



性能検証
Tesla® V100の性能ベンチマーク
2018.05.31

サービスクリエーション本部
GPUアーキテクト
鈴木 健一

前回のP100に引き続き、今回はNVIDIAの最新GPUアーキテクチャである「Volta™」を実装した「Tesla® V100」の性能を検証、評価してみたいと思います。
NVIDIAによれば、V100はP100と比較して3倍以上高速、と謳っています。
それでは、実際に測定してみましょう。
仕様比較(PCIe)
| コア数 | Mhz | L1cache (MB) |
L2cache (MB) |
FP32 (TFLOPS) |
FP64 (TFLOPS) |
メモリ帯域 (GB / s) |
|
|---|---|---|---|---|---|---|---|
| V100 | 5120 | 1370 | 10MB | 6 | 14 | 7 | 900 |
| P100 | 3584 | 1300 | 1.3MB | 4 | 9.3 | 4.7 | 720 |
ベンチマークソフト
TensorFlowのベンチ を使用し、各モデルのトレーニングにかかる時間を比較します。
用意できたGPUカードのメモリ搭載量が異なるため、同じメモリ量でも違いがないか測定しました。
ベンチマークパラメーター
ResNet-50 ResNet-152 batch_size=32,64 FP16,FP32 Optimizer sgd variable_update: parameter_server InceptionV3 batch_size=32,64 FP16,FP32 Optimizer sgd variable_update: parameter_server VGG16 batch_size=32,64 FP16,FP32 Optimizer sgd variable_update: replicated AlexNet batch_size=32,64 FP16,FP32 Optimizer sgd variable_update: replicated
ベンチマーク機器
ハードウェア
サーバー
SuperServer<SYS-4028GR-TR2>
CPU
Intel® Xeon® CPU E5-2667 v4 ×2
メモリ
256GB
ディスク
Intel® SSD SC2BB960G7
GPU
NVIDIA® Tesla® P100 12GB ×4
NVIDIA® Tesla® V100 16GB ×1
アプリケーション環境
OS: Ubuntu16.04
Driver: 390.30
TensorFlow: 1.8
CUDA: 9.0
cuDNN: 7.0
python: 3.7
メモリ制限
ベンチマークスクリプトへメモリ制限コードを追加し、12GB相当としました。
config = tf.ConfigProto(
gpu_options=tf.GPUOptions(
per_process_gpu_memory_fraction=0.75
)
)
session = tf.Session(config=config)
参考URL:https://www.tensorflow.org/programmers_guide/using_gpu
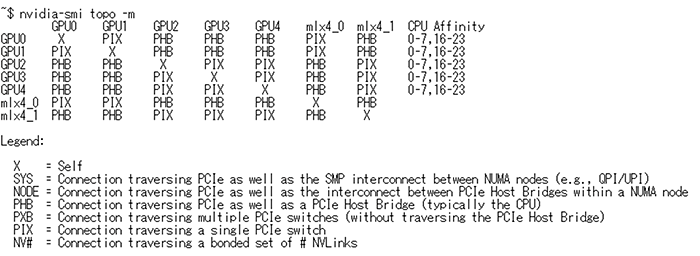
トポロジー情報
すべてのGPUカードを、同じPCIeブリッジ上に配置するように搭載しています。
ベンチマーク実行
ベンチマークコマンドライン:
$ python tf_cnn_benchmarks.py --device=gpu --num_gpus=1 --batch_size=32 --model=resnet50 --variable_update=parameter_server
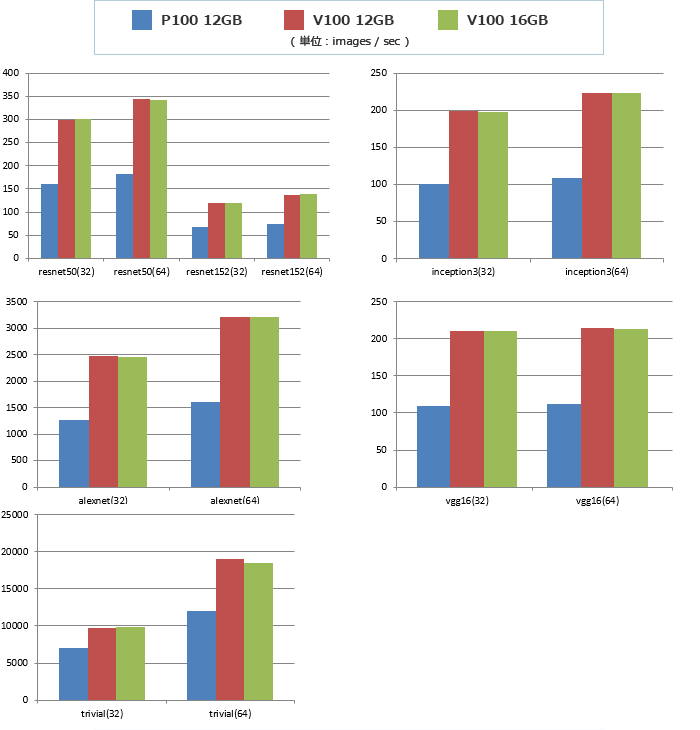
ベンチマーク結果
V100とP100の比較
特に何もしない状態で2倍以上性能向上しています。メモリ制限による変化はありませんでした。
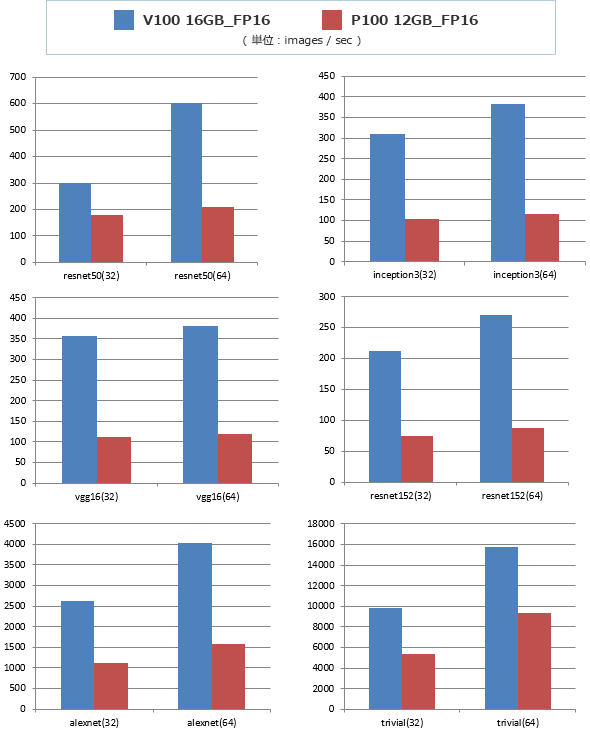
FP16の効果
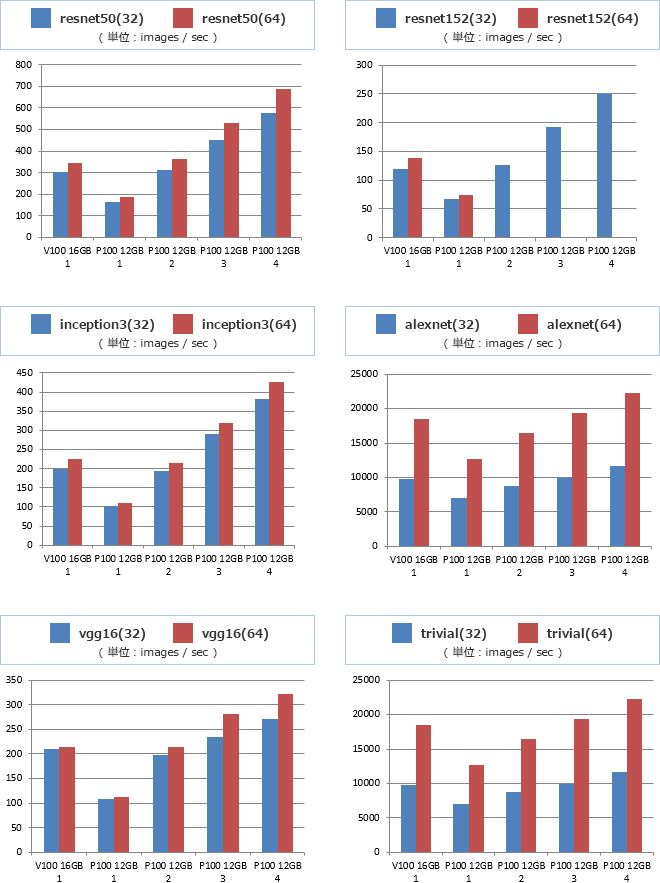
P100をV100相当にするには、P100が2基あればなんとかなりそうです。
今回はここまでとします。
※NVIDIA、Teslaは、アメリカ合衆国およびその他の国におけるNVIDIA Corporation の商標または登録商標です。
※Intel、Xeonは、アメリカ合衆国およびまたはその他の国におけるIntel Corporationの商標または登録商標です。