



技術解説
生成AI/LLMの開発を加速するGPUクラスタ
Vol.2:NVIDIA Base Command Manager ™ によるGPUクラスタの運用管理
2024.04.10

GPUエンジニア
大野 泰弘

サーバーエンジニア
力石 誠也

ネットワークエンジニア
古賀 祥治郎

GPUクラスタの運用管理
これまで2回にわたって、GPUクラスタ(マルチノードGPUシステム)におけるインターコネクトについて、その重要性や構成方法の一端を紹介しました。
Vol.1 前編:マルチノードGPUシステムとインターコネクト
Vol.1 後編:インターコネクトのトポロジーとシステム構成
今回はGPUクラスタを効率的に利用するために不可欠な運用管理について取り上げたいと思います。
運用管理はいくつかのレベルあるいはレイヤーに分けられます。
まず、ハードウェア・レイヤーおよびハードウェアに近いレイヤーでは、次のような項目が挙げられるでしょう。
- 各ノードのプロビジョニング(OSほかソフトウェアのインストール)
- ログの収集、異常の検知、死活監視
- OS、ドライバ、ミドルウェアほかソフトウェアのアセット管理(バージョン管理、ライセンス管理、アップデート)
- 脆弱性(CVE)に関する情報収集、影響度調査、対策
- ネットワークやストレージの監視
また、ジョブ管理も必要です。
- ノードの登録(増設)または削除(減設)
- コンテナのデプロイ
- ジョブのスケジューリングおよびオーケストレーション
- 負荷に応じたロードバランシング
- 設備を複数プロジェクトで共有する場合はリソースの仮想化と割り当て
さらに、モデルの開発では、より上位レベルでの仕組みも必要です。
- フレームワークの選択
- 事前学習モデルなどひな形の活用(もしあれば)
- 学習データの収集、あるいは、既存データセットの活用
そのほか
- ユーザー管理および認証
- ドキュメント作成
といった機能も用意しておく必要があります。
OSSにこだわらず効率的な運用管理ツールの導入を提案
これら運用管理の手法やノウハウは科学技術計算(HPC)分野を中心に確立されてきました。OSS(オープンソースソフトウェア)を組み合わせる手法が一般的で、一例として次のようなOSSが使われています。
- プロビジョニング:Kickstart、Ansible
- スケジューリング:Slurm
- コンテナのデプロイや管理:Docker、Kubernetes
- 監視:Prometheus、Grafana、Alertmanager
- ログ管理:fluentbit、Elasticsearch、Kibana
OSSはコミュニティで揉まれていますので、基本的な機能は十分で、セキュリティに関してもCVEとパッチが発行されます。多種多様なツールがあるため、エンジニアの好みや運用管理の要件に応じて選択できるほか、OSSの使いこなしはエンジニアのスキル向上にも役立ちます。
では、GPUクラスタの運用管理はどうすればいいでしょうか。もちろん、HPCシステムと同様にOSSを活用することになんら問題はありません。
ただし、OSSの利用は基本的に自己責任ですし、技術サポートもありません(コミュニティに相談すれば解決のヒントをもらえる可能性はありますが)。また、使いこなすために高い技術力が求められることも少なくありません。
構築に要する工数や技術的難易度を減らすとともに、導入したGPUクラスタを速やかにサービスインするには、NVIDIAがリファレンスとして提供しているツール類を活用したほうが、確実かつ効率的と考えられます。
そうした理由からNTTPCは、OSSにこだわらずに効率的な運用管理ツールを選択すべきと考え、NVIDIAが提供する「NVIDIA AI Eneterprise」および「NVIDIA Base Command Manager ™ (旧Bright Cluster Manager)」の導入をお勧めしています。
NGCカタログをサポート付きで利用できるNVIDIA AI Enterprise
NVIDIA AI Enterpriseは、NVIDIAが動作検証を行った開発ツールやライブラリを、サポート付きで利用できるサービスです。
大規模言語モデルの開発フレームワーク「NeMo」、サイバーセキュリテイの開発フレームワーク「Morpheus」、メディカルイメージングの開発フレームワーク「Clara」など、NVIDIA NGC ™(図1)で提供されるコンテナ形式のアプリケーションフレームワークをフルサポート付きで利用できるのが特徴です(ただしNVIDIA NGC ™は、NVIDIA AI Enterpriseを契約していなくても、NGCアカウントに登録すればフリー利用可能ですがサポートは付きません)。
また、NVIDIA NGCでは提供されないNVIDIA AI Enterprise限定のフレームワークも利用できます。スピーチAI開発用の「Riva」がその一例です(NVIDIA AI Enterpriseの契約がない場合、Rivaは90日間のトライアルのみ利用可)。
すでにアプリケーションが決まっていて、短期に立ち上げたい場合、かつ、サポートを受けたい場合、NVIDIA AI Enterpriseはきわめて有用です。
NVIDIA AI Enterpriseは、NVIDIA DGXシリーズにバンドルされます。DGX以外の他社製GPUサーバーについては、別途サブスクリプション契約が必要です。
なお、2024年3月18日~22日(現地時間)にサンノゼで開催されたNVIDIA最大のイベント「GTC2024」内のKeynoteにおいて、「NVIDIA AI Enterprise 5.0」が発表されました。
NVIDIA AI Enterprise 5.0の目玉は、生成AI推論用のマイクロサービス「NVIDIA NIM」(NVIDIA Inference Microservices)が実装されたことです。NIMを利用することで、Llama2をはじめとしたオープンソースの大規模言語モデル(LLM)を素早く自己ホスト型で動作する環境を構築することができるようになります。
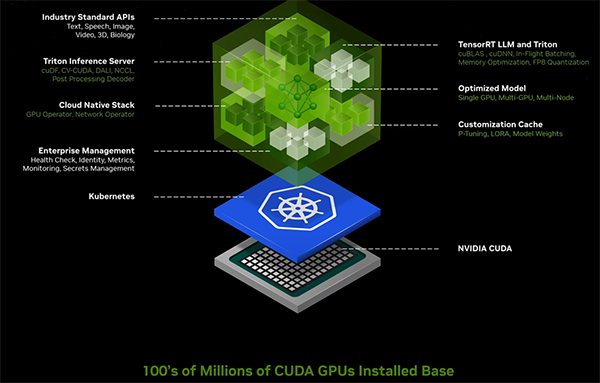
図1. GTC2024で発表されたNVIDIA NIMの概要
今まではRAG(Retrieval-Augmented Generation)※等で、社内の情報を検索してChatGPT等の外部リソースにデータを送信する事で処理を行っていましたが、自己ホスト型では外部に送信する必要が無い為、機密情報を取り扱うことも出来るようになります。
※RAG:LLMの生成能力を向上させる技術。従来のLLMは、膨大なテキストデータを用いて訓練されていたが、それでも不正確な情報や偏見を含む回答を生成してしまう(ハルシネーション)のリスクがあり、自社の情報を生成に使うにはファインチューニングが必要だった。
RAGを用いて、事前に信頼できる外部データソースから関連情報を検索し、生成に利用することで、情報の信頼性を向上させると共に、ファインチューニング無しで自社の情報を扱えるといったメリットを生み出す。
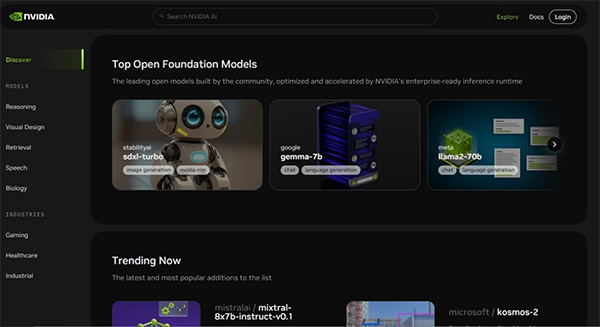
図2. 動作検証済みフレームワークがコンテナ形式で提供されているOpen Foundation Modelsの一例。大規模言語モデルに関しては70B(700億パラメータ)の「Code Llama 70B」などが用意されている。
OSやドライバ、ツール群で構成されるNVIDIA Base Command
NVIDIA Base Commandは、GPUクラスタの稼働および運用管理に必要なツールやドライバの総称です。サードパーティー製品、OSS、NVIDIA提供品などで構成される中で、とくに後述する「NVIDIA Base Command Manager」が重要です。
NVIDIA Base Commandは図2のように五つの階層で表されます。
(1) AI Workflow Management and MLOps
MLOpsとはMachine LearningとOperationsを組み合わせた造語で、開発チームと運用チームとが協調すること、または、その基盤を意味します。このレイヤーには、エコシステムを構成するサードパーティーから提供されるデータセット管理、エクスペリメント管理、モデル管理、リソーススケジューリングなどのツール類が該当します。
(2) Job Scheduling & Orchestration
このレイヤーはOSSのKubernetesとSlurmが該当します。
Kubernetes(K8s)はコンテナ化されたアプリケーションの実行管理を行うツールで、一方のSlurmは並列ジョブの汎用的なスケジューラとしての機能を持っています。機能として似ているところも多いのですが、端的には、GPUアプリケーションをコンテナ上で動かしたい場合はKubernetes、VMを含む一般的なOS環境(いわゆるベアメタル)で動かしたい場合や複数ノードで並列計算を行う場合はSlurmを用いるイメージです。
(3) Cluster Management
NVIDIA Base Commandの中核とも言えるレイヤーで、NVIDIA Base Command Managerと呼ばれるツールがNVIDIAから提供されます。詳しくは後述します。
(4) Network/Storage Acceleration Libraries & Management
GPUのVRAMとストレージをダイレクトに結ぶ「GPUDirect Storage」などのドライバで構成されるレイヤーです。
(5) OS
NVIDIA DGXシリーズに関してはNVIDIAからubuntuベースの「DGX OS」が提供されます。
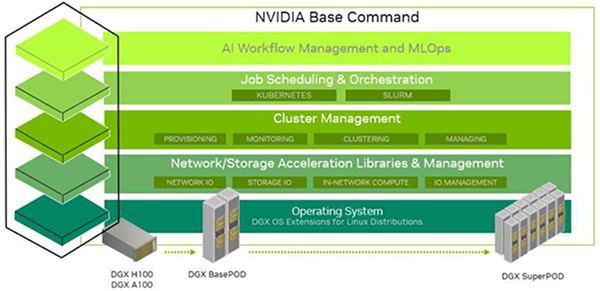
図3. NVIDIA Base Commandの概念図。五つのレイヤーで構成されている。
ポイントになるのが「Cluster Management」と書かれたレイヤーで、
NVIDIA Base Command Managerが提供される。
使い勝手に優れるNVIDIA Base Command Managerを推奨
NVIDIA AI Enterpriseを説明し、次にNVIDIA Base Commandを説明し、ようやく本丸のNVIDIA Base Command Managerにたどり着きました。お待たせしました。
NVIDIA Base Command ManagerはGPUクラスタの運用管理に最適な多機能なツールです。クラスタの構成設定、電源管理、ノードプロビジョニング、ユーザー管理、ワークロード管理、クラスタデバイスモニタリング、ジョブモニタリングなどの機能を備えています。
NVIDIA Base Command Managerは、従来HPCやGPUクラスタの運用管理ツールとして広く使われてきた「Bright Cluster Manager」を前身としています。その開発元であるBright Computing社をNVIDIAが2022年1月に買収したことで、Bright Cluster Managerのver.10からNVIDIA Base Command Managerに名称が変更されました。
冒頭で述べたように、たとえばノードプロビジョニングだけでよければ、AnsibleやKickstartなどのOSSを使えばできますが、その他のノードの死活監視やジョブスケジューリングをするには、複数のOSSを組み合わせる必要があり、画面や使い勝手もそれぞれ異なります。
NVIDIA Base Command Managerなら統一的なユーザーインタフェースにてGPUクラスタの運用管理が可能になり、管理効率を高められます。
GPUノードとは別に用意したLinuxベースのヘッドノードから、OSを含むイメージを各GPUノードに展開してプロビジョニングを行ったり、ワークロードマネージャを通じて負荷やスケジューリングを調整したり、既存ノードのクローンを作ってノードを追加できるなど、深い知識を持たなくてもマルチノードを管理できるように設計されています(図4)。
実際の経験として、12台で構成されたマルチGPUクラスタのプロビジョニングが半日も掛からずに完了したこともあり、とても便利だと感じました。
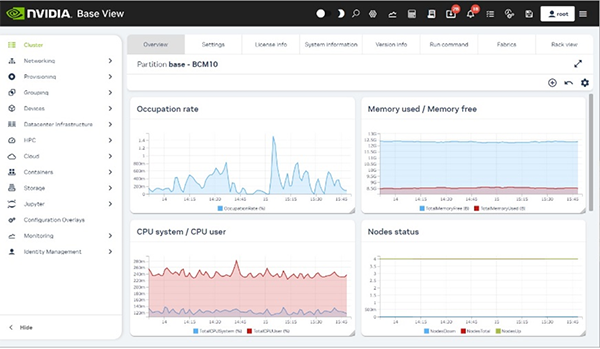
図4. NVIDIA Base Command Managerのダッシュボード画面。
納期や総所有コストを踏まえてハードと運用管理を検討
運用管理の方法やツールは、導入するGPUサーバーのハードウェアも含めて検討する必要があります。
NVIDIA DGXシリーズの場合は、NVIDIA AI EnterpriseとBase Command Managerがハードウェアにバンドルされていますので、追加の契約や費用を考える必要がありません。DGX OSのアップデートに応じてドライバやCUDAなどのバージョンアップも行われるため、プラットフォームレベルの運用管理の効率化が図れます。また、NVIDIA NGCのサポートが受けられるほか、スピーチAI開発用の「Riva」など、NVIDIA AI Enterprise限定のフレームワークも利用できます。
他社製のGPUサーバーは、サーバー構成の変更が可能な利点に加えてハードウェア単体の価格を抑えられる可能性があります。ただし、NVIDIA AI Enterprise(含むNGCのフルサポート)とNVIDIA Base Command Managerはオプションであり、利用するのであればそれぞれのサブスクリプション契約が必要です。
これらを考慮すると、GPUクラスタを構成する場合はBase Command ManagerがバンドルされるNVIDIA DGXシリーズが運用管理の観点で効率的と言えます。一方、マルチノードでの協調動作が不要なシングルノードで構成する場合やOSSのツール群に関するノウハウを持っている場合など、Base Command Managerがとくに必要でないのであれば、コストパフォーマンスに優れる他社製のGPUサーバーでも十分と考えられます。
以上、NVIDIA AI EnterpriseとNVIDIA Base Command Managerについて紹介しました。今回の記事が皆さまのお役に立てると幸いです。(ただしNVIDIAがサービス体系やソリューション名を予告なく変更する場合があります。本稿は2024年3月時点の情報に基づいています。)
NVIDIAソフトウェアライセンスの導入をお考えの方は、NTTPCにご相談ください。