



基礎知識
NVIDIA H200 GPUで加速する生成AI ~H100との比較から次世代B200シリーズまで徹底解説~
2025.04.25

GPUエンジニア

大規模言語モデル(LLM)やディープラーニングの急速な発展により、高性能GPUへの需要が飛躍的に高まっています。そんな中、NVIDIAは2023年後半に、H100 Tensor Core GPU(以下、H100)の後継モデルとなるH200 Tensor Core GPU(以下、H200)を発表しました。さらに、次世代のBlackwellアーキテクチャを採用したB200シリーズなど、革新的なGPU製品ラインナップを続々と展開しています。
本記事では、H200の主な特徴やH100との違い、H200 NVL構成の詳細、そして次世代のB200シリーズに至るまで、最新GPUの全体像をわかりやすく解説します。
AIモデルの大規模化と電力効率の両立が求められる今、これらの先進GPUがもたらす技術革新や導入メリットについても詳しく紹介し、AI開発環境の整備を検討している方に最適な情報をお届けします。
目次:
1. NVIDIA H200 GPUとは

H200は、NVIDIAのHopperアーキテクチャを採用した新世代のHopper系GPUです。H100の後継となるこのGPUは、LLMの処理能力を大幅に向上させた画期的な製品です。
2. H200の特徴
ここでは、H200の主な特徴を見ていきましょう。
2.1 第4世代Tensor Coreを搭載したHopperアーキテクチャ
NVIDIA H200は、前世代のH100と同様に、Hopperアーキテクチャを採用しています。
Hopperアーキテクチャは、大規模AIモデルのトレーニングや推論を高速化するために設計されたもので、高い並列処理性能と大容量GPUメモリの搭載が大きな特徴です。
その中核をなすのが、第4世代Tensor Core※1 です。これはAIワークロードに不可欠な行列計算を圧倒的なスピードで処理する専用演算ユニットで、前世代よりも処理効率が大きく向上しています。
さらに、Hopperアーキテクチャではトランスフォーマーエンジンと呼ばれる専用ハードウェアも搭載されており、ChatGPTのようなLLMで用いられるトランスフォーマーモデルの処理を大幅に高速化します。
※1 Tensor Coreとは?
Tensor Coreは、ディープラーニングで多用される行列演算(特に行列の積)を高速化するためにNVIDIAが開発した専用演算ユニットです。第4世代Tensor Coreでは、従来のFP16やTF32に加えてFP8(8ビット浮動小数点)に対応し、より少ない電力とメモリ帯域で高速な計算が可能になりました。これにより、大規模言語モデルのトレーニングや推論でも高効率な処理が実現されています。
2.2 HBM3eを搭載した大容量・高帯域メモリ構成
H200は、業界で初めてHBM3e(High Bandwidth Memory 3e) を搭載しました。
この強化されたメモリ構成により、LLMの膨大なパラメータや長いコンテキスト情報をGPUメモリ上に保持したまま処理できるようになりました。その結果、外部メモリとの頻繁なデータ転送や複数GPU間の分散処理を減らし、レイテンシ(処理の遅延)の低減やシステム構成の簡素化に寄与します。
3. H100とH200の性能比較
H200は、同じHopperアーキテクチャを採用するH100と比べて、処理能力とメモリ性能が大幅に向上しています。以下の画像のように、LLMの推論処理では、H200はH100に対して最大1.9倍の推論性能を発揮します(例:Llama2 70B使用時)。
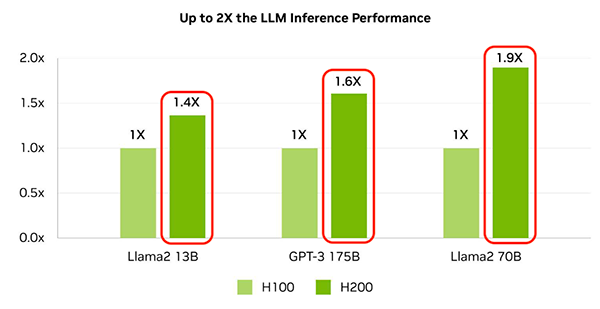
このパフォーマンス向上は、主に次のような要素によって実現されています。
| 項目 | H100 | H200 | 向上率・特徴 |
|---|---|---|---|
| アーキテクチャ | Hopper | Hopper | 同一アーキテクチャ |
| メモリ容量 | 80GB | 141GB | 約1.76倍 |
| メモリ帯域幅 | 3.35TB/s | 4.8TB/s | 約1.4倍 |
| 推論性能 (LLM例) |
1.0倍(基準) | 最大1.9倍 (Llama 2 70B) |
HBM3e・変換器最適化の効果 |
| 低精度演算 (FP8/16など) |
標準対応 | 最適化 | AI処理を高速化 |
| 並列処理効率 | 標準 | 最適化 | モデル並列・パイプライン並列の強化 |
また、HPC(高性能コンピューティング)の分野では、最新のx86系CPUと比較して、H200は最大110倍の性能を発揮します。科学技術計算や物理シミュレーションなど、高精度の浮動小数点演算が求められる用途においても、H200の計算能力は大きなアドバンテージとなっています。
これらの改良により、H200は大規模AIモデルのトレーニングおよび推論において、H100を大きく上回る性能を発揮します。特に、コンテキスト長が拡大し続けるLLMの進化に対応するうえで、大容量メモリと高速な帯域幅を備えたH200は、現行世代の中でも非常に実用性の高い選択肢のひとつです。
4. NVIDIA H200 NVLとは

最新のAIワークロードに対応するためには、単一のGPUだけでなく、複数のGPUを効率的に連携させる技術が重要です。NVIDIA H200 Tensor Core GPU NVL(以下、H200 NVL)は、H200 GPUを2枚ペア構成で提供し、大規模なAIワークロード向けに最適化された高密度GPUソリューションです。NVIDIA® NVLink®によってGPU間を高速に接続することで、複数GPU間での大容量データ共有やモデルの分散処理を効率化します。
5. H200 NVLの特徴
ここでは、H200 NVLの技術的な特徴と、それがもたらす性能向上について解説します。
5.1 NVIDIA® NVLink®による超高速接続
H200 NVLは、H200 GPUを2基ペアで構成し、それらをNVIDIA独自の相互接続技術「NVIDIA® NVLink®」※2 で高速に直結することで、単体のH200を上回る処理性能とスケーラビリティを実現した高密度GPU構成です。
H200 NVLでは、NVIDIA® NVLink®専用のブリッジボードによってGPU同士を結合し、最大900GB/秒という圧倒的な相互接続帯域幅を実現しています。これは、PCIe Gen5(理論最大約128GB/秒)と比較して約7倍の高速通信に相当します。
この超高速な相互接続により、2基のGPUがあたかも1つの統合GPUのように連携し、H100 NVLと比較してLLM推論で最大1.7倍、HPC処理で最大1.3倍の性能向上を実現します。
※2 NVIDIA® NVLink®とは?
NVIDIA® NVLink®とは、NVIDIAが開発したGPU間の直接接続技術で、従来のPCIe(Peripheral Component Interconnect Express)よりもはるかに高い帯域幅と低レイテンシを実現するインターコネクトです。PCIeではデータのやり取りがCPUを介する形になりがちですが、NVIDIA® NVLink®ではGPU間で直接・高速にメモリデータをやり取りできます。これにより、複数GPUを使った並列処理や大規模モデルの実行において、スループットが大きく向上します。
H200 NVLの技術的特徴
H200 NVLの価値は、単にGPUを2基つなげただけではなく、以下のような特徴があります。
- 統合GPUメモリによる処理スケーラビリティ
- 前世代比でのメモリ性能向上
- NVIDIA® NVLink®を活かした低レイテンシ・高スループットな通信
H200 NVLの特徴の詳細は、次の通りです。
| 項目 | 内容 |
|---|---|
| メモリ容量 | GPUあたり141GB(2基合計: 282GB) |
| メモリ性能(前世代比) | 容量:1.5倍、帯域幅:1.2倍(対 H100 NVL) |
| GPU間接続方式 | NVIDIA® NVLink® |
| メモリ間転送最適化 | GPUダイレクトアクセスによる超高速なデータ共有 |
このように、H200 NVLはメモリ容量・帯域幅・相互接続の各要素が強化されており、大規模なAIワークロードや科学技術計算において、より高いスループットと低レイテンシな処理を可能にするGPU構成となっています。
5.2 データセンターのラックスペース効率の向上
H200 NVL構成のもう一つの大きな特徴は、データセンターのラックスペース効率の向上と、運用コストの削減です。従来、2基のGPUを搭載するには2つのPCIeスロットが必要でしたが、H200 NVL構成では2基のGPUを事実上1つのユニットとして扱えるため、スペース効率が大幅に向上します。このような構成により、以下のようなメリットがあります。
- サーバーラック1Uあたりのコンピューティング密度の向上:同じラックスペースでより多くの演算能力を実現し、施設投資効率が向上
- 限られたデータセンタースペースでの処理能力最大化:都市部の高コストなデータセンターでも、物理的な制約を超えて計算能力を拡大可能
- 配線の簡素化とメンテナンス性の向上:ケーブル数の削減により冷却効率が向上し、障害率の低減と運用コスト削減を実現
- 電力効率の最適化:CPU-GPU間の通信経路短縮により電力消費が削減され、年間電力コストを抑制
さらに、このような高密度構成は、スペース効率だけでなくトータルコストの最適化にも貢献します。PCIeスロット数の削減、電力供給の簡素化、冷却効率の向上などにより、同等の計算能力を得るためのトータルコストが削減されます。
6. 次世代GPU、B200シリーズとは
H200に続く次世代GPUとして登場したのが、NVIDIA Blackwellアーキテクチャを採用したB200シリーズです。B100/B200は、H100/H200のアーキテクチャを踏襲しつつ、さらなる性能向上と電力効率の最適化を実現しています。ここでは、H200からB200への進化ポイントを中心に、Blackwell シリーズの特徴を解説します。
6.1 NVIDIA B200 GPUとは
B200は、NVIDIAが2024年に発表した次世代GPUアーキテクチャ「Blackwell」を採用した革新的な製品です。
Blackwellは、従来のHopper世代を大幅に上回る性能を実現しており、B200はその代表例として、AIモデルのトレーニングおよび推論において大幅な性能向上を提供します。
Blackwellに基づくB200の性能向上は次の通りです。
| 項目 | 内容 |
|---|---|
| トレーニング性能 | H100に対して最大3倍 |
| リアルタイム推論性能 | 最大15倍 |
| エネルギー効率 | Hopperの10J/tokenから、0.4J/tokenへの大幅低減 |
このような飛躍的な性能の背景には、Blackwellアーキテクチャにおける数々の技術革新があります。
Blackwellアーキテクチャの技術的特徴
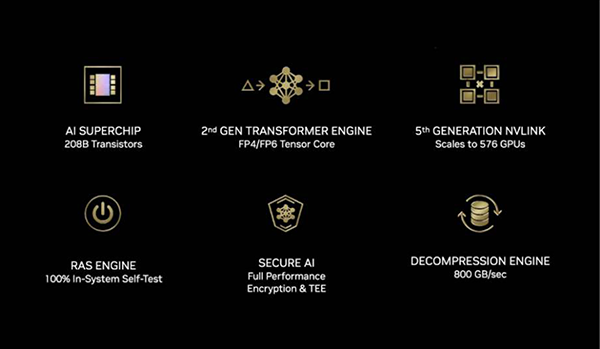
画像が示すように、Blackwellでは、2nd GEN Transformer Engine(FP4/FP6対応)や第5世代NVIDIA® NVLink®、RASエンジン、800GB/sのデコンプレッションエンジンなど、多数の先端技術が導入されています。B200はこれらの機能を最大限に活用することで、従来のHopper世代を大幅に上回る演算性能とメモリ帯域幅、そして高い信頼性を実現しています。
特に、こうした飛躍的な性能向上の背景には、最新の3Dパッケージング技術の採用 があります。
B200では、TSMCのCoWoS技術を活用し、レチクルサイズの上限で製造された2個のGPUダイ※3 と8個のHBM3eメモリダイを1つのパッケージ内に統合しています。
さらに、2つのGPUダイは、10TB/sの帯域を持つNV-HBI(High-Bandwidth Interface)によって接続されており、実質的に1個のGPUとして機能します。
これにより、製造時の物理的制限を克服しながら、圧倒的な演算能力と大容量メモリの両立を実現しています。
※3 ダイとは?
ダイ(Die)とは、シリコンウェハーから切り出された1つの半導体チップを指します。GPUやCPUの本体となる部分で、製品化の前段階の構成単位です。
B200の詳細や製品ラインナップについては、以下の記事をご覧ください。
生成AIのパフォーマンスが大幅アップ!?NVIDIA BlackwellアーキテクチャGPUの性能
7. NVIDIA GPU導入検討のポイント
最新のNVIDIA GPUを導入する際には、用途や既存インフラとの兼ね合いを考慮して最適な選択をする必要があります。H200(単体またはNVL構成)、B200シリーズはそれぞれ異なる特性を持ち、最適な用途が異なります。
また、これらの高性能GPUは単なる計算リソースの増強ではなく、組織のAI戦略全体に関わる重要な投資判断となります。たとえば、LLMのトレーニングや推論、ベクトル検索、HPCワークロードなど、目的に応じて求められる性能要件も大きく異なります。
導入にあたっては、演算性能やメモリ容量、インターコネクト、消費電力、冷却方式、ソフトウェア対応など複数の観点から、製品の特性と自社の要件を照らし合わせて選定することが重要です。
8. まとめ
本記事では、NVIDIA H200を中心にその特徴・技術を解説しました。さらには、H200の後継であるB200について、GPU導入時の検討ポイントまで解説しました。
H200の主な革新点は、HBM3eメモリの初採用による141GBの大容量メモリと4.8TB/秒の高帯域幅、NVL構成によるスペース効率の最適化、そしてLLM推論での従来比約2倍の性能向上です。また、B200は次世代Blackwellアーキテクチャにより圧倒的な性能と電力効率を実現しています。
世界は急速に進化しており、これらの最新GPUテクノロジーが生成AI技術の発展を加速させています。用途や既存インフラに応じた適切な選択が、コストパフォーマンスと将来の拡張性の鍵となるでしょう。
最新のNVIDIA GPU導入をご検討の際は、ぜひNTTPCにご相談ください。お客さまの環境や要件に適したGPUソリューションを提案いたします。お気軽にご相談ください。
▶︎お問い合わせはこちら