



性能検証
Infnibandを用いたGPU環境検証
2019.04.23

サービスクリエーション本部
アプリケーションエンジニア
石井 誉仁

はじめに
InfinibandとはEthernetと同様のサーバー間を繋ぐオープンスタンダードなインターコネクトで、サーバー間IOを高速で通信することを可能にします。また、高速通信の他にも低レイテンシーや高い保守性などといった特徴を持っており、DeepLearningの領域ではGPU環境としてサーバー間 のIOにおけるスループット向上のためにInfinibandが用いられています。
そこで今回はInfinibandと複数のサーバーを用いてマルチGPU環境を構築し、DeepLearningにおける学習モデルを生成する際に Infinibandを利用した場合のスループット(学習速度)をEthernetやGPUの組み合わせと比較して検証を行います。
前提条件
検証を実施するにあたり今回は次の機器を用いて構成図のようにマルチGPU環境を用意しました。
- サーバー 2台
- ネットワークスイッチ(Switch) 1台
- GPUカード(GPU) 4枚
- Infiniband Switch(IBSW) 2台
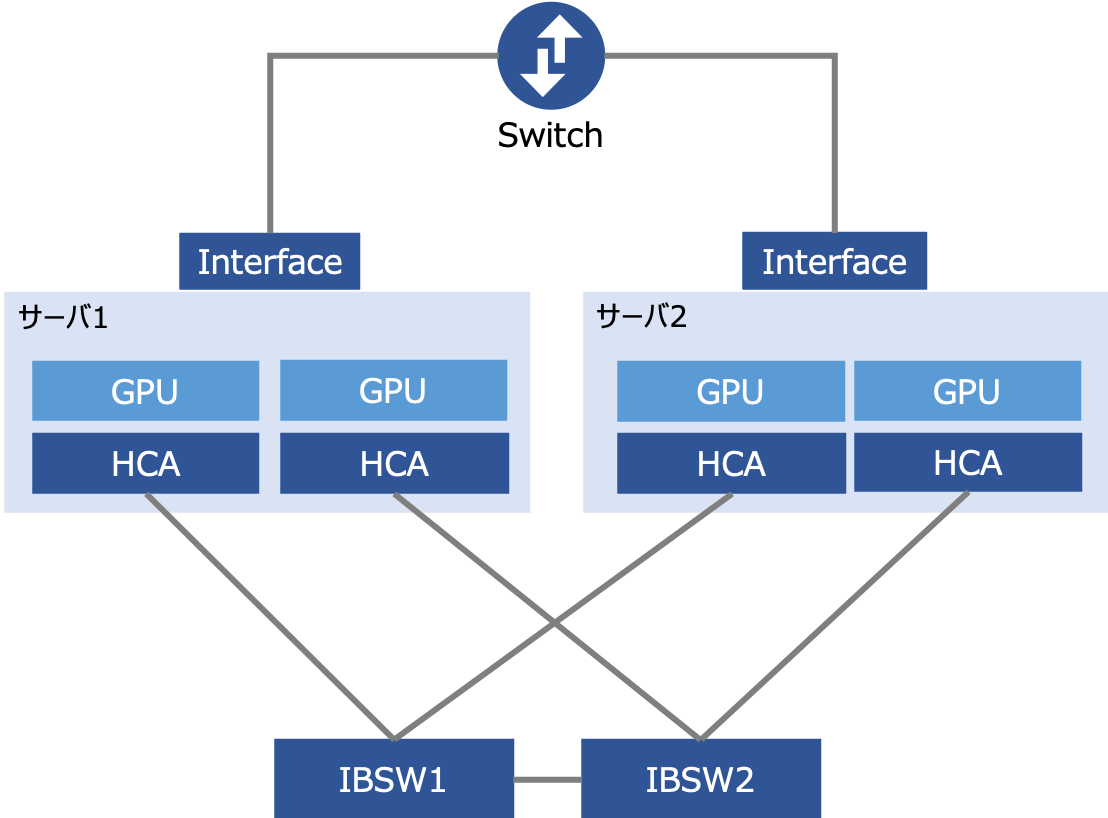
利用するInfiniband Switchは各サーバーのGPUカードの2枚中1枚のGPUカードと対になっており、Infinibandを介した通信は最大で2GPUが利用可能な構成となっています。また、ネットワークカードを介した通信は10GbEを利用しており、最大で4GPUが同時に利用できるようになっています。また、次のとおり各種ハードウェアのスペックを表にまとめました。
| カテゴリ | 仕様 | 数量 |
|---|---|---|
| サーバー | SuperMicro | - |
| CPU | Xeon E5-2667 v4 | 2 |
| メモリ | 32GB(DDR4-2400) | 8 |
| SSD | 960GB | 1 |
| 拡張LANカード | 10GbE Standard Adapter with RJ45 | 1 |
| 拡張カード | Mellanox 56Gb/s FDR IB and 40GbE QSFP | 2 |
| GPUカード | Tesla P100 PCIe(16GB) | 2 |
各種ソフトウェア仕様
以前のブログにもありました「Infinibandの性能ベンチマーク ~GPU Direct™を実行してみる~」 と同様にサーバー間でInfinibandによる並列処理のためのメッセージ通信を実施するMPIという規格を利用して並列実行環境を構築します。そして、今回はそのMPIの機能を提供しているOpenMPIというライブラリを利用します。また、インストールや設定に関しては本題からずれるので今回は割愛します。次のとおり、検証で利用したソフトウェアスペックを記載します。
| 項目 | バージョン |
|---|---|
| CUDA | 10 |
| cuDNN | 7.5.0 |
| OpenMPI | 2.1.1 |
| Python | 3.5.4 |
| chainer | 5.2.0 |
| CuPy | 5.2.0 |
データ並列とモデル並列
DeepLearningの学習では複数のサーバーや複数プロセスといった並列処理を実現する分散学習がよく話題として挙がります。そして、分散学習において一般的にデータ並列とモデル並列といったアプローチがよく知られています。データ並列では、全プロセスに同じモデルをコピーして訓練することでバッチサイズをプロセス数倍し、学習を高速化させる手法です。一方でモデル並列とは、1つのモデルを分割して複数のプロセスに配置し、全プロセスで協調して1つのモデルを訓練する手法です。今回はChainerとChainerMNを利用して、データ並列での学習を実施していきます。モデル並列はGPUのメモリに乗り切らないような学習を行う際に利用されていたアプローチで、最近ではGPUで扱えるメモリが増加してきたことから、データ並列を利用することが多いこととモデル並列では速度面での課題があるためデータ並列を選択しています。
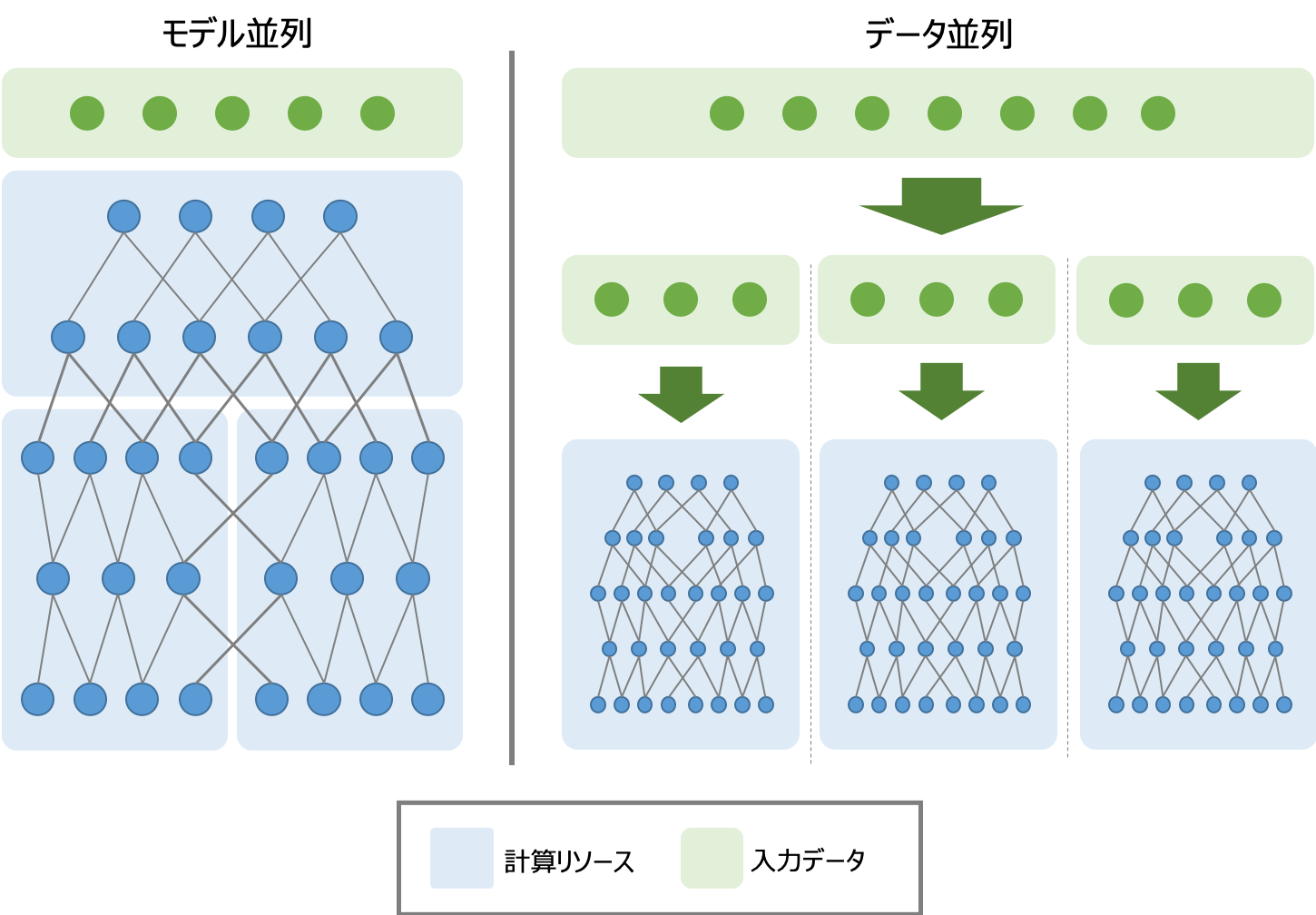
次にデータ並列の学習プロセスについて説明します。はじめに、基本的な学習プロセスは入力データをネットワークに与えて得られた出力結果から誤差関数を算出し、逆伝播によって重みの各パラメーターに対する勾配を計算します。そして、最適化手法に従って重みを最適な値へと更新していきます。 データ並列の場合は各プロセスが同一のモデルを保有し、異なるデータを入力してプロセスを並列化することでスループットを向上させるため、入力されるデータが異なると得られる出力結果も異なります。そこでChainerMNによるデータ並列では「All-Reduce」というアルゴリズムを用いて勾配を求めた後、プロセス間で勾配の平均を求め、求めた平均を全体で得られた勾配とみなし、モデルに適用を行います。これによって各プロセスで共通のモデルを 維持して学習を実現しています。
ここで発生してくる問題は分散学習が単一のノードで学習する場合と比較して良いのかという点です。分散学習における難しさの1つにスループットの向上が常に学習効率の向上になるわけではないという点にあります。例えばイテレーション数が減るためモデルが成熟する前に学習が終わってしまう問題や勾配の平均を取ることでデータ全体での分散が小さくなり、学習が効率的に進まないといった現象もあります。つまり、分散学習を活用すればスループットを向上させられるために学習効率が向上するという考え方は間違っており、適切な問題に適切なパラメーターを当てはめることが重要となります。
検証内容
今回は機械学習でよく利用される数字画像認識のMNISTと一般画像分類を実施するCIFAR10のスループットをサーバー台数やGPUカード、Infinibandの利用有無などの組み合わせを変えて計測して比較します。 MNISTとCIFAR10についての解説やデータセットのダウンロードは次のリンクに記載しております。参考にしてください。
| 検証項目 | サーバー台数 | Infiniband利用 | 利用GPUカード |
|---|---|---|---|
| 1 | 1台 | なし | 1枚 |
| 2 | 1台 | なし | 2枚 |
| 3 | 2台 | なし | 2枚 |
| 4 | 2台 | あり | 2枚 |
検証結果
本章では検証した結果について説明します。検証におけるOpenMPIの実行についてはmpirunコマンドを利用して検証を実行しました。また、Infinibandを介したトラフィックを利用するために、IPoIBによるネットワークを構成して次のコマンドオプションを利用しました。それでは2つの検証結果を次節から見ていきましょう。
$ mpirun -mca btl openib,self -n 2 -hostfile<host><command>
MNIST
MNISTの検証内容では次の条件を統一して学習を行いました。
- ユニット数: 1000
- ミニバッチサイズ: 100
- エポック数: 20
検証項目ごとのスループットと精度の結果は次の表のようになりました。結果から分かるようにスループットはあまり大きな差が見られませんでした。これはエポック数が少ないかつ、MNISTのデータセットが小さいために学習コストがそれほど大きくないことに起因するものであると考えられます。精度(accuracy)に着目してみると、1GPUでの学習よりもGPUカードを複数枚利用した並列プロセスを実施した場合の方が学習精度が落ちていると言えます。これはChainerMNの仕組みであるAll-Reduceの処理による各プロセスの勾配を平均したことによるものである可能性が 高いです。勾配を平均することで実測値とは異なるために、平均によって生じた誤差によって全体の精度が落ちていると考えられます。
| 項目 | ノード数 | GPU数 | 通信 | スループット(s) | accuracy |
|---|---|---|---|---|---|
| 1 | 1 | 1 | - | 52.4744 | 0.9834 |
| 2 | 1 | 2 | - | 40.9686 | 0.9799 |
| 3 | 2 | 2 | Ethernet | 41.5959 | 0.9813 |
| 4 | 2 | 2 | Infiniband | 41.8352 | 0.9829 |
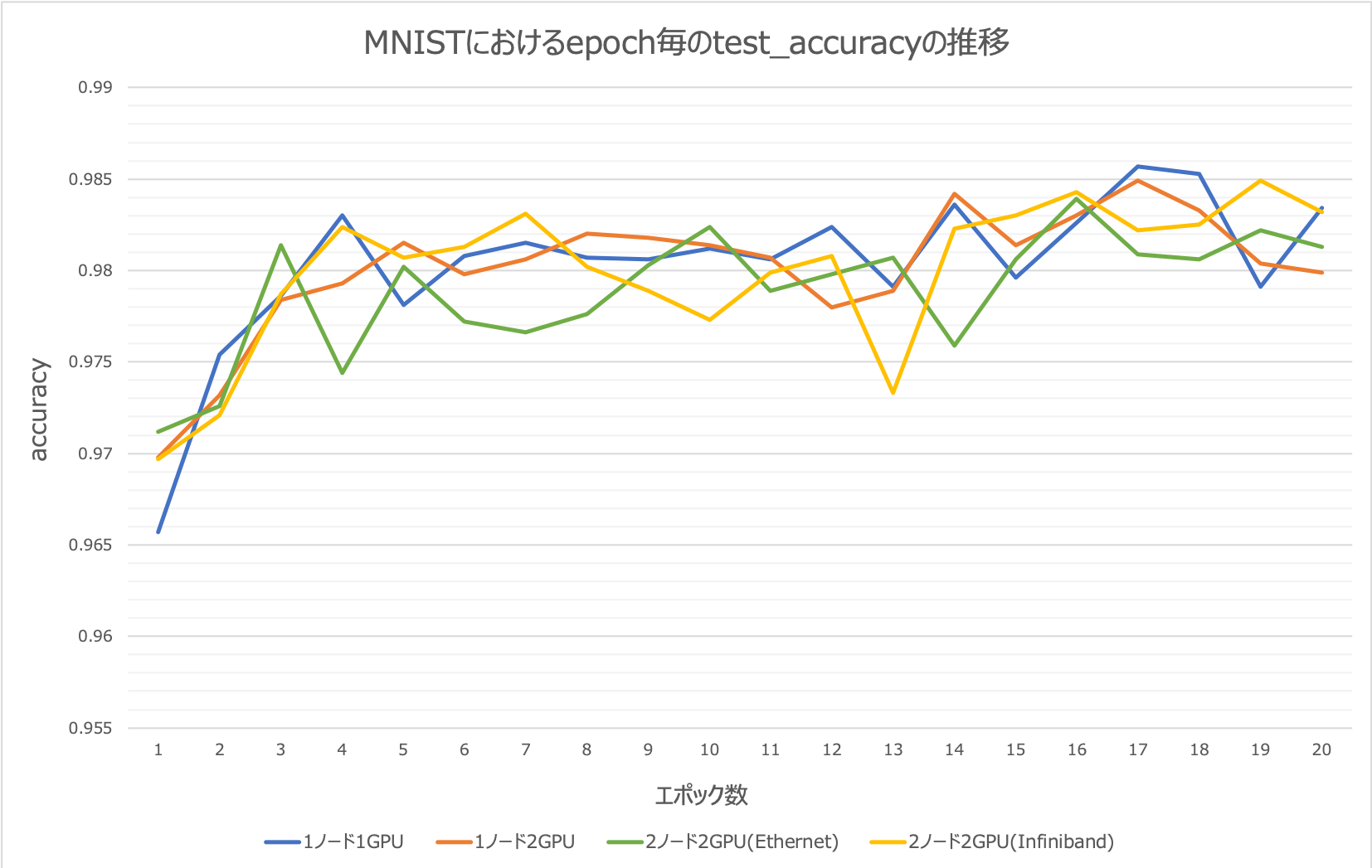
続いてMNISTにおけるエポック数毎のtest_accuracyの推移グラフを次に示します。エポック数ごとの推移を見ると1GPUと比べて2GPUによる分散処理との差異はあまり大きくはないように見えますね。非常に精度が求められる問題設定や課題ではない限り、分散処理は有効であることが言えます。
CIAFR10
続いてCIFAR10における検証内容を確認していきます。
MNISTと同様に検証では次の条件を統一して学習を行いました。
- ニバッチサイズ: 64
- エポック数: 200
- 学習モデル: VGG
検証項目ごとのスループットと精度の結果は次のようになりました。スループットはMNISTの時よりも分散学習にて学習を行った場合の方がスループットが向上していることがはっきりと分かります。また、Infinibandを介した分散学習が最もスループットが良いと言う結果になりました。データセットのサイズやエポック数が大きくなると分散学習による効果がみえてきますね。1GPUで200エポックを学習させるのに約110分かかるところが約30分短縮できるとなると非常に大きな効果であると言えるのではないでしょうか。また、InfinibandとEthernetの差があまり大きくないのは今回の環境が10GbEと言う非常に高速なEthernet環境で実行したことが結果につながったと考えられます。精度については1ノードの学習が最も高いという結果になっています。これは先ほどのMNISTの場合と全く同じ要因でAll-Reduceの処理が精度に影響を与えていることによるものと考えられます。
| 項目 | ノード数 | GPU数 | 通信 | スループット(s) | accuracy |
|---|---|---|---|---|---|
| 1 | 1 | 1 | - | 6610.07 | 0.917994 |
| 2 | 1 | 2 | - | 5861.48 | 0.916238 |
| 3 | 2 | 2 | Ethernet | 5271.01 | 0.91604 |
| 4 | 2 | 2 | Infiniband | 5257.9 | 0.913074 |
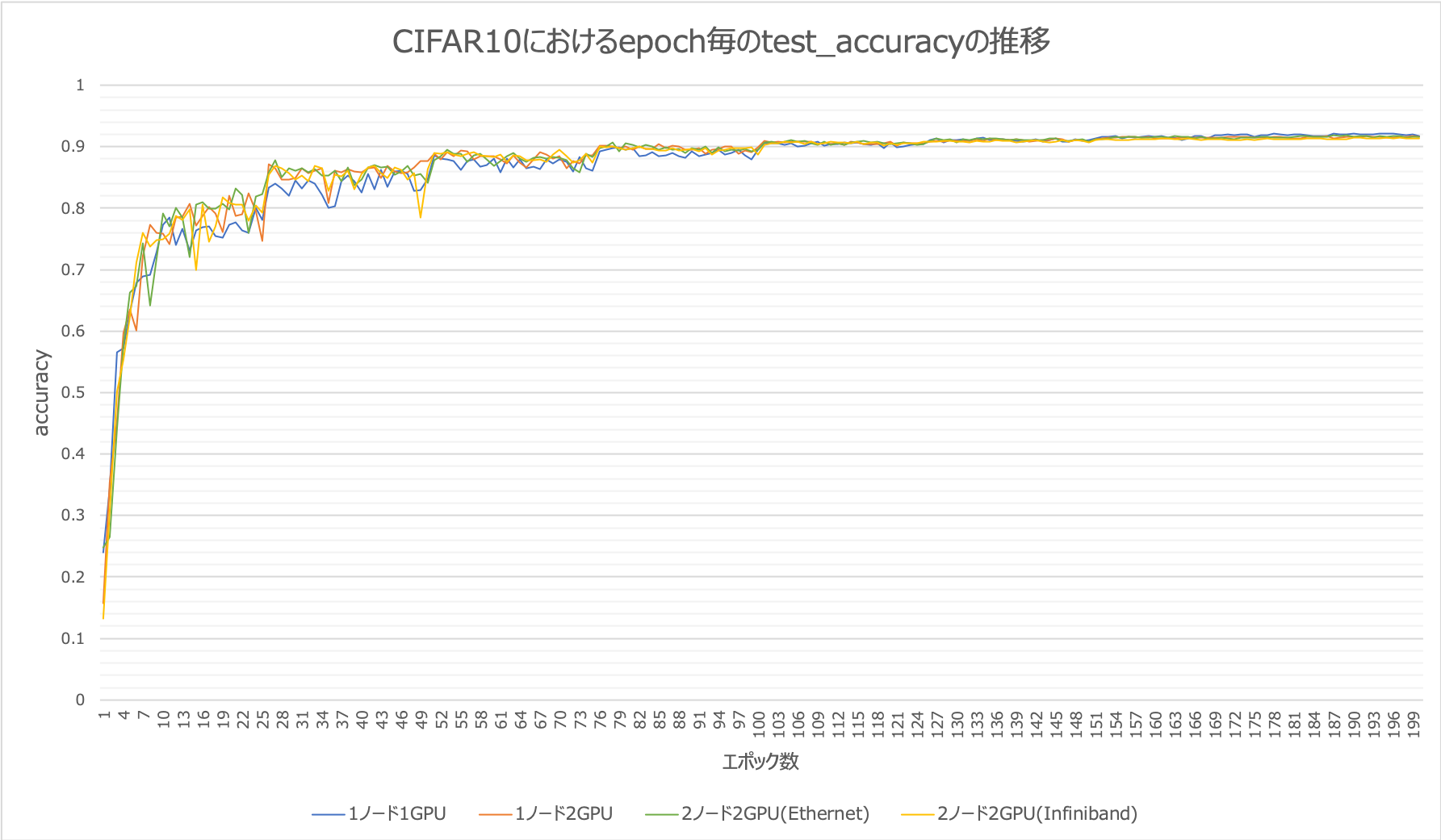
続いてCIFAR10におけるエポック数毎のtest_accuracyの推移グラフを次に示します。4つの検証項目の全てがほぼ同じ精度で収束していることが理解できると思います。分散学習はこのようにスループットを向上させつつ、汎化性能を維持したまま学習できるということが言えるので、より良い精度のモデルをパラメーターチューニングしながら作り上げていくDeepLearningのプロセスの効率化に今後も大いに活躍してくれそうですね。
結論
今回は「Infnibandを用いたGPU環境検証」というテーマでInfinibandによる分散学習のスループット向上について説明しました。DeepLearningの課題の1つでもある学習時間が非常にかかるという点についての解決手段として有効であることを示しました。DeepLearningで複雑なことに挑戦すればするほど、その効果が発揮されると考えられます。そのため、DeepLearningではソフトウェアレイヤーに注目が集まりがちですが、インフラレイヤーの工夫によってさらに効率的に最適なモデルの生成を支援することができるようになります。今回の検証の中でもお話ししたように、スループットを向上させることが主目的にならないように意識しましょう。DeepLearningにおいて最も重要なのは高い汎化性能を持った学習モデルを生成することです。常に何の課題を解決するのかを忘れずに楽しいDeepLearningライフをこれからも送っていきましょう。