



基礎知識
Difyで実現するローカルLLM運用基盤:コスト・ガバナンス・拡張性を両立する実務設計の全体像
2026.03.18

GPUエンジニア

業務で生成AIを活用したい一方で、「機密情報を外部に送れない」「監査・ガバナンス要件が厳しい」「従量課金でコストが読みづらい」といった理由で、外部サービスの使い方に制約が出るケースは少なくありません。クラウドLLM(外部事業者が提供するLLMを、APIやマネージド基盤として利用する形態。例:Azure OpenAI Service、Amazon Bedrockなど)は便利な反面、組織のルールや扱うデータ次第で「使い方を設計しないと回らない」状態になりやすいのが実情です。
こうした制約が意識されるようになって以降、社内GPUなど自社管理の環境でLLMを動かすローカルLLMが、現実的な選択肢として検討される場面が増えています。背景には、オープンウェイトモデルや推論サーバ、コンテナ運用の選択肢が増え、自社環境に置いて運用するための“部品”が揃ってきたことがあります。ローカル運用は、データの外部送信範囲を設計で絞りやすい一方で、環境構築・ログ設計・権限管理・更新手順などを自分たちで整備する必要があり、運用の設計力が求められます。
実際、ローカルLLMを「動かす」だけで導入が進むとは限りません。たとえば、部門ごとにプロンプトや設定が散らばって品質がばらつく、ワークフローが属人化して再現できない、ログや監査の取り方が決まらず本番に載せられない、といった理由で検証段階から先に進みにくくなることがあります。検証段階でも、開発(作る)と運用(回す)を分けて考え、後者の前提を早めに揃えておく方が手戻りを減らしやすいでしょう。
そこで本記事では、DifyをAIアプリケーションの実行基盤(プロンプト/ワークフロー/UI/運用管理の中核)として捉え、クラウドLLMとローカルLLMを用途に応じて使い分ける前提で全体像を整理します。特にローカル側については、コスト構造やデータガバナンスの見通しを立てやすい点を軸に、Difyでアプリケーション側を統一しながら運用する設計観点をまとめます。
【目次】
- Difyとは?ローカルLLM運用における役割と位置づけ
1-1. Difyが担う役割:LLMワークフローとフロントエンド
1-2. GPUが担う役割:LLMの実行基盤 - 自社環境にてDifyをローカル運用するメリット
2-1. コスト構造:従量課金から“自前GPUリソース”へのシフト
2-2. セキュリティ・データガバナンス:閉域環境での完結
2-3. ローカルLLMの選択およびチューニングの自由度
2-4. システム連携・拡張性:Difyワークフローと既存システムの統合 - Difyの運用段階を踏まえたローカルLLMのGPU・VRAM設計
3-1. VRAM消費の内訳と見積り - 利用シーン別の導入パターンの紹介
4-1. RAGを用いた社内ナレッジ検索
4-2. 規制業界・コンプライアンス重視環境でのクローズド運用
4-3. 研究・分析用途など、反復実行が前提となる利用シーン - まとめ
1. Difyとは?ローカルLLM運用における役割と位置づけ
Dify(ディフィー)とは、LLM(大規模言語モデル)を組み込んだアプリケーションを、継続的に構築・運用するための基盤となるソフトウェアです。チャットボットや社内向け検索システムなどを構築でき、作成したアプリケーションはAPIとして外部に公開することも可能です。そのため、業務アプリケーションや既存システムへ組み込みやすい点が特徴です。
なお、Dify自体がLLMの推論エンジンを内蔵しているわけではありません。あらかじめ設定したモデル提供元(クラウドAPIや自社運用の推論サーバ)を呼び出して、テキスト生成などを行う仕組みになっています。ローカルLLMを利用する場合は、Ollamaなどの推論実行環境を別途用意し、Difyから接続して運用します。
また、Difyでは、管理画面を通じてプロンプトや実行フローの定義、RAG(検索拡張生成:外部データを検索して回答精度を高める仕組み)、外部ツールとの連携などを設定できます。これらは本来、個別に実装・管理されがちな要素ですが、Difyでは一つの基盤に集約して扱うことができます。その結果、LLMアプリケーションを開発から検証、運用まで一貫して管理できる点が特長となっています。

重要なのは、Difyが単なる「LLMを呼び出すためのツール」ではないという点です。Difyは、ユーザーが利用する入口(UIやAPI)や処理フローの制御、運用管理を担うアプリケーション側の中核レイヤーとして設計されています。一方で、文章生成や推論処理を実際に行うLLMそのものは、クラウドLLMや自社GPU上のローカルLLMとして、別の実行基盤で動作します。つまり、Difyは「LLMをどのように使い、どのように運用するか」を管理する役割を担い、GPUやクラウド基盤は「LLMを実行する」役割を担います。
このあと、その役割分担について、DifyとGPUそれぞれの観点から詳しく説明します。
ローカルLLMについては次の記事もご覧ください。
【関連記事】
【前編】ローカルLLM導入のためのGPU環境~VRAMから考えるモデル選定と推論要件~|GPUならNTTPC|NVIDIAエリートパートナー
【後編】ローカルLLM導入のためのGPU環境~導入後の運用と環境構築~|GPUならNTTPC|NVIDIAエリートパートナー
1-1. Difyが担う役割:LLMワークフローとフロントエンド
Difyは、ローカルLLM運用基盤において、LLMを「どのように使い、どのように運用するか」を担うコンポーネントとして位置づけられます。
具体的には、次のような役割を担います。
- チャットUI・Webアプリ・APIなど、ユーザーや既存システムからのアクセス経路を提供
- RAG、ツール呼び出し、条件分岐などを組み合わせたLLMワークフロー/エージェントを実行
- 会話ログやフィードバック、アノテーションを記録し、運用データに基づく改善(品質のばらつき抑制・重要QAの固定化など)につなげる運用
このようにDifyは、LLM活用に必要な入口・ワークフロー・運用(ログ/評価/改善)を統合する中核レイヤーと捉えると理解しやすくなります。
1-2. GPUが担う役割:LLMの実行基盤
Difyは、LLMの推論処理そのものを実行する仕組みを内蔵しているわけではありません。文章生成や推論処理は、クラウドLLMや自社環境で動作するローカルLLMに委ねられます。この構成において、GPU環境はLLMを実際に動かすための計算リソース(推論実行基盤)の役割を担います。
具体的には、GPU環境上でローカルLLMを稼働させ、Difyからのリクエストに応じて文章生成や推論処理を実行します。Difyがアプリケーション側の制御や運用を担い、GPU環境が計算処理そのものを担当する、という役割分担になります。また、クラウドLLMではなく自社環境で処理を行う構成を取る場合、GPU環境はクラウドに代わるLLMの実行基盤として機能します。
この設計により、DifyにLLM活用を集約しつつ、LLMの実行先は用途に応じて切り替えるという構成が可能になります。
2. 自社環境にてDifyをローカル運用するメリット
ここでは、Difyを自社環境にセルフホストして運用する構成を前提に、推論基盤としてクラウドLLM(各社API)を利用する構成 と、自社GPU上でローカルLLMを運用する構成(推論サーバ) を比較し、それぞれの違いとローカル運用のメリットを整理します。比較にあたっては、コスト構造、データの取り扱い、運用の自由度といった観点から、どのような差が生じるのかを見ていきます。
なお、Difyにはクラウド上で利用する形と、自社環境に導入して運用する形(セルフホスト構成)がありますが、ここでは後者(セルフホスト構成)を前提とし、「推論先の違い」にフォーカスして比較を行います。
2-1. コスト構造:従量課金から“自前GPUリソース”へのシフト
主要なクラウドLLM APIでは、入力・出力トークン数に応じた従量課金モデルが一般的です。この方式は、初期検証や小規模な利用においてはコストを把握しやすい一方、利用量の増加に伴ってコストが比例的に増えやすいという特性があります。これに対し、自社GPUを用いたローカル運用では、LLM推論にかかるコストの重心が、クラウドのトークン課金から、GPU設備費や運用費を中心とした固定費構造へと移ります。初期投資や電力・保守といったコストは発生しますが、一定以上の利用量が継続的に見込まれる環境では、総コストを比較的安定して管理しやすくなります。
具体的には、バッチ処理や夜間ジョブなど、まとめて推論を実行するワークロードが多い場合や、短期的な検証ではなく長期的なLLM活用を前提とする場合には、自社GPU構成が現実的な選択肢となります。また、研究開発用途のように試行錯誤を繰り返す環境では、トークン数を都度気にせずに利用できる点も、自社GPU運用の利点といえるでしょう。
また、LLMを組み込んだアプリケーション開発では、開発・検証の途中でトークン使用量の上限やAPIのレート制限(同時実行数、リクエスト上限など)に達し、検証や負荷試験が計画どおり進まないケースもあります。自社GPU上のローカルLLMを推論先として運用する場合、外部サービスのクォータや利用上限に左右されにくく、必要なスループットは自社のGPUリソース(台数・VRAM・同時実行設計)でコントロールしやすい点もメリットです。
ただしローカル運用でも、ピーク時の同時実行やキュー制御、リソース監視などの運用設計は必要になります。
2-2. セキュリティ・データガバナンス:閉域環境での完結
規制対応が求められる業界や、機密情報を扱う組織では、「データを社外に出さない、もしくは外部送信を最小限に抑える」といった要件が設定されるケースがあります。
具体的には、機密データのクラウド送信自体がポリシー上禁止または厳しく制限されている、あるいは送信が許容されていても、ログの保持期間や監査要件、データ保持方針(保存可否・保存期間)が厳格に定められているといった状況です。
このような要件に対し、Difyをセルフホストし、推論先を自社環境のLLMエンドポイントに向ける設計を取ることで、プロンプトやコンテキスト、生成結果といったデータを社内環境内で完結させやすくなります。
推論に加え、埋め込み処理やベクタデータベース、ログ保管、外部ツール呼び出しなども含めて外部送信を行わない構成とすることで、閉域環境での運用が可能になります。
さらに、Difyが備えるログ管理やフィードバック収集の仕組みを活用することで、誰がどのようなプロンプトを送信したか、生成結果に対してどのような評価やフィードバックが行われたかといった情報を一元的に把握しやすくなります。
LLMの実行基盤を自社環境に置きつつ、利用履歴や評価データを体系的に管理できる点は、監査・コンプライアンス対応や内部統制の観点からも大きなメリットといえるでしょう。
2-3. ローカルLLMの選択およびチューニングの自由度
自社管理のLLM推論基盤を前提とすることで、要件や用途に応じたモデル選択やチューニング方針を柔軟に設計しやすくなります。具体的には、次のような選択肢が考えられます。
- Llama、Mistralなどのオープンモデルを、用途ごとに使い分ける
- RAGを組み合わせ、知識は文書・DB(ナレッジ)側で管理する
- 4bit/8bit量子化モデルを活用し、GPUあたりの実行効率を最大化する
これらは要件に応じて組み合わせて設計できます。運用面では、知識の更新や根拠管理をしやすいことからRAGを採るケースが多く、ファインチューニングはデータ整備や評価、更新手順まで含めて採否を判断します。
Difyは複数のモデルや推論プロバイダ設定に対応しているため、アプリケーション側の設計を大きく変えずに推論先を切り替えやすい点も特徴です。その結果、小規模モデルで検証を行い、効果が見えたユースケースのみ上位モデルへ移行する、といった段階的な品質・コスト調整も取りやすくなります。
2-4. システム連携・拡張性:Difyワークフローと既存システムの統合
Difyは、ワークフロー上で外部APIを呼び出すためのノード(例:HTTP Request)を備えており、既存システムとの連携を前提とした設計を取りやすい点が特徴です。LLMによる処理を単体で完結させるのではなく、ローカルLLMを業務システムの中で実際に活用するためのアプリケーション基盤として位置づけることができます。
たとえば、外部システムAPIからのデータ取得、チケットシステムへの登録・更新、メールやチャットツールへの通知といった処理を、Difyのワークフローに組み込むことができます。これにより、ローカルLLMによる判断・生成処理を、既存業務システムと結びつけた一連の処理フローとして定義できます。さらに、Difyを自社管理のLLM推論基盤と組み合わせることで、既存システムは基本的にそのまま活用しつつ、ローカルLLMの推論処理だけを業務フローに組み込む構成を取りやすくなります。利用者の入口としてDifyのUIやAPIを共通化し、その裏側でローカルLLMと既存システムを連携させる、といった役割分担が明確になります。
このように、Difyを既存システム群の上に配置することで、ローカルLLMを単なる実験用途にとどめず、実業務の中で活かすための「接着層(AIレイヤー)」として機能させられる点が、自社環境でDifyをローカル運用する大きなメリットといえるでしょう。
3. Difyの運用段階を踏まえたローカルLLMのGPU・VRAM設計
ローカルLLM運用では、「どのモデルを利用するか」と同じくらい、「どのクラスのGPU/VRAMを前提に設計するか」が重要になります。
特に Dify のように、モデルや推論先を切り替えながら運用できる基盤 を前提とする場合、初期段階でGPU・VRAM設計の考え方を整理しておくことが、検証から本番環境への移行をスムーズに進めるうえで有効です。
事前に見積りを行わずに進めると、VRAM不足でモデルが読み込めない、応答が遅くなる、同時実行数を確保できないといった問題が起きやすくなります。逆に、必要以上に余裕を取りすぎるとコストが膨らみやすいため、利用するモデル規模や想定ユースケースに基づいて「どの程度のVRAMが必要か」の当たりを付けることが大切です。
その前提になるのが、LLMが学習によって獲得した知識を保持する学習済みパラメータ(重み)です。推論時には、この重みをGPUメモリ(VRAM)上に展開して計算します。したがって、モデルのパラメータ数(B単位)と演算精度(FP16/INT4など)から、まず重みが占めるメモリ量を概算できると、GPU/VRAM設計の出発点が作れます。一方で、推論時には重み以外にも、コンテキスト長や同時実行数に応じて増えるKVキャッシュ、推論サーバやライブラリが占有するオーバーヘッドが加算されます。重みサイズはあくまで「最初の当たり」を付ける指標として捉え、最終的には想定ユースケース(コンテキスト長・同時実行数・応答目標など)と合わせて余裕(マージン)を見込んで設計します。
ここでは、特定モデルのベンチマーク値ではなく、パラメータ数(B単位)と演算精度(FP16/INT4 など)から重みサイズを概算するという考え方をベースに、ローカルLLM運用におけるVRAM容量の目安を整理します。
3-1. VRAM消費の内訳と見積り
ローカルLLM運用においてGPUに必要なVRAMは、単に「モデルのサイズ」だけで決まるものではありません。実務では、推論時に消費されるVRAMを構成要素ごとに分解して考えることが一般的です。
LLM推論時にGPUが消費するVRAMは、主に次の3要素から構成されます。
- モデル重み(weights):学習済みパラメータそのもの
- KVキャッシュ:コンテキスト長や同時実行数に応じて増加する中間データ
- フレームワークのオーバーヘッド:推論サーバやライブラリが占有するVRAM
このうち、モデル重みはパラメータ数と演算精度から比較的シンプルに概算でき、代表的な目安は次の通りです。
- FP16 (非量子化・半精度浮動小数点)の場合
パラメータ数 × 2 byte ≒ 重みサイズ - INT4(4bit量子化)の場合
パラメータ数 × 0.5 byte ≒ 重みサイズ
例えば、7〜8B級モデル(約70〜80億パラメータ)では、重みサイズは概ね次のレンジになります。
- FP16:約 13〜15GB
- INT4:約 3.3〜3.8GB
この重みサイズの算出は、GPUクラスやVRAM容量の当たりを付けるための初期指標として有効ですが、実運用ではここにKVキャッシュやフレームワークのオーバーヘッドが加算されます。重みサイズの概算によって「単一GPUで検討できるか」「量子化や構成の工夫が前提になるか」といった方向性を整理したうえで、必要VRAMはコンテキスト長や同時実行数、推論サーバの構成などを踏まえて見積もります。
vRAM使用量については、ここまでのようにパラメータ数から個別に算出することも可能ですが、より手軽に概算値を確認できるツールも公開されています。
Model Memory Estimator は、 Hugging Face Hub 上のモデルを対象に、safetensors のメタデータをもとにGPUメモリ使用量を自動算出するツールです。
モデル名(またはURL)を入力するだけで、推論時・学習時のおおよそのvRAM使用量を確認できます。
下図は、例として bert-base-cased を入力した際の結果画面です。
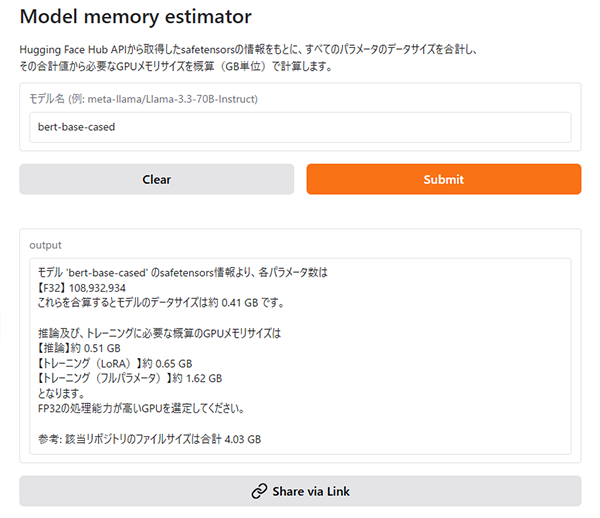
GPU選定やモデル検討の初期段階における目安確認として有用です。
ツールは次のURLから利用できます。
https://huggingface.co/spaces/yasu-oh/model_memory_estimator
なお、PoCで実測できる場合はその結果を最終判断に反映できますが、PoCが難しいケースも少なくありません。その場合は、想定ユースケース(同時実行数・応答時間の目標・運用時間帯)を先に整理し、オーバーヘッド分を含めて一定の余裕(マージン)を見込んだGPU/VRAM構成で必要スペックを活用するという形が現実的です。
また、Difyを利用する場合では、「どのモデルを、どの推論サーバで動かすか」を設定によって柔軟に切り替えられるため、インフラ設計も段階的に進めやすくなります。まずは比較的扱いやすい規模(例:3〜8B級や13〜30B級)から実測し、Difyの設定を切り替えながら性能・コスト感を比較します。その結果を踏まえて、要件に応じて30B級以上への拡張や、複数GPU構成/大容量VRAMの単体GPUを含む構成を検討していくと手戻りが少なく進めやすいでしょう。
このように、VRAM設計を固定値で決め打ちせず、検証と段階的な拡張を前提に設計できる点は、Difyを前提としたローカルLLM運用における利点といえます。
4. 利用シーン別の導入パターンの紹介
Dify×自社GPU構成では、「どの業務で、どのデータを、どこまで社内で完結させるか」によって、適切な設計が変わります。すべてを同じ構成で進めるのではなく、利用シーンに応じて前提条件や重視すべきポイントを整理することが重要です。ここでは代表的な利用シーンを3つに分け、RAGの有無、権限・監査要件、バッチ処理の比率といった観点から、構成の考え方を整理します。
4-1. RAGを用いた社内ナレッジ検索
社内に分散して存在する情報を横断的に参照しながら回答を得たい、というニーズは多くの組織で見られます。たとえば、社内Wiki、各種規程・ガイドライン、業務マニュアル、過去の議事録などを参照しながら、担当者が日常業務の中で疑問点を確認したい、といったケースです。このような場面では、対象となる社内文書をナレッジベースとして取り込み、RAGを用いて関連情報を検索したうえで、LLMに回答を生成させる構成が有効です。Difyは、この一連の流れを業務アプリケーションとして定義・運用する役割を担います。具体的には、利用者の入口となるチャットUIやAPIを提供し、検索処理とLLM推論を組み合わせたワークフローを管理します。
推論処理については、クラウドLLM(OpenAI API/Azure OpenAI Service などの各社提供のマネージドLLM API)を用いる構成も考えられますが、社内規程や契約情報など、外部に送信できない情報を扱う場合には、ローカルLLMを自社GPU環境で稼働させ、処理を社内環境内で完結させる設計が適しています。Difyは、こうしたローカルLLMを推論先として組み込み、業務フローの中で利用できるようにするための接点として機能します。
4-2. 規制業界・コンプライアンス重視環境でのクローズド運用
金融・医療・公共分野などの規制業界では、LLMの活用にあたり、データの取り扱いに関する厳格な要件が求められるケースがあります。具体的には、外部クラウドへのデータ送信の禁止や制限、データ保存範囲や委託先に関するポリシー、ログの保管期間や監査対応、ユーザーや権限ごとのアクセス制御といった点が論点となります。
このような環境では、Difyをセルフホストし、推論先を自社GPU上のローカルLLMに向けることで、プロンプト、コンテキスト、生成結果といったデータを社内環境内で完結させる構成を取りやすくなります。LLMを業務で活用しつつも、データの外部流出リスクを抑えた設計が可能です。
認証や監査要件が強い場合には、組織のセキュリティ方針に応じて、SSO連携やアクセス制御、ログの取得・保全方法まで含めて周辺構成を設計しておく必要があります。
たとえば、前段にリバースプロキシやIdP連携を配置し、認証・アクセス制御やログ管理を周辺構成として実装する、といった整理が現実的です。
また、すべての処理をローカルLLMに限定するのではなく、「外部送信が許容されるデータはクラウドLLM」「センシティブな情報を含む処理はローカルLLM」というように、Difyをフロントとして推論先を使い分ける設計も現実的な選択肢です。このように、コンプライアンス要件を満たしながら段階的にLLM活用を進められる点も、Difyを中核とした構成の特徴といえるでしょう。
4-3. 研究・分析用途など、反復実行が前提となる利用シーン
Dify×自社GPU構成が有効に機能しやすい利用シーンの一つが、同様の処理を継続的・反復的に実行する研究・分析用途です。たとえば、大量のログや実験データを対象とした要約・分類処理を定期的に実行するケースや、条件やパラメータを変えながら仮説検証を行い、レポート生成を継続的に行うケースが挙げられます。また、同一の処理フローを長期間にわたって運用し、結果を比較・蓄積していくような利用形態も想定されます。
このような用途では、DifyのRAG(ナレッジ)機能を併用し、過去の実験結果・手順書・評価メモ・既存レポートなどを参照しながら処理できる点もメリットになります。ナレッジを更新すれば参照内容も追従しやすいため、「前回と同じ前提で回せているか」「根拠がどこか」といった再現性・説明性を確保しやすくなります。
また、クラウドLLMの従量課金モデルでは、利用回数や処理量の増加がコスト面の制約となる場合があります。一定の処理量が継続的に見込まれる環境では、自社GPUを用いたローカルLLM運用が、コスト管理の観点から現実的な選択肢となります。さらに、Difyにワークフローを集約することで、処理手順や前提条件を明確に管理しやすくなります。
これらにより、実行結果の再現性を確保しつつ、処理の標準化や長期的な安定運用につなげやすくなる点も、研究・分析用途における実務上のメリットといえるでしょう。
このような用途では、クラウドLLMの従量課金モデルにおいて、利用回数や処理量の増加がコスト面の制約となる場合があります。一定の処理量が継続的に見込まれる環境では、自社GPUを用いたローカルLLM運用が、コスト管理の観点から現実的な選択肢となります。さらに、Difyにワークフローを集約することで、処理手順や前提条件を明確に管理しやすくなります。これにより、実行結果の再現性を確保しつつ、処理の標準化や長期的な安定運用につなげやすくなる点も、研究・分析用途における実務上のメリットといえるでしょう。
5. まとめ
本記事では、Difyをアプリケーション/運用の中核に据え、クラウドLLMと自社GPU上のローカルLLMを用途に応じて使い分ける運用基盤について、その考え方と全体像を整理しました。Difyは、RAGやエージェント、文書生成といったLLM活用に必要なワークフローと運用を集約できる基盤です。推論先がクラウドLLMであってもローカルLLMであっても、アプリケーション側を共通化して利用できる点が特徴です。一方で、自社GPUを活用することで、コスト管理、データガバナンス、モデル選択やチューニングの自由度といった観点において、クラウドのみの構成では得にくい選択肢が生まれます。
また、小規模導入から部門利用、全社基盤へと段階的にスケールさせる前提で設計することで、初期投資や運用負荷を抑えつつ、将来的な拡張にも対応しやすくなります。特に、RAGによる社内ナレッジ検索、規制・コンプライアンス要件が求められる環境、研究・分析用途のように反復実行が前提となるケースでは、Dify×自社GPU構成が有効な選択肢となるでしょう。
DifyのようなLLMアプリケーション基盤は、推論そのものではなく、「ワークフローと運用」を支える中核レイヤーです。実運用においては、推論サーバ(GPU)、RAG(ベクタDB/埋め込み)、ログ設計に加え、電力・冷却・ネットワークまで含めた基盤側がボトルネックになりやすく、要件に応じた構成整理が重要になります。オンプレミスGPUや国内データセンターでの専有型構成(GPUプライベートクラウド)、必要に応じたGPUクラウドの活用など、ローカルLLM運用に適したGPU実行基盤の検討については、NTTPCまでお気軽にご相談ください。
▶︎ お問い合わせはこちら
※「Dify」はDify.AI(LangGenius, Inc.)の商標または登録商標です。
※「Llama」はMeta Platforms, Inc.の商標または登録商標です。
※「Mistral AI」は Mistral AI SASの商標または登録商標です。
※Microsoft、Azure は、Microsoft Corporation の商標または登録商標です。
※OpenAI、は OpenAI の商標または登録商標です。
※Amazon Bedrockは、Amazon.com, Inc.の商標または登録商標です。