



トレンド
NVIDIA DGX Sparkで変わるAI推論環境 ~特長から他モデルとの比較まで徹底解説~
2025.07.18

GPUエンジニア
AIモデルの複雑化と大規模化が加速する現代において、より身近で高性能なAI推論環境へのニーズはかつてないほど高まっています。これまで、ハイスペックなGPUサーバーをローカルで利用するには、大規模な投資や設備が必要でしたが、個々の開発者や小規模チームがGPU推論パワーを手にするための新たな道が拓かれようとしています。
NVIDIAは2025年春のイベント(GTC2025)で、長らく「Project DIGITS」として注目されてきたNVIDIA DGX™ Spark(以下、DGX Spark)を正式に発表しました。これは、コンパクトなデスクトップサイズでありながら、本格的なAI推論性能を発揮する、まさにパーソナルなAIスーパーコンピューターといえる製品です。
本記事では、このDGX Sparkについて、主な特長、搭載されているNVIDIA GB10 Grace Blackwell Superchip(以下、NVIDIA GB10 Superchip)の紹介、NVIDIA DGX Systemsにおける位置づけと他の主要システムとの比較まで、わかりやすく解説します。
【目次】
1. NVIDIA DGX Sparkとは
DGX Sparkは、NVIDIAが提供するAI開発向けのコンパクトなGPUワークステーションです。ワークステーションとは、高度な計算処理やグラフィックス処理に特化した業務用PCのことで、AI開発やシミュレーション、設計業務などに利用されます。
DGX Sparkは、NVIDIAの最新アーキテクチャに基づいた高性能GPUやAI開発に適したソフトウェアに対応しており、AIモデルの設計からトレーニング、推論までを1台で完結できるのが大きな特色です。
非常に小型の筐体(縦150mm × 横150mm × 高さ50.5mm)に高性能なコンピューティング機能を凝縮しており、NVIDIAはこの製品を「デスク上のAIスーパーコンピューター」と銘打っています。

2. NVIDIA DGX Sparkの主な特長
「デスクにおけるAIスーパーコンピューター」であるDGX Sparkは、AI開発の現場にどのようなメリットをもたらすのでしょうか。
ここでは、DGX Sparkの特長を見ていきましょう。
2.1 デスクトップにおけるAIコンピューティングを実現
DGX Sparkは、オフィスやラボ環境のデスク上に設置可能なAI開発プラットフォームとして設計されています。
コンパクトな設計
縦150mm × 横150mm × 高さ50.5mm の小型筐体で、重量は約1.2kg。省スペース性と可搬性に配慮しています。
大規模モデルに対応
小型ワークステーションでありながら、ローカル環境において最大200B(2,000億)パラメータのAIモデルのプロトタイピング、ファインチューニング、推論が可能。大型サーバーと遜色ない性能を発揮します。
セキュアなローカル開発環境
機密性の高いデータをクラウドにアップロードすることなく、ローカル環境でセキュアに開発を推進できます。
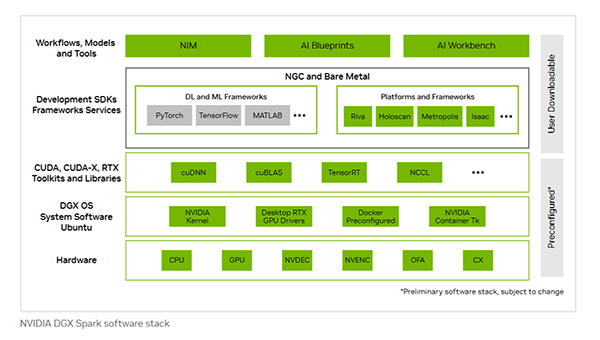
2.2 NVIDIA AIソフトウェアエコシステムへのスムーズなアクセス
DGX Sparkには、AI開発に必要なソフトウェア環境(NVIDIA DGX OS with Ubuntu Linuxベース)がプリインストールまたは提供されており、迅速な開発着手を支援します。
※Enterprise サポート込みでソフトウェアを利用する場合は、別途有償ライセンスの購入が必要です。
開発支援ツール
NVIDIA AI Enterprise(NVIDIA NIM™マイクロサービス含む)、NVIDIA AI Workbench
主要フレームワーク
PyTorch、TensorFlow等
高速AIライブラリ
cuDNN、TensorRT、NCCL等
目的別プラットフォーム例
Riva(音声AI)、Holoscan(ヘルスケア・エッジAI)等
2.3 高速なネットワーク接続と拡張性
DGX Sparkは、NVIDIA ConnectX™-7 SmartNICを搭載しており、高速なネットワーク接続が可能です。
さらに、複数台のDGX Sparkをネットワークで接続することで、より大規模な構成にも対応できます。たとえば、2台のDGX Sparkを組み合わせることで、最大405Bパラメータの大規模言語モデル(例:Llama 3.1 405B)にも対応した推論処理が可能となります。
このように、デスクトップサイズでありながら、クラスタ構成によるスケーラビリティも兼ね備えているのがDGX Sparkの大きな強みです。
3. NVIDIA DGX Sparkのプロセッサー:NVIDIA GB10 Superchip
DGX Sparkの「デスクにおけるAIスーパーコンピューター」というコンセプトの実現において、中核的な役割を果たしているのが、「NVIDIA GB10 Superchip」です。
このSuperchipは、GPUとCPUを同一ユニットに統合し、AI開発および推論処理に最適化された革新的なプロセッサー(情報を処理して計算する中枢装置)です。コンパクトな筐体からは想像を超える処理性能を実現し、従来のワークステーションでは不可能だった高度なAI処理をデスクトップ環境で可能にしています。
3.1 NVIDIA GB10 Superchipの主な仕様と特徴
では、このGB10 Superchipの備える構成要素や、どのようにして高性能なAI処理基盤を実現しているのか、その主な仕様をまとめました。
【NVIDIA GB10 Superchipの主な仕様】
GPU
NVIDIA Blackwellアーキテクチャ(第5世代Tensorコア搭載・FP4高速演算対応/最大1PFLOPS@FP4)
CPU
NVIDIA Graceアーキテクチャ(20 core Arm 、10 Cortex-X925 + 10 Cortex-A725 Arm)
メモリ
128 GB のコヒーレント統合システムメモリ
インターコネクト
NVLink™-C2C(CPU-GPU間接続、PCIe Gen5の約5倍の帯域幅)

それぞれの仕様について、以下に詳しく解説していきます。
GPU:NVIDIA Blackwellアーキテクチャ
NVIDIA Blackwellアーキテクチャを採用したGPUは、AI処理の高速化と効率化に注力して設計されています。
第5世代TensorコアとFP4(低精度・高速演算フォーマット)に対応し、最大1,000 TOPSのAI処理性能(FP4利用時)を実現します。
Blackwellアーキテクチャの詳細については、以下の記事もご参照ください。
【関連記事】
▶︎生成AIのパフォーマンスが大幅アップ!?NVIDIA BlackwellアーキテクチャGPUの性能
CPU:NVIDIA Graceアーキテクチャ
NVIDIA Graceは、Armアーキテクチャに基づく20コア構成のCPUで、NVIDIAがAIワークロード向けに設計した高性能プロセッサーです。Armベースの設計で、高い電力効率を維持しながら、AI・HPC向け処理に求められる性能をバランスよく実現しています。
内部構成は、高性能なCortex-X925コアと高効率なCortex-A725コアをそれぞれ10基ずつ組み合わせたヘテロジニアス構成を採用しており、データの前処理やオーケストレーション、モデルチューニング、リアルタイム推論などの処理を効率的にこなすことが可能です。
メモリ:128GBのコヒーレント統合システムメモリ
CPUとGPUが128GBのメモリ空間を共有する「コヒーレントメモリ」を採用しています。これにより、データコピーのオーバーヘッドが削減され、AI処理全体の効率向上に貢献します。
インターコネクト:NVLink™-C2C
AI処理においては、GPUとCPU間の継続的なデータ連携が重要です。
GB10 Superchipでは、NVLink™-C2C(Chip-to-Chip)インターコネクト技術を採用することで、CPUとGPU間の広帯域データ転送を実現しており、これはPCIe Gen5と比較して約5倍の帯域幅に相当します。
各仕様の説明については以下の関連記事もご参照ください。
【関連記事】
▶︎データセンターGPU性能比較:指標別に見る製品の選定ポイント
4. NVIDIA DGX Sparkの位置づけ:他のNVIDIA DGX Systemsとの比較
これまで紹介してきたように、DGX Sparkは、オフィスやラボといった限られたスペースでも利用可能な、革新的なAI開発ワークステーションです。
さらにNVIDIAは、大規模なAI学習や推論にも対応するため、さまざまなラインナップの「NVIDIA DGX™ Systems」を展開しています。DGX Sparkはそのうちの1型番です。
「DGX™ Systems」とは、NVIDIAが提供する高性能AIコンピューティング環境の総称であり、パーソナルなデスクトップ用途からラックスケールの大規模インフラまで、幅広いニーズに応えるラインナップが用意されています。
ここでは、そうしたNVIDIA DGX™ Systemsの中で「DGX Spark」がどのような位置にあるのか、そして同じBlackwell世代の代表的なシステムとの違いについて解説します。
4.1 各モデルの特性
NVIDIA DGX™ Systemsにおける主要なBlackwell世代モデルの特性は以下の通りです。
| モデル名 | 主なカテゴリ | Blackwell搭載構成 | 用途例 |
|---|---|---|---|
| NVIDIA DGX™ Spark | ワークステーション | NVIDIA GB10 Superchip | 小スペース/小規模・プロトタイプ |
| NVIDIA DGX™ B200 | サーバー | NVIDIA B200 GPU ×8 | データセンター向けAI/HPC/LLM |
| NVIDIA DGX™ B300 | サーバー | NVIDIA Blackwell Ultra GPU | データセンター向け大規模AI/HPC/LLM |
| NVIDIA GB200 NVL2 | サーバー | NVIDIA Blackwell GPU ×2 | 小型省スペースラックマウント |
| NVIDIA GB200 NVL72 | ラック | NVIDIA Blackwell GPU ×72 | 超大規模AI・生成AI/LLM開発 |
| NVIDIA GB300 NVL72 | ラック | NVIDIA Blackwell Ultra GPU ×72 | Blackwell世代最上位 |
各モデルの詳細はNVIDIA DGX™ Systems製品紹介ページをご覧ください。
このように、NVIDIA DGX™ Systemsは、個人のデスクトップ環境からデータセンター規模のAIスーパーコンピューティングまで、幅広いニーズに対応する製品群で構成されています。
その中でもDGX Sparkは、最も手軽に導入できるAI開発環境として位置づけられており、個人の研究開発やPoC、スモールチームでの実験環境など、軽量かつ柔軟な活用に適しています。
5. NVIDIA DGX Sparkのユースケース
では、DGX Sparkは実際にどのようなシーンで活用されるのでしょうか。
小規模な開発から、より本格的なAI運用へとつなげる中でのユースケースの具体例を以下にまとめました。
個人開発者、AI研究者、学生によるAIモデルの実験・開発
ノートPCやローエンドGPU搭載ワークステーションでは処理能力が不足するようなAIモデルの試作や評価も、DGX Sparkを用いることでローカル環境での高速な開発・検証が可能となります。個人やアカデミック用途でも、ハイエンドなAI研究を身近に行う環境を構築できます。
企業における小規模AI開発チームやPoCプロジェクト
クラウドを利用できない機密性の高いデータを扱う場合でも、DGX Sparkを活用すれば、社内環境で安全に処理しながら、迅速にプロトタイプ開発を進めることが可能です。PoC段階におけるスピーディな検証と意思決定を支援します。
大規模AIクラスタを補完する、ローカルでの軽量な検証・開発環境
DGX Sparkを活用することで、データセンター側のリソースに負荷をかけることなく、前処理やハイパーパラメータの調整といった工程をローカルで効率的に実行できます。これにより、全体の開発フローを分散・最適化し、実験回転率を向上させることが可能です。
このように、DGX Sparkは、大規模クラスタを前提としない開発環境において、初期導入のハードルを大きく下げながら、実用的なAIモデル開発に必要な性能と柔軟性を提供します。
6. まとめ
本記事では、NVIDIA DGX Sparkについて、その概要から中核を担うNVIDIA GB10 Superchipの特長、NVIDIA DGX™ Systemsにおける位置づけ、具体的なユースケースに至るまで、幅広く解説してきました。
Grace Blackwellアーキテクチャを採用したNVIDIA GB10 Superchipを搭載し、卓上にも収まるコンパクトな筐体設計により、これまで大規模なサーバー設備が必要だったAIモデルのプロトタイピングやファインチューニング・推論をデスクサイドで実行できる現実味が一気に高まっています。
この革新的なAI開発プラットフォームは、開発者や研究者が最先端のAI技術へアクセスする障壁を下げ、AIを活用した研究・開発や新たなサービス創出の加速を力強く後押しする存在となるでしょう。
NTTPCはお客様のGPU導入をサポートしています。導入をご検討の際は、ぜひNTTPCにご相談ください。お客様のご要件に応じた最適なGPUソリューションをご提案いたします。
※記載された情報は、リリース時点のものです。商品・サービスの内容などの情報は予告なしに変更されることがあります。