



性能検証
【ベンチマーク結果】NVIDIA DGX™ B200でGPT-OSSを動かしてみた
2025.10.30

GPUエンジニア
石渡 巧

みなさんこんにちは!NTTPCコミュニケーションズの石渡です。
このたび当社では、新たに検証機として「NVIDIA DGX™ B200」を導入しました!
今回はこのDGX B200検証機を使って、先日リリースされた「GPT-OSS-20B/120B モデル」を vLLMで動かしてみました。本記事では、その動作手順と検証結果、さらに当社が独自に用意したベンチマークソフトで測定した内容も紹介します。
1. はじめに
vLLMとは?
まず、今回検証したvLLMについておさらいしておきましょう。vLLM(Variable-Length Language Model Server) は、大規模言語モデル(LLM)を高速・効率的に推論できるオープンソース推論エンジンです。
OpenAI の API と互換性を持ち、サーバー1台でもクラスタでも同じように動作します。
たとえば、1基のGPUで動かす場合も、クラスタリングされた数十基のGPUを使う場合も、実行コマンドやAPIエンドポイント(例:/v1/completions)は全く同じです。
そのため、開発者は環境を変えてもコードを書き換える必要がなく、vLLMのスケジューラが自動的にGPU間で負荷分散や通信を処理してくれます。
これにより、「開発環境では1台のGPU」「本番環境では複数GPUクラスタ」といった構成であっても、環境の違いを意識せずに同じ方法でモデルを動かすことができます。
従来の Hugging Face Transformers ベース推論と比べると、vLLMには以下のような特色があります。
- PagedAttention ・・・長文推論をGPUメモリ内で効率的に扱う(スワップのような仕組み)
- 非同期スケジューリング ・・・同時リクエストを重ねてGPUをフル稼働させる
- NVIDIA🄬CUDA🄬 Graph最適化 ・・・繰り返し処理をGPU側にキャッシュしてCPU負荷を軽減
- OpenAI互換API ・・・/v1/chat/completions で直接アクセス可能
つまり、 vLLM は「LLMをAPIサーバーのように運用できるエンジン」です。PyTorchやTransformersを直接触らなくても、LLMをREST API経由で叩けるのが最大の利点です。
GPT-OSSとは?
GPT-OSS は、OpenAIが2025年に公開したオープンソースのChatGPT系モデル群の総称です。OSS(Open Source Software)版の ChatGPT として、20B・120Bといったパラメータサイズのモデルが用意されています。
- GPT-OSS-20B:推論・実験向けの中型モデル(20Bパラメータ)
- GPT-OSS-120B:研究・基盤構築向けの大型モデル
商用ChatGPTの完全再現というよりも、構造・性能・ツール統合(関数呼び出しなど)を公開ベースで再現した研究向けモデルといえるでしょう。
vLLMはこのGPT-OSSシリーズを公式サポートしており、
vllm serve openai/gpt-oss-20b
といったように、コマンドラインで指定するだけで動作します。
2. 今回の検証の目的
今回導入した新マシン「DGX B200」 は、 NVIDIA の新世代アーキテクチャ「Blackwell GPU(NVIDIA B200 GPU)」を搭載しており、前アーキテクチャのNVIDIA Hopper™世代からメモリ帯域とAI演算効率が大幅に向上しています。
本検証では
- Blackwell GPUでは、 vLLM に実装されているFlashInfer(後述します)がどの程度最適化されているのか
- 前世代のHopper GPU(NVIDIA DGX™ H100)と比べ、どのくらい推論スループットが向上するのか
の2点を確認していきたいと思います。
3. 事前準備
LLMのインストールと環境準備
今回の検証は、NVIDIAが提供している公式PyTorchコンテナ
nvcr.io/nvidia/pytorch:25.02-py3 をベースに行いました。
参考:リリースノート
このコンテナには、CUDA 12.8 / NVIDIA🄬 cuDNN / NCCL / PyTorch があらかじめ最適化済みで含まれており、vLLMを動かす上で最も安定した環境のひとつです。
起動コマンドは以下の通りです
sudo docker run -it \ --gpus all \ --ipc=host \ --ulimit memlock=-1 \ --ulimit stack=67108864 \ --network host \ -v /workspace:/workspace \ -v /root/.cache/huggingface:/root/.cache/huggingface \ --name vllm-b200 \ nvcr.io/nvidia/pytorch:25.02-py3
ここで指定しているオプションは、GPUやメモリまわりの設定など“お馴染みのもの”に加えて、以下のような工夫を入れています。
--network host
→ vLLMのOpenAI互換API(:8000/v1/chat/completionsなど)を、外部シェルや他ノードから直接叩けるように、ホストネットワークを共有しています。
-v /root/.cache/huggingface:/root/.cache/huggingface
→ GPT-OSSモデルはサイズが大きく、ダウンロードに時間がかかるため、キャッシュをローカルにマウントして再利用できるようにしています。ネットワークが切れた場合でも途中から再開可能です。
また、--rm は付けていません。コンテナを毎回削除してしまうと、モデルキャッシュやインストール済みのvLLMをすべて再構築する必要があるため、検証環境では永続コンテナとして運用しています。
vLLMのインストール
コンテナが起動したら、まずは vLLMのインストール から始めます。
今回の環境(DGX B200 / CUDA 12.8 / PyTorch 25.02)に対応しているのはvLLM 0.10.2 以降です。
特にバージョンを指定しない場合、最新版がインストールされます。
# sudo pip install vllm
こちらが実行結果です。最新版の0.11.0がインストールされましたね。
4. 検証内容
vLLM標準構成でのベンチマーク実行
まずは環境変数を一切設定しない “素のvLLM”で動作確認とベースラインを取りました。
vllm serve openai/gpt-oss-20b \
--async-scheduling \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 8 \
--max-model-len 131072 \
--gpu-memory-utilization 0.9 \
--override-generation-config '{"temperature": 1.0, "top_p": 1.0, "top_k": 40}'
表 各オプションの説明
| オプション | 説明 |
|---|---|
| openai/gpt-oss-20b | 使用するモデルを指定。今回はOpenAIが公開しているGPT-OSS-20B。vLLM側で自動的にHugging Faceから取得します。 |
| --async-scheduling | 非同期スケジューリングを有効化。リクエスト間のGPUアイドル時間を減らし、スループットを向上させます。Blackwell/Hopper環境では推奨設定です。 |
| --host 0.0.0.0 | 外部からアクセス可能にするためのホスト指定。別シェルや他ノードから localhost:8000 でAPI呼び出し可能になります。 |
| --port 8000 | OpenAI互換APIを待ち受けるポート番号。デフォルトも8000ですが、明示的に指定しています。 |
| --tensor-parallel-size 8 | 8GPUをテンソル並列で使用。DGX B200全GPUをフルに使います。 |
| --max-model-len 131072 | 入力+出力を合わせた最大トークン長。長文推論にも対応可能な大きめの設定です。 |
| --gpu-memory-utilization 0.9 | 各GPUのメモリを90%まで利用。OOMを避けつつキャッシュ効率を高めます。 |
| --override-generation-config | 推論パラメータを指定。ここではランダム性をほぼ排除(temperature=1.0, top_p=1.0, top_k=40)して安定した出力を得ます。 |
起動したら上記のようになるので、別シェルで先ほど起動したコンテナイメージに入ります
# docker exec -it vllm-b200 /bin/bash
推論サーバーがきちんと動いているか、試しに簡単な対話側のスクリプトを組んで実行してみます。
うまく動きました!
vLLMには標準のベンチマークテストがあるのでそちらを実行してみましょう。
vllm bench serve \ --host 0.0.0.0 \ --port 8000 \ --model openai/gpt-oss-20b \ --dataset-name random \ --random-input-len 1024 \ --random-output-len 1024 \ --ignore-eos \ --max-concurrency 512 \ --num-prompts 2560 \ --save-result \ --result-filename vllm_20b_tp8.json
※各オプションはvLLMの公式ページを参考にしてください。
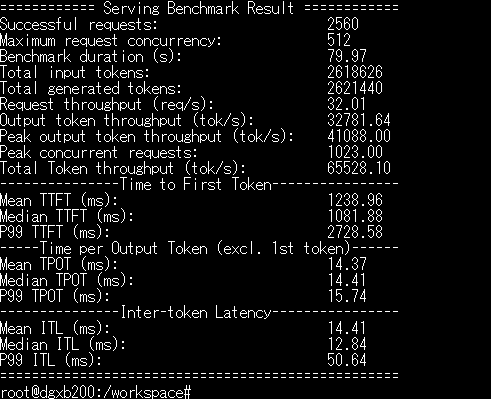
結果
- 総トークンスループット(Total token throughput):約 65.5 k tok/s
- 1 リクエストあたり:32 req/s
- 成功率100%(2560件すべて成功)
次にFlashInferとMXFP4の設定をいれて最適化します。
FlashInferとは?
FlashInferは、FlashAttention、SparseAttention、PageAttention、Sampling などの LLM GPU カーネルの高性能実装を提供する大規模言語モデル用のライブラリおよびカーネル ジェネレーターです。
【主な機能】
- 効率的なスパース/高密度アテンションカーネル:
CUDA コアおよびテンソルコア (FA2 と FA3 の両方) テンプレート上のスパース (ページ) /高密度 KV ストレージに対する効率的な単一/バッチアテンション。ベクトルスパースアテンションは、同じ問題サイズを持つ高密度カーネルの帯域幅の90%を達成できます。 - 負荷分散スケジューリング:
FlashInferは、負荷の不均衡の問題を軽減するために、可変長入力の計算を段階的にスケジュールするアテンション計算の段階を分離します。 - メモリ効率:
FlashInferは、階層型KV-Cacheにカスケードアテンションを提供し、Grouped-Query Attentionを高速化するためのHead-Queryフュージョンと、圧縮されたKV-Cacheに低精度のアテンションと融合RoPEアテンションのための効率的なカーネルを実装しています。 - カスタマイズ可能なアテンション:
JIT コンパイルを通じて独自のアテンション バリアントをもたらします。 - CUDAGraph と torch.compile の互換性:
FlashInfer カーネルは、CUDAGraphs と torch.compile によってキャプチャされ、低遅延の推論が可能になります。 - 効率的なLLM固有の演算子:
ソートを必要とせずに、Top-P、Top-K/Min-Pサンプリングのための高性能融合カーネル。
FlashInfer は、PyTorch、TVM、C++ (ヘッダーのみ) API をサポートしており、既存のプロジェクトに簡単に統合できます。
vLLM は、モデルが量子化を使用して適切なバックエンドを選択しているかどうかを自動的に検出しGPU に最適なアテンションバックエンドを選択します。
Blackwell GPUでは、vLLMは利用可能な場合はFlashInferベースのアテンション(NVIDIAのTensorRT-LLMカーネルを組み込んでいる)を選択するか、必要に応じてFlashAttentionにフォールバックします。そのため、FlashInferによる最適化で推論性能が向上します。
MXFP4とは?
MXFP4(Microscaling Format for 4-bit Floating-Point) は、Open Compute Project(OCP)AI Precision Formats ワーキンググループが標準化したAI推論・学習向けの4bit浮動小数点データ形式で、大規模なモデルデータのメモリ使用量を大幅に削減し、計算効率を向上させることができます。
実際にgpt-oss-120bでも、MoE部分の重みをMXFP4で量子化し単一のGPUでの動作を実現しています。
参考:https://huggingface.co/openai/gpt-oss-120b
BlackwellのTensor Coreは、従来のFP16やFP8に加えて、新たに NVFP4(NVIDIA Floating Point 4) という形式をネイティブ実装しています。
NVFP4は、FP8に近い精度を維持しながら、推論スループットを最大2倍に向上させることができると発表されています。
NVFP4はあくまで BlackwellのTensor Coreで直接扱うための演算フォーマットで、GPU内部で「どう計算するか」を定義した形式でありモデルを保存・共有するための形式ではありません。そのため、モデル層はMFXP4による効率化が必要です。
つまりGPUカーネルはFlashInferで最適化し、モデル層(MoE)はMFXP4で量子化してメモリ削減&効率化、ハードウェアレベルでNVFP4が演算処理を高速化するといった流れになります。
FlashInferのインストールとベンチマーク
起動中のvllm Serverを止めてから下記コマンドでインストールします。
# pip install vllm[flashinfer]
次に、FlashInferとMXFP4を有効化するための環境変数を設定します。
export VLLM_FLASHINFER_ALLREDUCE_FUSION_THRESHOLDS_MB='{"2":32,"4":32,"8":8}'
export VLLM_USE_FLASHINFER_MOE_MXFP4_MXFP8=1
この2行を追加してからvllmを起動します。
起動後、先ほどと同じコマンドでベンチマークを実施した結果がこちらです。
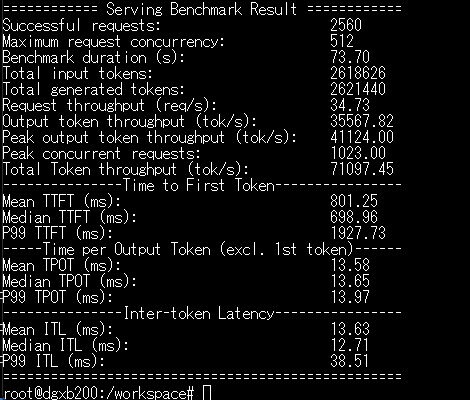
全てにおいて高速化されていますね!
まず大きかったのが TTFT(Time to First Token)=最初のトークンが出るまでの時間。
ここが約35%短縮されました。これは、FlashInferによる All-reduce Fusion の効果で、GPU間の通信がより効率化され、モデルの「立ち上がり」部分(prefillフェーズ)が軽くなったためです。
また、MXFP4 + FP8 の混合精度を使うことで、演算そのもののメモリ転送量が減り、decodeフェーズのトークン生成スピードもわずかに向上しました。
特にB200の新しいTensor Core構造ではこのMXFP4経路がネイティブ最適化されており、無理にFP16/FP8固定で動かすよりも安定してスループットを稼げる印象です。
総合的に見ると、総トークン処理性能は約8〜10%向上、そしてなにより「最初のレスポンスが返ってくる速さ」が明確に改善しています。ブラウザからのチャット推論など、対話型のLLM利用ではこの差が体感レベルでわかるほどの数値です。
5. 独自ベンチマークソフトでの測定結果
ここからは当社GPUエンジニアの大野が作成した推論ベンチマークツールを使って、20Bと120Bそれぞれの性能指数をみていこうと思います。
ツールの導入方法は大野のGithubで公開していますのでこちらを参考にしてください
参考:https://github.com/yasu-oh/online-bench-openai-async
まずは同じようにvllmを起動して別シェルを開きます。
手順に沿ってツールを展開します。openaiモジュールは既に導入済みだと思うので警告が出るだけです。
あとはコマンドを実行するだけです。
同時リクエストユーザー数と入出力トークンは変更可能です。
特に設定をしなければ下記の設定で実行されます。
128人同時リクエスト 入力 1,024トークン 出力 1,024トークン
① GPT-OSS-20B 実行結果
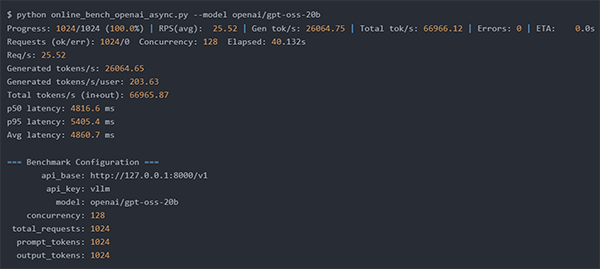
⇒秒間203トークン/1ユーザ
② GPT-OSS-120B 実行結果
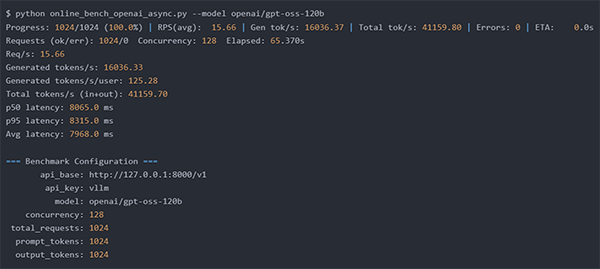
⇒秒間125トークン/1ユーザ
爆速ですね・・・DGX B200は1台でも小・中規模向け推論サーバーとしてはかなり優秀である事がわかりました。
当社では、前世代モデルであるNVIDIA DGX™ H100も検証機を保有しています。同じ内容でテストしたので比較してみましょう。
※H100はBlackwellとメモリの構造が異なり、FlashInferによる最適化ができないためH100ではCudaGraphの数値を変えて最適化しています。
① GPT-OSS-20B 実行結果
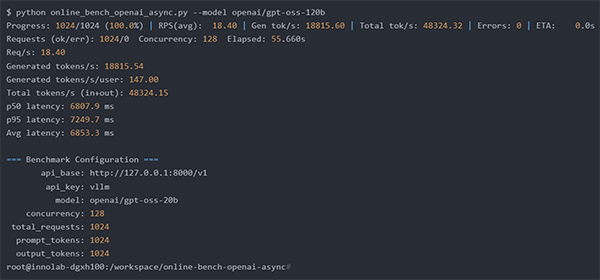
⇒秒間147トークン/1ユーザ
② GPT-OSS-120B 実行結果
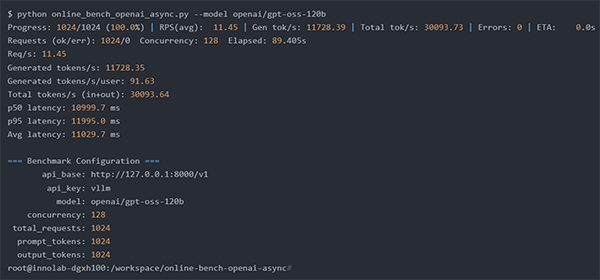
⇒秒間91トークン/1ユーザ
という結果になりました。
DGX B200は、同条件下でDGX H100に比べておおむね35〜40 %高速、レイテンシは約3割短縮。
FlashInferとMXFP4の最適化により、Blackwell世代のTensor Coreは期待どおりの性能を出していますね。
以下はおまけの追加検証です。
GPT-OSS-120Bを最適化した場合、ユーザー数を増やしたらどうなるか気になり見てみました。
① 256人同時リクエスト 入力 1,024トークン 出力 1,024トークン
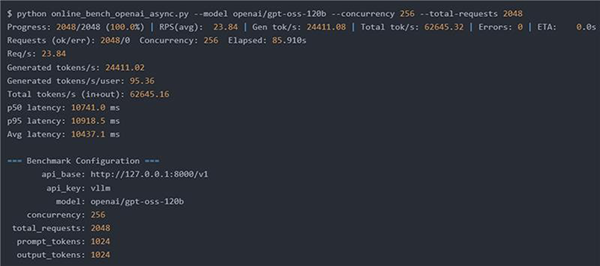
⇒ 秒間95トークン/1ユーザ
② 512人同時リクエスト 入力 1,024トークン 出力 1,024トークン
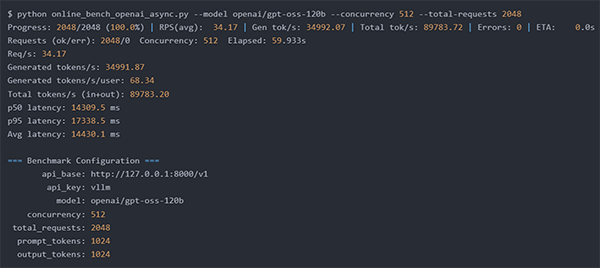
⇒ 秒間68トークン/1ユーザ
6. まとめ
今回、DGX B200上で vLLM + GPT-OSS を実際に動かしてみて、Blackwell世代の特徴が数値としても体感としてもはっきり出ていると感じました。
計測上では、総トークンスループットが約37%向上、平均レイテンシは約28%短縮と、前世代のDGX H100を大きく上回る結果になりました。この差はFlashInferによる通信効率化と、MXFP4精度による演算効率の向上によるものでしょう。
体感としても、最初のレスポンス(TTFT)がかなり短く、ベンチマーク結果どおり出だしが速くなった印象を受けます。スループットの揺れも小さく、安定して高い性能を維持できていました。
B200ではFlashInfer経路がデフォルトで有効になり、GPU間通信の効率とTensor Core側の演算がしっかり噛み合っている印象です。今回の結果を見る限り、B200は単に理論性能が高いだけでなく、実際の推論ワークロードに最適化された世代と言えると思います。
今後の大規模LLM推論の主軸になるポテンシャルを十分に感じました。
引き続き、今後リリースされる新製品も検証していきたいと思います!
※「OpenAI」「GPT」「ChatGPT」はOpenAI OpCo, LLCの商標および登録商標です。
※「NVIDIA」「CUDA」「NVIDIA🄬 cuDNN」「NVIDIA DGX B200」「NVIDIA Hopper」は米国およびその他の国における NVIDIA Corporation の商標または登録商標です。
※「PyTorch」はThe Linux Foundationの登録商標または商標です。