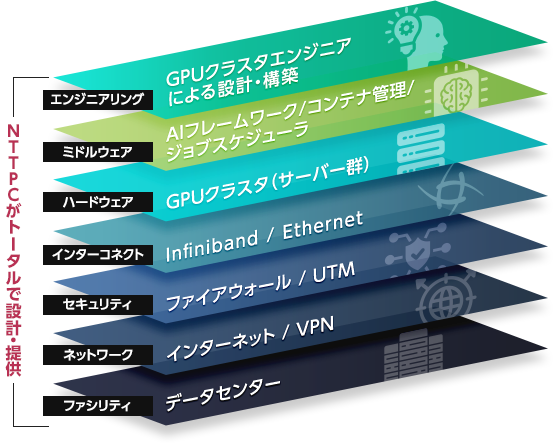
消費電力が高く発熱量の大きなGPUサーバーを運用するためには、設置環境となるファシリティも綿密に検討する必要があります。さらに、外部ネットワークへの接続やセキュリティの考慮も欠かせません。
自社独自のデータセンター、ネットワークサービスを提供するNTTPCは、GPUサーバーの電源管理、冷却方式(空冷 or 水冷)、外部ネットワーク接続、セキュリティ監視など、インフラ管理のためのナレッジも豊富に有しています。
運用管理をお任せいただけるプライベートクラウド型での提供も行っています。
ミッションクリティカルな商用サービスから、高いパフォーマンスが求められる研究開発基盤に至るまで、用途・予算に合わせた適切なインフラの設計・構築を行います。