



技術解説
NVIDIA® Llama Nemotron™:推論・指示理解・チャットに強い次世代LLMの全貌
2025.04.21

GPUエンジニア
大野 泰弘

NVIDIAが公開した「Llama-3_1-Nemotron-Ultra-253B-v1」は、単なるLLM(大規模言語モデル)ではありません。推論・指示理解・チャット能力を兼ね備えた次世代エージェントの基盤として設計されたこのモデルは、複数段階にわたる高度な学習フローを通じて構築されました。
本記事では、その裏側にある Distillation・SFT・RLHF・Curriculum RL など、主要ステップの技術的背景を解説します。
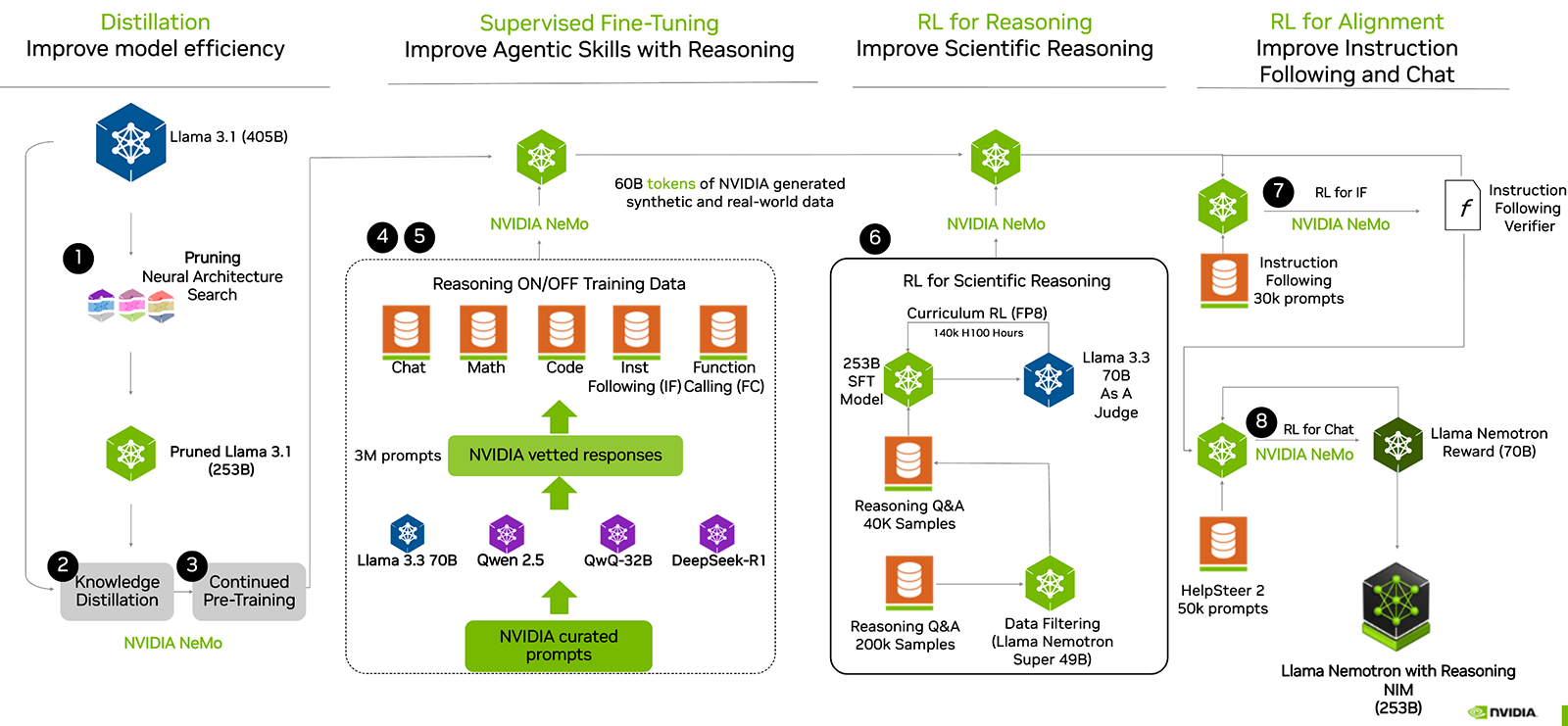
Step 1: Distillation - モデル効率化の肝「蒸留と剪定」
Neural Architecture Search(NAS)とPruning
出発点となるのは、405Bパラメータの巨大モデル「Llama 3.1」。そのままでは現実的な応用が難しいため、まずは Pruning(剪定) を実施。NAS(Neural Architecture Search)を併用し、計算効率と性能のバランスが取れた構造を自動選択します。
- NASとは: 複数のモデル構造候補を自動生成し、最も効果的なものを選定するアルゴリズム。
- 剪定戦略: 重みの大きさや勾配の変化に基づく構造削減により、計算負荷を大幅に削減。
結果として、 Pruned Llama 3.1(253B) を得ることになります。
Knowledge Distillation(知識蒸留)
教師モデル(405B)と生徒モデル(253B)を並列稼働させ、同じ入力に対する出力を比較しながら、教師の暗黙知を生徒に伝える 技法。損失関数としては「KL Divergence」などを使用することが多いです。
Continued Pre-training(継続事前学習)
大量の未学習トークンで再度事前学習。文脈理解力や生成性能の底上げを狙います。
補足: NVIDIA NeMo™フレームワークは、FP8精度対応やモデル並列処理に強く、大規模モデルの学習に最適化されています。
Step 2: Supervised Fine-Tuning(SFT)- 多様なスキルを叩き込む
NVIDIA curated prompts(キュレーション)
Chat / Math / Code / Instruction Following / Function Calling の5領域で、3M件の高品質プロンプト を自動生成・キュレート。
- 応答生成: Llama 3.3 70B / Qwen 2.5 / QwQ-32B / DeepSeek-R1 などの先進モデル群を使って応答を生成
- 応答評価: スコアリングを行い品質をチェックし、「NVIDIA vetted responses」として抽出
教師あり学習(Supervised Fine-Tuning)
選別された高品質ペア(プロンプト+応答)を使って、モデルに一連のスキルを学習させます。ここで学習されるのは下記の項目になります。
- 逐次思考(Chain-of-Thought)
- 関数呼び出しスキル
- 文脈的な指示理解
Step 3: RL for Reasoning - 科学的推論力の獲得
Curriculum RL(段階的強化学習)
FP8精度(TensorRT-LLMやTransformer Engineと親和性が高い)で、140,000 GPU時間(H100) を投じて強化学習を実施。
- SFTモデル(253B) をエージェントとし、 Llama 3.3 70B にて回答の判定を行いフィードバックする(RLAIF的構造)
- まずは40KサンプルのQ&Aでファインチューニングを行い、さらに200Kサンプルへスケール
データフィルタリング
NVIDIA Nemotron Super(49B) モデルでQ&Aをフィルタリングし、回答精度と推論の一貫性を保証。
Step 4: RL for Alignment - ユーザー指示と自然言語応答
RL for Instruction Following(指示理解)
- 30K件のInstruction Followingデータ を使用
- 評価には「Instruction Following Verifier」という独自の自動スコアリング・モデルを使用
RL for Chat(自然な対話)
- HelpSteer 2(50Kプロンプト) を使って、ユーザー好みに応じた応答生成を最適化
- Llama Nemotron Reward(70B) モデルで報酬スコアを算出してフィードバックを行い、より自然な対話が出来るように学習
Nemotron Ultraの完成と特徴
上記全工程を経て誕生したこのモデルは:
- 推論力(Scientific Reasoning)
- 指示追従性(Instruction Following)
- 関数呼び出しやツール利用(Tool-Use)
- 人間らしいチャット能力(Conversationality)
をバランス良く兼ね備えた、次世代型LLMの代表格と言える存在です。
推論と使用方法
- コンテキスト:最大128Kトークンをサート。
- 推論モードの切り替え:システムプロンプトにdetailed thinking onを含めることで、推論モードを有効化。(通常時は非推論モデルとして動作します。)
- 推論環境:
BF16:- 8x NVIDIA H100-80GB (合計640GB)
- 4x NVIDIA B100 (合計768GB)
- 4x NVIDIA H100-80GB (合計320GB)
このモデルは、Hugging Face Transformersライブラリ(バージョン4.48.3推奨)と互換性があり、Linux環境での使用が推奨されています。
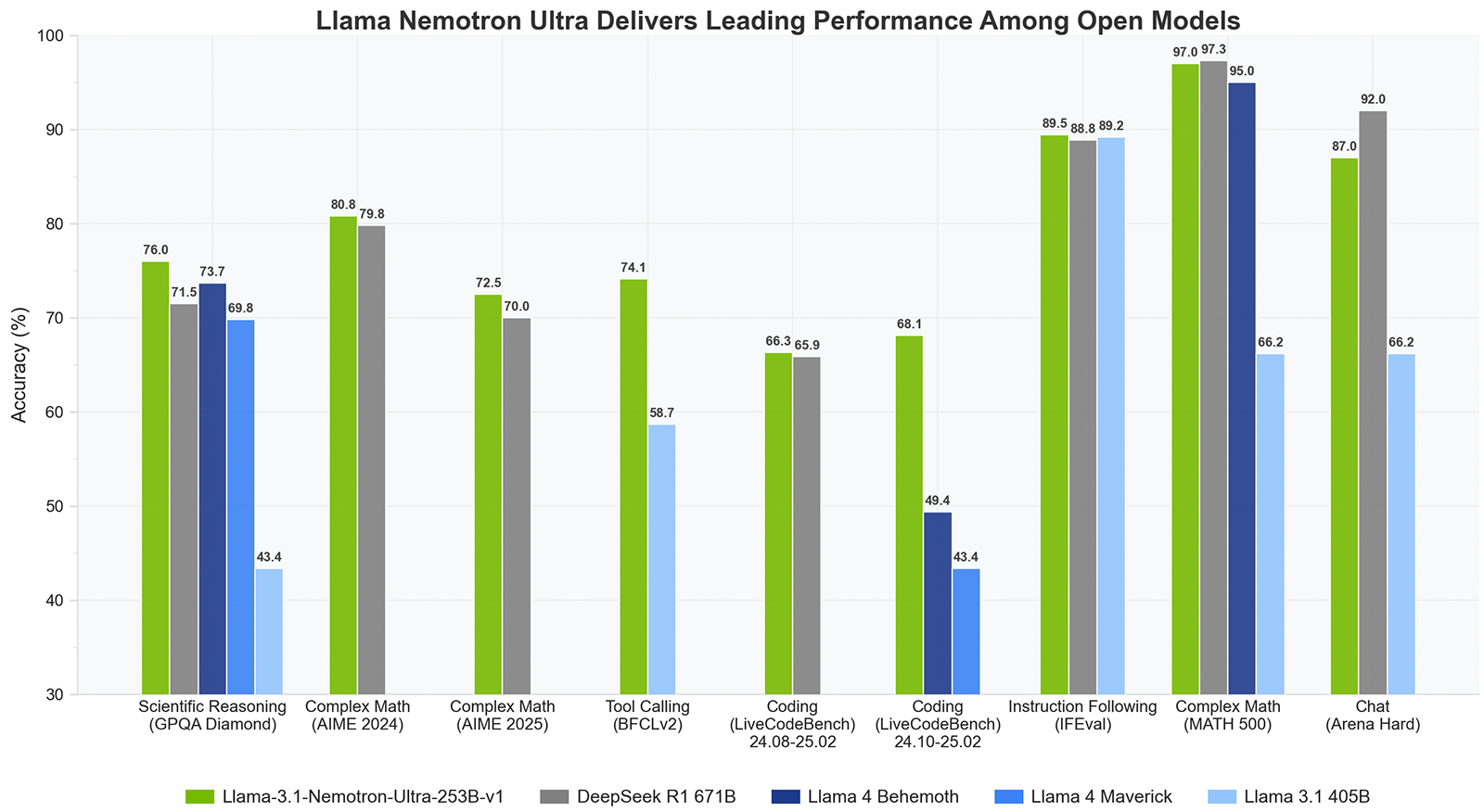
評価結果と性能
このモデルは、以下のベンチマークで高い性能を示しています:
- GPQA:推論モードで76.01%精度。
- AIME25:推論モードで72.50%精度。
- LiveCodeBench:推論モードで66.31%精度。
- MATH500:推論モードで97.00%精度。
ライセンスと商用利用
このモデルは、NVIDIA Open Model LicenseおよびLlama 3.1 Community License Agreementの下で提供されており、商用利用が可能です。ただし、利用に際しては、モデルの整合性、安全性、バイアスなどを考慮し、適切な評価と対策を行うことが推奨されます。
詳細な情報やモデルの使用方法については、以下のリンクをご参照ださい:
技術スタックまとめ
| 技術要素 | 内容 |
|---|---|
| モデル基盤 | Llama 3.1 系列 |
| 実装フレームワーク | NVIDIA NeMo |
| 精度 | FP8(高速・省メモリ) |
| 学習時間 | H100 × 140K時間(推論RL) |
| 評価手法 | AIジャッジモデルによるスコアリング |
| 応答生成 | 多モデルアンサンブル+選別 |