



技術解説
NVBLASを使って「R」の並列演算処理を高速化
2018.11.22

NTTPC GPUエンジニア

統計解析向けプログラミング言語「R」は、コーディングがシンプルでさまざまなライブラリが公開されているため、幅広く活用されています。
ビッグデータ解析を行う際にネックとなるのが、Rの処理速度です。解析するデータが多くなればなるほど処理に時間がかかるという問題があります。
Rを高速化させるためには
① コードの見直し
- forではなくapplyを使う
- 繰り返し処理はさせずベクトル演算を使う
② R packageを試用する
- snow packageでapplyを並列処理化する
などがあります。これらは、繰り返し処理を行っている部分をシンプル化することで処理速度の向上にトライしています。
RでGPUを使う方法はいくつかあります。
| - | NVBLAS | gputools | gpuR |
|---|---|---|---|
| 概要 | GPUを使用する BLASを実装する |
GPUを使用する 新たな関数を実装する |
GPUを使用する 新たな関数を実装する |
| インストール方法 | CUDA®同梱 | R package | R package |
| GPU | NVIDIA製品のみ | NVIDIA製品のみ | NVIDIA、AMDなど (openCL動作可能なGPU) |
今回は、インストールが簡単でコードの書き換えも不要な「NVBLAS」を採用しました。
※本記事は2019年時点の情報に基づいたものです。
BLASとNVBLAS
本題に入る前に、BLAS ( Basic Linear Algebra Subprograms ) について説明します。 BLASは、基本的な線形演算(行列やベクトル計算など)を行う関数群です。 RにもBLASが使われているため、「BLASの高速化=Rの高速化」ということになります。主なBLASの高速化手法は、デフォルトのBLASからより速いBLASに置き換えることです。
BLASには3つのレベルがあります。
| レベル | 内容 | 主な関数 |
|---|---|---|
| Level 1 | ベクトルとベクトルの演算 | axpy_ ( ベクトルの加算 ) |
| Level 2 | 行列とベクトルの演算 | gemv_ ( 一般行列とベクトルの積 ) |
| Level 3 | 行列と行列の演算 | gemm_ ( 一般行列と一般行列の積 ) |
NVBLASは、NVIDIAが提供するGPUによって高速化されるBLAS Level 3ルーティンを実装するBLASです。データ型はDouble型のみサポートしています。
したがって、高速化の恩恵をより多くうけるためには、Double型でLevel 3ルーティンを使うようにR側のコードを工夫することが重要になります。
検証
では実際に、GPUサーバー上でNVBLASを使用することで、デフォルトBLASを利用する場合より高速に処理できるかを検証してみたいと思います。
構成
サーバー
- 筐体 : Supermicro® SYS-6019U-TR4
- CPU : Intel® Xeon® Gold 6150 CPU @ 2.70GHz *
- GPU : NVIDIA® Tesla® V100 16GB
OS / ソフトウェア
- OS : Ubuntu 16.04.5 LTS
- NVIDIA Driver : 396.44
- CUDA : V9.0.176
- R : 3.4.4
NVBLASの使用準備
CUDAの一部としてインストールされているため、別途入れる必要はありません。
RでNVBLASを使用する手順は下記の通りです。
- 設定ファイルを作成する
今回は/etc/nvblas.confという設定ファイルを作成します。次の設定で作成しました。NVBLAS_LOGFILE nvblas.log NVBLAS_TRACE_LOG_ENABLED NVBLAS_CPU_BLAS_LIB /usr/lib/libblas.so NVBLAS_GPU_LIST ALL NVBLAS_TILE_DIM 2048 NVBLAS_AUTOPIN_MEM_ENABLED
ここでの重要な要素は、「NVBLAS_CPU_BLAS_LIB」と「NVBLAS_GPU_LIST」です。- NVBLAS_CPU_BLAS_LIB
ここでは、NVBLASが実装していないBLAS Level 1, 2ルーティンを実装しているBLASを指定します。今回は、RのデフォルトのBLASを指定しています。
Rが現在使用しているBLASやその場所がわからないときは、下記の手順を実行してください。
①ターミナルからR を実行
②別のターミナルで下記コマンドを実行してpidを取得ps aux | grep exec/R
③下記コマンドを実行してBLASと場所を確認lsof -p <pid> | grep 'blas\|lapack'
- NVBLAS_GPU_LIST
使用するGPUを指定します。今回はすべてのGPUを使う設定にしました。
- NVBLAS_CPU_BLAS_LIB
- R起動時に環境変数を設定する
LD_PRELOADとNVBLAS_CONFIG_FILEという変数を設定する必要があります。- LD_PRELOAD
使用するNVBLASの場所を指定します。今回の環境ではここでした。
/usr/local/cuda-9.0/lib64/libnvblas.so - NVBLAS_CONFIG_FILE
作成したconfigファイルの場所を指定します。今回はここです。
/etc/nvblas.conf
- LD_PRELOAD
これでNVBLASの使用準備は完了です。
NBVLAS速度測定ベンチマーク
NVBLASの準備が整ったら、NVBLASとBLASの処理速度を比較するためにベンチマークを実行します。今回使用するベンチマークは、R-benchmark-25です。
- ベンチマークスクリプトをwgetしてきます
wget http://r.research.att.com/benchmarks/R-benchmark-25.R
- wgetしたファイルのあるフォルダで、ベンチマークを実行します。
最初はデフォルトのBLASを使っての測定なので、環境変数は設定しません。
cat R-benchmark-25.R | time R --slave
--- End of test ---の表記が出てきたら実行成功です。
次はNVBLASを使ってのベンチマーク実行です。
cat R-benchmark-25.R | LD_PRELOAD=/usr/local/cuda-9.0/lib64/libnvblas.so NVBLAS_CONFIG_FILE=/etc/nvblas.conf time R --slave
こちらも同じく、--- End of test ---の表記が出てきたら実行成功です。
結果
NVBLASとデフォルトBLASの速度を比較すると以下のグラフのようになりました。
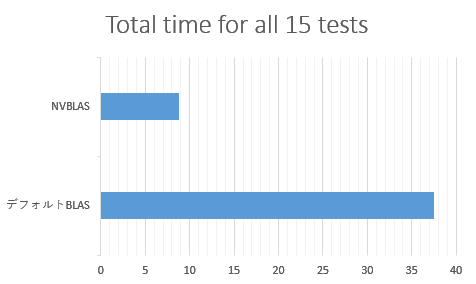
NVBLASを使用することで約4.25倍の速度向上が確認できました。
まとめ
GPUサーバ―上でNVBLASを使用することで、Rの高速化が実現できることがわかりました。Rを利用される方の参考になれば幸いです。