



基礎知識
LLM推論の高速化ツール:vLLM・TensorRT-LLM・TGIの比較
2026.04.24

GPUエンジニア

LLM(大規模言語モデル)の活用が広がる中、チャットボットやAIエージェントとして実サービスに組み込む企業も増えています。しかし、実際に運用を始めると課題になりやすいのが応答速度です。ユーザー数が増えると、推論処理の計算負荷や同時接続の増加によってスループット(単位時間あたりの処理量)が低下し、レスポンス遅延が発生することがあります。こうした問題に対しては、単純にGPUメモリを増やすだけでは解決しない場合も少なくありません。近年では、LLMの推論処理そのものを最適化することで高速化を図るアプローチが広く採用されており、その代表的なツールとして vLLM、TensorRT-LLM、Text Generation Inference(TGI) などの推論エンジンが利用されています。
本記事では、まずLLMの推論構造を整理したうえで、推論ライブラリやサービングエンジンとして利用される vLLM・TensorRT-LLM・TGI の特徴と違いを比較し、実運用での選定ポイントを整理します。
【目次】
- LLMの推論とは?その仕組みと高速化のボトルネック
1-1. LLMの推論処理の仕組み:Prefill と Decode の2構造
1-2. LLMの推論に影響する3つのボトルネック - vLLM・TensorRT-LLM・TGIの全体像と特徴
2-1. TensorRT-LLM:NVIDIA GPUの性能を最大限引き出す推論ライブラリ
2-2. vLLM:メモリの効率と高スループットを重視した汎用LLMサービング基盤
2-3. TGI:Hugging Faceエコシステムとの統合を重視したサービングツールキット - ツールの選定ポイント
3-1. 新規構築か既存資産を活用するかの違い
3-2. 法人利用における考慮点 - ベンチマーク設計:TTFTとtokens/sをどう測り、どう比較するか
4-1. 代表的な評価指標と測定上の注意点 - まとめ
1. LLMの推論とは?その仕組みと高速化のボトルネック

AIにより作成(プロンプト:データの粒子が砂時計の中を流れる、ボトルネックのイメージ)
LLMの推論とは、ユーザーからの入力を受け取り、学習済みの大規模言語モデルが次に生成すべきトークンを計算しながら応答文を生成していく処理のことを指します。チャットボットやAIエージェントでは、この推論処理がユーザーのリクエストごとに実行され、生成されたテキストがレスポンスとして返されます。LLMの推論を高速化するとは、この入力から応答生成までの処理時間を短縮するとともに、同時に多数のリクエストを処理できるようにすることを意味します。特に実サービスでは、単一リクエストの応答速度だけでなく、同時接続が増えたときのスループット(単位時間あたりの処理量)も重要な指標になります。
この推論速度の基礎となるのはGPUの性能です。GPUの演算性能、メモリ容量、メモリ帯域は、LLM推論の基本的な処理能力を決定します。しかし、性能の高いGPUを導入しただけで問題が解決するとは限りません。特に同時接続数が増えると、GPUメモリをどのように管理するか、複数のリクエストをどのようにバッチ処理するかによって、実際のスループットが大きく変わります。そのため、実サービスではGPUの性能だけでなく、推論処理を効率的に運用する仕組み(モデルサービング)が重要になります。
ここでは、LLM高速化を実現するためのアプローチとして、モデルサービングを効率化するツールの観点から解説します。GPUの性能指標や世代ごとの性能比較については、こちらの記事で詳しく整理しています。ぜひあわせてご参照ください。
【関連記事】
データセンターGPU性能比較:指標別に見る製品の選定ポイント
1-1. LLMの推論処理の仕組み:Prefill と Decode の2構造
LLM推論のボトルネックを理解するために、まず推論処理の基本的な構造を見ていきます。LLMの推論処理は、大きく Prefill と Decode の2つのフェーズに分かれています。
Prefillとは
ユーザーの入力(プロンプト)全体を一度にモデルに入力し、各層の Key / Value(KV) を計算してキャッシュ(KVキャッシュ)を構築するフェーズです。この処理では大きな行列計算が中心となるため、GPUの高い並列演算能力やメモリ帯域を効率的に活用しやすい特徴があります。ただし、入力トークン数が長くなるほど計算量が増えるため、長いプロンプトほど Prefillの負荷が大きくなる傾向があります。
例えば、数ページ分の資料を丸ごと貼り付けて「この内容を要約してください」と指示した場合、その長い入力を最初にまとめて読み込む部分が Prefill にあたります。
Decodeとは
Prefillで作成した KVキャッシュ を参照しながら、次のトークンを 1つずつ生成していくフェーズです。1ステップあたりの計算量は小さいものの、この処理を生成トークン数分だけ繰り返す必要があります。そのため、処理全体ではメモリ上のKVキャッシュの参照回数が多くなり、演算性能よりも、メモリアクセス量や帯域の影響を受けやすい特徴があります。特に、同時リクエスト数(同時接続数)や生成する文章の長さが増えるほど、GPUのメモリ帯域がボトルネックとなり、Decode性能が低下しやすいという特徴があります。
例えば、先ほどの資料の要約結果や回答文が画面上に少しずつ表示されていくとき、その要約文を1語ずつ生成している部分が Decode にあたります。
このように、LLMの推論処理は PrefillとDecodeという性質の異なるフェーズから構成されているため、どちらがボトルネックになるかによって最適化の方針も変わります。
同時接続数が増える環境では、Prefill と Decode を分離して処理を分散する「分散LLM推論」が有効になります。詳しくはこちらの記事で解説しています。
【関連記事】
LLM分散推論サービス入門ガイド ~分散LLM推論基盤を構築・理解するためのステップ~|GPUサーバープラットフォームの設計/構築なら「技術力」のNTTPC
ここでは、これら2つのフェーズを踏まえたうえで、LLM推論における代表的なボトルネック要素を整理します。
1-2. LLMの推論に影響する3つのボトルネック
LLMの推論処理では、PrefillとDecodeという2つのフェーズが存在するため、一般的なGPU計算(例えば、バッチ処理型のGPUワークロードなど)とは異なるボトルネックが発生します。特に実サービスでは、次の3つの要素が性能を左右しやすく、同じGPUを使用していてもこれらの扱い方によって推論性能が大きく変わることがあります。
KVキャッシュのメモリ管理
LLMの推論では、Attention計算*1で使用するKVキャッシュがGPUメモリを大きく消費するため、同時に処理できるリクエスト数の制限につながります。特にコンテキスト長が長い場合、KVキャッシュがメモリを占有し、スループットの低下を招きます。
また、Decodeフェーズではトークン生成のたびに全トークン分のKVキャッシュを参照するため、計算処理よりもメモリアクセスの影響を受けやすくなります。その結果、コンテキスト長が長くなるほどメモリ帯域がボトルネックとなり、推論性能に影響を与えます。
*1 Attention計算:文章を読むときに、「この単語を理解するには、文中のどの単語をどれくらい重視すればよいか」を判断する処理です。例えば「彼は昨日それを買った」という文では、「彼」や「それ」が何を指しているかは、他の単語との関係を見ないと分かりません。
LLMは Attention によって、こうした単語間の関係性を捉え、文脈を理解します。
バッチ処理の効率
LLMの推論では、バッチ処理の効率がGPU利用率を左右する重要な要素になります。バッチングとは、複数のリクエストをまとめて処理することでGPUの並列演算性能を引き出す手法です。PrefillとDecodeの両方のフェーズで利用されますが、特にDecodeフェーズで問題が顕在化しやすくなります。従来の静的バッチングでは、一定時間リクエストを溜めてから一括処理します。しかしDecodeフェーズでは、リクエストごとに出力長が異なるため、生成が早く終わったリクエストがバッチに残り続けると、その分GPUの利用率が低下します。
演算カーネルの最適化
LLMの推論では、GPUカーネルの実装によって処理性能が大きく変わるという特徴があります。カーネルとは、GPU上で実行される計算処理の単位であり、GPUに特定の計算を実行させる小さなプログラムのことです。
LLM推論では、Attention(入力間の関連度を計算する処理)やMLP(Multi-Layer Perceptron:全結合層)といった計算量の多い処理が、PrefillとDecodeの両方のフェーズで実行されます。Prefillフェーズでは入力全体を一度に処理するため、計算効率の差は1回の処理に現れます。一方、Decodeフェーズでは1トークンずつの生成を何百回と繰り返すため、計算を効率よくまとめて実行できるカーネル実装の違いによる性能差が積み重なり、大きな処理時間の差につながることがあります。
このように、LLM推論ではKVキャッシュ管理やバッチングなど、いくつかの要素が性能に大きく影響します。これらの処理を適切に制御しながら、推論を効率よく処理する仕組み全体を一般にモデルサービングと呼びます。次の章では、モデルサービングの代表的なツールである vLLM・TensorRT-LLM・TGI の特徴と使い分けを見ていきます。
2. vLLM・TensorRT-LLM・TGIの全体像と特徴
まず、3つのツールを比較する前提として、これらは役割のレイヤーが異なる点を押さえておくことが重要です。
LLM推論の基盤は、大きく推論ライブラリとサービング基盤の2つのレイヤーに分けて考えることができます。推論ライブラリは、GPU上でモデルの計算を高速に実行するためのソフトウェアです。主に演算カーネルの最適化やメモリ管理などを担当し、モデルの推論処理そのものを高速化します。APIサーバやリクエスト管理の機能は持たないことが多く、通常は他のサービング基盤と組み合わせて利用されます。一方、サービング基盤は、学習済みモデルを本番環境で動かし、ユーザーからのリクエストを受けて推論結果を返すためのシステムです。APIサーバ、リクエスト管理、バッチ処理、レスポンス返却など、サービスとしてモデルを提供するための機能をまとめて提供します。
TensorRT-LLMは推論ライブラリにあたり、vLLMやTGIはサービング基盤として利用されることが多いツールです。また、サービング基盤の内部でTensorRT-LLMを推論エンジンとして利用する構成も存在します。
こうしたレイヤーの違いを踏まえたうえで、次に3つのツールの特徴を整理します。
| ツール | レイヤー | 重視する点 | 適した環境 |
|---|---|---|---|
| TensorRT-LLM | 推論ライブラリ | 単体GPUの性能最大化 | NVIDIA GPU環境で性能を最大限引き出す場合 |
| vLLM | サービング基盤 | メモリ効率と高スループット | 自社LLM APIを構築する場合など |
| TGI | サービング基盤 | Hugging Faceエコシステム連携 | Hugging Faceモデルとクラウドネイティブ運用を前提とする場合など |
vLLM、TGI、TensorRT-LLMは同じ「LLM推論を高速化するツール」として紹介されることが多いですが、実際には役割のレイヤーが少し異なります。上記の表のように、vLLMとTGIは、推論リクエストの管理やバッチ処理などを担うモデルサービング基盤に近い位置づけで、複数リクエストを効率よく処理する仕組みを提供します。一方、TensorRT-LLMはGPU上での推論計算を高速化するための推論ライブラリにあたり、カーネル最適化やモデル最適化により推論性能を向上させます。
そのため、これら3つは完全に排他的な選択肢ではありません。例えば、TGIの内部でTensorRT-LLMを推論エンジンとして利用する構成も存在します。このようにツールの役割が異なるため、比較する際には「どのレイヤーの機能を比較しているのか」を意識することで、混乱を避けることができます。
ここでは、それぞれのツールのアーキテクチャの特徴と、適したGPU構成を整理します
2-1. TensorRT-LLM:NVIDIA GPUの性能を最大限引き出す推論ライブラリ
TensorRT™-LLM は、NVIDIA®が自社GPU向けに提供するLLMの推論ライブラリです。vLLMやTGIがAPIサーバやリクエスト管理を含む「サービング基盤」であるのに対し、TensorRT-LLMはモデルの推論実行そのものを最適化する「ライブラリ」として位置づけられます。
主な特徴
- NVIDIA GPUへの最適化:カスタムカーネル、カーネル融合、Hopper・Blackwell世代をはじめとするNVIDIA Tensor Core GPUを活用
- 多様な低精度演算対応:FP8・FP4・INT8・INT4による計算効率化
- 効率的なメモリ管理:paged KV cache、in-flight batching(連続バッチング)をサポート
- 推論基盤との統合:Triton Inference Serverと組み合わせた本番運用
適した環境
NVIDIA GPUの性能を最大限に活用したい場合に有力です。特にBlackwell世代(B200/B300等)のGPUでは、低精度演算を活用した最適化の効果が大きくなります。
導入時の考慮点
- モデル変換やビルドプロセスに手間を要する
- 利用可能な精度や最適化内容はモデル構造やGPUアーキテクチャに依存する
TensorRTの仕組みやLLM以外も含めた推論最適化の全体像は、こちらの記事でも整理しています。ぜひご参照ください。
【関連記事】
TensorRTとは?"AIが遅い"を解決する、NVIDIAの頭脳チューナー
2-2. vLLM:メモリの効率と高スループットを重視した汎用LLMサービング基盤

vLLM は、KVキャッシュのメモリ効率と連続バッチングによるスループット向上を重視したLLMサービングエンジンです。
主な特徴
- Paged KV Cacheの先駆的実装:PagedAttention論文で提案された手法を実装し、KVキャッシュのメモリ断片化を抑制する仕組みを提供
- 連続バッチング:生成完了したリクエストを即座にバッチから除外し、GPU利用率を高く維持
- 幅広いGPU対応:NVIDIA、AMD、Intellにも対応しており、汎用性が高い
適した環境
単一GPUからマルチGPU環境まで、限られたリソースで高いスループットを求めるLLM推論基盤に適しています。特に、自社でLLM APIを構築する用途において、効率的なバッチ処理やKVキャッシュ管理により性能を引き出しやすい特徴があります。
導入時の考慮点
- 比較的容易に導入可能で、Dockerコンテナでの運用も可能
- OpenAI互換APIにより既存アプリケーションとの統合が容易
2-3. TGI:Hugging Faceエコシステムとの統合を重視したサービングツールキット
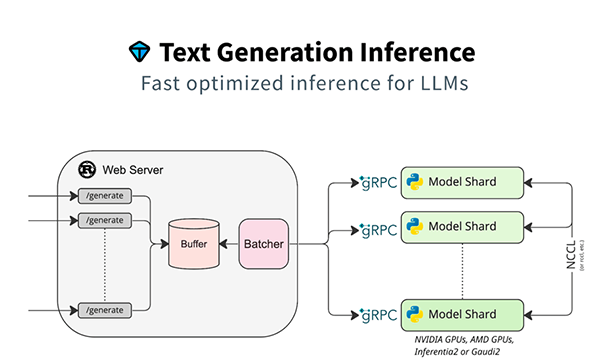
Text Generation Inference(TGI) は、Hugging Faceエコシステムとの統合を重視したLLMサービング用のツールキットです。
主な特徴
- Hugging Face連携:Llama系やStarCoder系など、Hugging Face Hub上の主要モデルに対応
- クラウドネイティブ:公式Dockerコンテナイメージによる、Kubernetes(k8s)環境への容易な導入
- マルチバックエンド対応:推論エンジンとしてTensorRT-LLMを組み合わせる構成も公式サポート
適した環境
Hugging Faceエコシステムとクラウドネイティブ運用を前提とする場合に適しています。
導入時の考慮点
メンテナンスモードへの移行:2025年12月に公式リポジトリでメンテナンスモードへの移行が明記されました。今後は軽微な修正が中心となり、移行先としてvLLMやSGLangが案内されています。
- 新規構築の場合:vLLMを主軸に検討
- 既存資産がある場合:Hugging Face・TGI運用資産を活かしてTGIの継続利用を検討
3. ツールの選定ポイント
ツールの選定にあたっては、前章で整理したレイヤーの違いを踏まえたうえで、性能要件・運用要件・既存資産の有無等を総合的に判断します。主な例を示しながら選定の方法をご紹介します。
※代表的な例であり、環境や条件により判断は変わることがあります。
3-1. 新規構築か既存資産を活用するかの違い
LLM推論基盤のツール選定では、新規に構築するのか、既存の運用基盤を活用するのかによって判断が変わります。新規構築の場合、開発・検証フェーズでは vLLMを軸に検討するケースが多く見られます。vLLMはDockerで容易に導入でき、OpenAI互換APIを提供しているため既存アプリケーションとの統合も比較的容易です。また、幅広いGPU世代に対応しており、開発コミュニティも活発です。そのまま性能要件を満たせる場合は、vLLMを本番環境でも継続して利用することができます。
加えて、より高い推論性能が求められる場合は、TensorRT-LLMを推論エンジンとして採用し、Triton Inference Serverと組み合わせる構成も選択肢になります。特にNVIDIA GPU環境が前提で、リアルタイム応答や高スループットが求められる用途では、この構成が候補になります。
一方で、Hugging Face / TGI を中心とした運用基盤がある場合は、TGIを継続利用する選択肢もあります。既存の運用ノウハウやシステム構成を活かせるため、短期的には移行コストを抑えられるメリットがあります。ただし、TGIは2025年12月にメンテナンスモードへ移行しているため、中長期的には vLLMなどへの移行を検討するケースも多くなります。なお、TGIは推論エンジンとしてTensorRT-LLMを組み込む構成にも対応しており、既存基盤を維持したまま性能を向上させることも可能です。
3-2. 法人利用における考慮点
法人が本番環境で利用する場合、技術的な性能以外にも考慮すべき点があります。
- ライセンス:vLLM、TensorRT-LLM、TGIはいずれもApache 2.0ライセンスで提供されており、商用利用に制限はありません。
- サポート体制:TensorRT-LLMはNVIDIA公式のドキュメントとサポートが提供されています。vLLMはオープンソースプロジェクトですが、活発なコミュニティとGitHub Issuesでのサポートがあります。商用サポートが必要な場合は、NVIDIA AI Enterprise(TensorRT-LLMを含む)や、vLLMを商用サポート付きで提供するベンダーを利用できます。
- GPU世代への対応:TensorRT-LLMはNVIDIA GPU向けに最適化されており、Hopper・Blackwell世代などのアーキテクチャの機能を活用できます。vLLMとTGIは幅広いNVIDIA GPU世代に対応しており、既存のGPU資産を活かしながら段階的に最新世代へ移行できます。
このように、LLM推論基盤の選定では単純な性能比較だけでなく、運用体制、既存GPU資産、将来の拡張性を含めて総合的に判断することが重要です。
4. ベンチマーク設計:TTFTとtokens/sをどう測り、どう比較するか

AIにより作成(プロンプト:複数の光るバーチャートが空間に浮かぶ)
LLMの推論を高速化する手法やツールの選定を理解したうえで、最後に重要になるのが、実際にその効果をどのように評価するかが重要になります。このセクションでは、LLM推論の代表的な性能指標である TTFT(Time To First Token) と tokens/s(トークン生成スループット) の測定方法と、その結果の読み取り方を解説します。
4-1. 代表的な評価指標と測定上の注意点
LLMの推論性能を評価する際は、次の指標を測定します。それぞれの指標から分かることを整理しています。
| 指標 | 測定内容 | 何が分かるか | 重要なユースケース |
|---|---|---|---|
| TTFT(Time To First Token) | 最初のトークンが返されるまでの時間 | ユーザーが応答を体感するまでの待ち時間。Prefillフェーズの効率とキュー待ち時間を反映 | チャットボット、コーディング支援など、レスポンスの速さが重要な用途 |
| tokens/s(トークン生成スループット) | 単位時間あたりのトークン生成数 | 長文生成やバッチ処理の効率。Decodeフェーズの性能を反映 | 長文生成、バッチ翻訳、ログ要約など、大量のトークンを処理する用途 |
| GPU利用率 | GPUの演算リソースがどれだけ使われているか | バッチングや並列化の効率が判定可能。 | 同時接続数が多い環境で、GPUを効率的に使えているかの確認 |
| メモリ使用量 | VRAMの消費量 | KVキャッシュ管理の効率。メモリ使用量が高いと同時処理数が制限されやすい | 長いコンテキストや多数の同時接続を扱う場合に容量を確認 |
上記のような指標を自社のGPU環境で取得する場合は、同じリクエスト条件で推論を実行し、TTFTやtokens/sをログから計測します。これに加えて、GPU利用率やメモリ使用量を監視ツール(例:nvidia-smiや各サービングツールのメトリクス)で確認することで、推論処理のどの部分がボトルネックになっているのかを把握できます。
ツール間で性能を比較する場合は、ベンチマーク条件をできるだけ統一することも重要です。特に次の条件は結果に大きく影響するため、同一条件で測定する必要があります。
- モデルと重み(量子化条件を含む)
- GPUの構成(世代・メモリ容量)
- バッチ条件(入力長・出力長・同時接続数)
- ストレージやネットワークがボトルネックになっていないこと
これらの条件を揃えたうえで、TTFT・tokens/s・GPU利用率・メモリ使用量を総合的に評価することで、現在の構成でどこが性能の制約になっているのか、またGPU増設やツール変更などの最適化が必要かを判断できるようになるでしょう。
5. まとめ
本記事では、LLMの推論高速化におけるボトルネックの構造と、vLLM・TensorRT-LLM・TGIという3つの主要ツールの特徴、そしてユースケース別の構成検討のポイントを解説しました。LLM推論の性能はGPUの演算性能やメモリ帯域といったハードウェア性能を土台とし、その上でモデルサービングの実装がKVキャッシュ管理、バッチング、カーネル最適化などのボトルネックに対応することで大きく左右されます。vLLMは汎用的なサービングエンジンとして数枚規模のGPU環境で有力な選択肢となり、TensorRT-LLMは最新世代GPUの性能を最大限に引き出す推論ライブラリとして利用されます。また、TGIは既存のHugging Face運用基盤がある環境で継続利用する選択肢として位置づけられます。
ツール選定は、自社のユースケースとGPU環境の組み合わせによって決まります。ベンチマークによって現状の性能を測定し、ボトルネックを特定したうえで、段階的に構成を最適化していくことが重要です。
NTTPCでは、LLMの推論高速化に適したGPUサーバーをはじめ、AI・HPCワークロード向けのインフラ環境を提供しています。ツールの選定やGPUの構成に関するご相談等、お気軽にお問い合わせください。
▶︎ お問い合わせはこちら
※「vLLM」 は vLLM Project の商標または登録商標です。
※「NVIDIA」、「TensorRT-LLM」、「Hopper」、「Blackwell」は、NVIDIA Corporation(NVIDIA社)の商標または登録商標です。
※「Llama」は、Meta Platforms, Inc. の登録商標、または商標です。