



性能検証
深層学習オプティマイザの比較評価
2019.01.21

サービスクリエーション本部
ソフトウェアエンジニア
相吉澤 聖明

はじめに
近年、機械学習 / 深層学習が注目されています。クラウドコンピューティングやCPU, GPUなどのハードウェア技術の進化により、実行に必要な膨大な計算力を利用する環境が整ってきました。しかし、それでも依然として学習時間が長いため、高速化に向けたさまざまなオプティマイザ ( 最適化手法 ) が提案されています。
NTT研究所も深層学習オプティマイザの開発を行っており、SDProp※1とAdastandを提案しています。このSDPropとAdastandが従来手法と比べて、どの程度優れているのか調査するため、今回はオプティマイザの比較評価を行った結果を紹介していきます。
深層学習オプティマイザとは
まず、深層学習における学習とは、入力データと学習モデルの層間のパラメータを演算した出力結果が、正解データに近づくようにパラメータを調整することを指します。正解データとの誤差が最小になるようにパラメータを調整していき、収束する ( 誤差の減少がみられなくなる ) まで繰り返します。
オプティマイザは、この学習を高速に、効率よく収束させる方法です。
SDPropとAdastand
NTT研究所は、SDPropとAdastandを提案しています。SDPropはRMSProp※2を、AdastandはAdam※3をもとに開発されたオプティマイザです。どちらの手法も勾配の時系列方向の標準偏差を考慮してパラメータを決定するのが特徴です。過去の更新方向の情報を基に、個別に適した調整幅を自動的に決定します ( 図1※4) 。更新方向のばらつきが大きい場合は、調整幅を小さくして、過剰な振動を抑えます。ばらつきが小さい場合は、調整幅を大きくし、学習を加速させます。
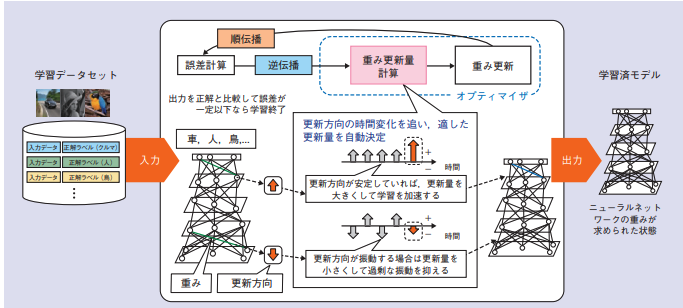
次に、SDProp, Adastand, RMSProp, Adamの更新式を記載しておきます。各パラメータを表1に示します。
表1: パラメータ

SDProp
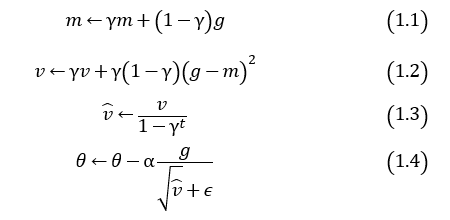
Adastand
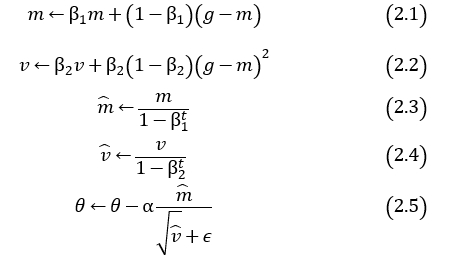
RMSProp
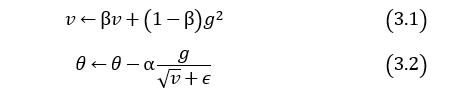
Adam
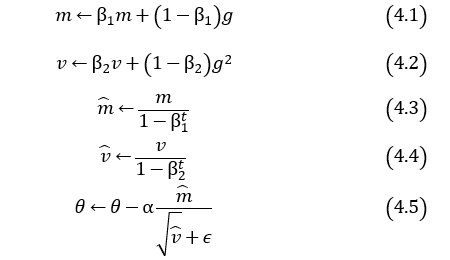
AdastandとAdamの更新式を比較すると、非常によく似ています。どの程度性能に差が現れるのか比較してみましょう。
比較評価
NTT研究所のSDProp, Adastandと、従来のRMSProp, Adamを2つの実験を通して比較してみました。なお、比較項目として次の3項目を用いています。
- 1epochあたりにかかる処理時間
- 一定の精度に達するために必要なepoch数
- 一定のepoch回数、学習を行ったときの精度
また、実験で使用したハイパーパラメータ ( α β1 β2 γ ) は次の値を用いました。
SDProp
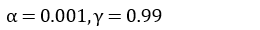
Adastand
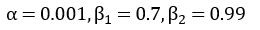
RMSProp
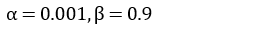
Adam
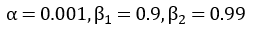
1つ目の実験
この実験では、MNISTのデータセットを用いました。MNISTは、手書き数字画像60,000枚の28px × 28pxのグレースケール画像群です。
使用した学習モデルを、図2に示します。
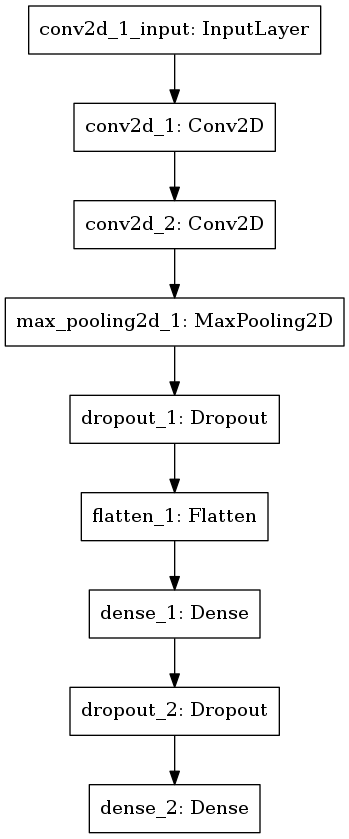
図2: 1つ目の実験で用いた学習モデル
比較結果を表2に、学習曲線を図3に示します。表2の値は、プログラムを10回動かしたときの平均値です。値が取得できなかったものは「―」で表します。
表2: 1つ目の実験結果(平均値
| Adam | Adastand | RMSProp | SDProp | |
|---|---|---|---|---|
| 1epochあたりの処理時間 | 4.17 | 4.28 | 4.11 | 4.05 |
| 20epoch目の精度 | 99.50 | 99.55 | 98.62 | 99.62 |
| 99%に到達するまでに必要なepoch数 | 8.6 | 8.4 | -- | 7 |
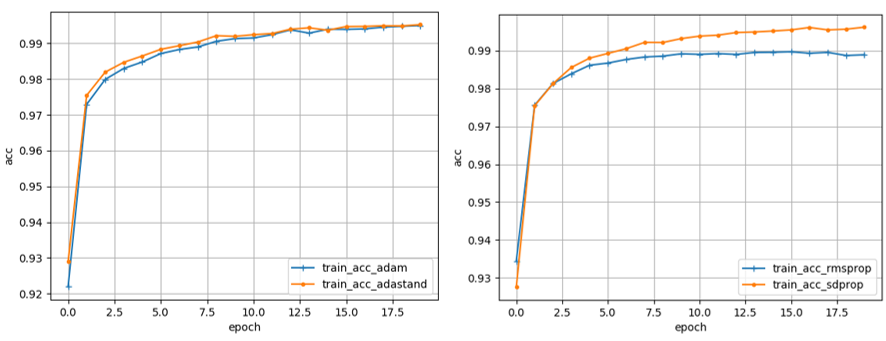
図3: 学習曲線の結果(左:青,Adam 橙,Adastand 右:青,RMSProp 橙, SDProp)
表2と図3をみると、RMSPropは精度が他のオプティマイザより低いことがわかります。また、Adam,Adastand,SDProp間に差はほとんどないように見えます。一応、ANOVA ( 分散分析 ) を用いて検定してみました。
まず、1つ目の比較項目である1epochあたりにかかる処理時間を比較してみると ( F(3,27) = 0.344, p > 0.05 ) となり有意差はありません。
次に、99%に達するまでに必要なepoch数を比較してみると ( F(3,27) = 1990,4, p < 0.05 )となり有意差がありました。Holm-Bonferroni法による事後比較の結果、SDProp < Adam, Adastand < RMSPropとなり、SDPropが最も少ないepoch数で高精度に達しました。この項目でもAdamとAdastand間に有意差はありません。
最後に、20epoch目の精度を比較してみると ( F(3,27) = 1388.9, p < 0.05 ) となり有意差がありました。先ほどと同様に、事後比較をしてみると、RMSProp < Adam, Adastand < SDPropとなり、SDPropが最も高い精度でした。
この実験では、従来のオプティマイザ ( RMSProp, Adam ) よりNTT研究所のオプティマイザ ( SDProp, Adastand ) を用いたほうが良い結果が得られました。しかし、表2をみるとあまり恩恵を感じることができませんね。
2つ目の実験
2つ目の実験で用いたデータは「ディープラーニングで“道路のひび割れ”を検知する」※5で用いられているものです。32px × 32pxのカラー画像で、学習データ数は38400です。
使用した学習モデルを図4に示します。
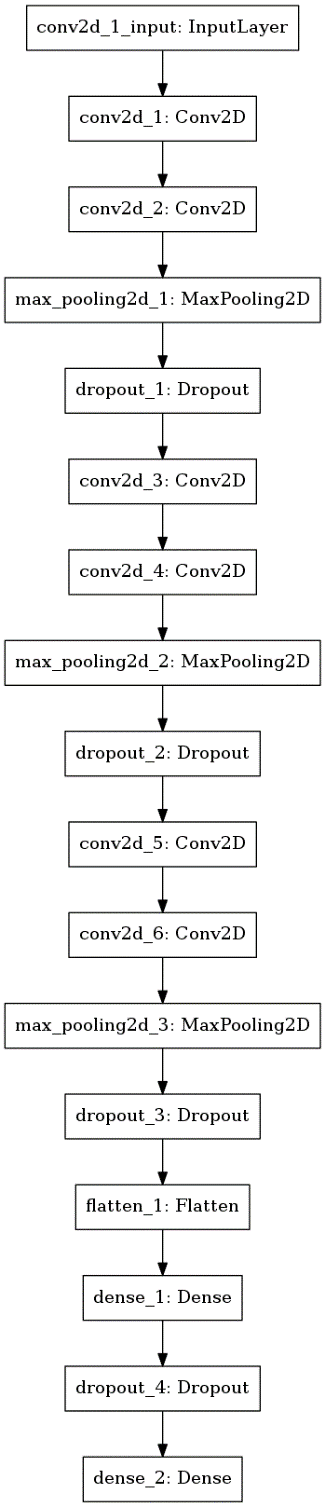
図4: 2つ目の実験で用いた学習モデル
比較結果を表3に示します。値は、プログラムを10回動かしたときの平均値です。学習曲線を図5に示します。
表3: 2つ目の実験の結果(平均値)
| Adam | Adastand | RMSProp | SDProp | |
|---|---|---|---|---|
| 1epochあたりの処理時間 | 15.8 | 16.0 | -- | 14.4 |
| 30epoch目の精度 | 85.6 | 87.5 | -- | 81.5 |
| 85%に到達するまでに必要なepoch数 | 23.4 | 10.2 | -- | -- |
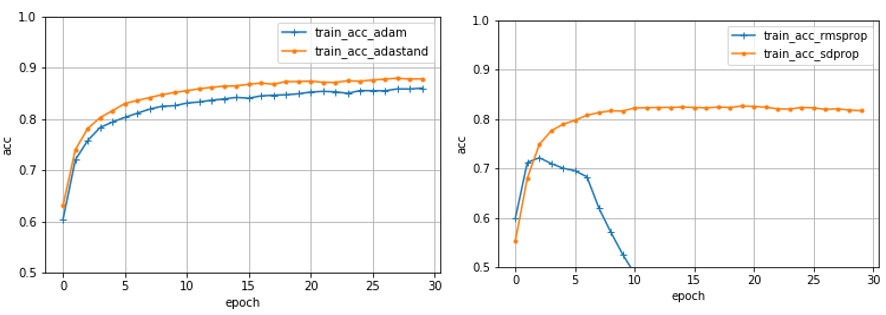
図5: 学習曲線の結果(左:青,Adam 橙,Adastand 右:青,RMSProp 橙, SDProp)
表3と図5をみると、1つ目の実験と比べてオプティマイザ間に差が顕著に現れていることが確認できます。また、RMSPropは図5のとおり、発散したため、この実験では取り除いて考えました。この結果も、ANOVAを用いて検定してみました。
まず、1つ目の比較項目である1epochあたりにかかる処理時間を比較してみると ( F(2,27) = 22.46, p < 0.05 ) となり有意差がありました。事後比較の結果、SDProp < Adam, Adastandとなり、SDPropが1epochあたりの処理時間が最も短くなりました。1つ目の実験に続き、SDPropが良い結果でした。
次に、85%に達するまでに必要なepoch数を比較してみると ( F(2,18) = 370.2, p < 0.05 )となり有意差がありました。事後比較の結果、Adastand < Adam < SDPropとなり、Adastandが最も少ないepoch数で高精度に達しました。先程まで、AdamとAdastand間に差がありませんでしたが、この項目では、AdastandはAdamの半分以下のepoch数で高精度に達します。一方で、これまで良い結果を示していたSDPropが最も悪い結果となりました。
最後に、30epoch目の精度を比較してみると ( F(2,18) = 1180.6, p < 0.05 ) となり有意差がありました。事後比較の結果、SDProp < Adam < Adastandとなり、Adastandが最も高い精度でした。SDPropは、この項目でも最も悪い結果となりました。
2つ目の実験では、1つ目の実験とはうってかわりAdastandが良い結果でした。また、SDPropは1epochあたりの処理時間は短いですが、精度がAdamよりも悪くなりました。
実験結果
SDProp
1つ目の実験では、最も良い結果を示していましたが、あまり恩恵を感じられない程度の性能差でした。また、2つ目の実験では従来手法のAdamよりも悪い結果でした。 2つの実験をみるとSDPropを用いるよりは、従来手法のAdamのほうが良さそうです。( RMSPropよりは、SDPropのほうが良さそうですが )
Adastand
1つ目の実験では、Adamと同程度の性能であり、RMSPropよりも良い結果でした。2つ目の実験では、Adamよりも精度も高く、またAdamより少ないepoch数で高精度に達しました。
2つの実験をみると、Adamの代わりにAdastandを用いたほうが少ないepoch数で高精度に達するので良さそうですね。
考察
2つ目の実験は1つ目の実験よりも、画像サイズやチャネル数、学習モデルの層数が多いものを用いました。画像データと学習モデルどちらの違いに起因しているかわかりませんが、学習処理が増加するに連れAdamよりAdastandを用いたほうが良い結果を出すことができるのではないかと考えます。
まとめ
今回は、2つの実験を通して、NTT研究所が開発した深層学習オプティマイザと従来のオプティマイザの性能を比較してみました。
SDPropはMNISTのような簡易的なデータに対して有用でしたが、実際のプロジェクトで使われるようなデータに対してはあまり良い結果がでませんでした。
Adastandは、従来のオプティマイザより悪い結果になることはなく、むしろ高い精度を保ちつつ、かつ学習時間を短縮できることがわかりました。
参考文献
※1 Yasutoshi Ida, Yasuhiro Fujiwara and Sotetsu Iwamura: Adaptive Learning Rate via Covariance Matrix Based Preconditioning for Deep Neural Networks. Proc. IJCAI-17, 1923-1929
DOI: https://www.ijcai.org/proceedings/2017/267
※2 Tijmen Tieleman and Geoffrey Hinton. Lecture 6.5-rmsprop: Divide the Gradient by a Running Average of its Recent Magnitude. COURSERA: Neural Networks for Machine Learning, 2012
※3 Diederik Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. International Conference in Learning Representations (ICLR), 2015
※4 NTTソフトウェアイノベーションセンタ「深層学習のための先進的な学習技術」<http://www.ntt.co.jp/journal/1806/files/JN20180630.pdf>
※5 石井 誉仁 「ディープラーニングで“道路のひび割れ”を検知する」<https://www.nttpc.co.jp/gpu/article/technical05.html>