



基礎知識
マルチGPU環境構築の鍵!NVLinkとNVSwitchが実現する超高速データ伝送とは
2026.01.29

GPUエンジニア

大規模言語モデル(LLM)や複雑なAIワークロードの急速な拡大により、単一のGPUでは処理しきれない計算負荷が現実のものとなっています。この課題に対応するため、複数のGPUを連携させて計算能力を向上させる「マルチGPU」環境が不可欠となりました。しかし、そこには新たな壁が存在します。それは、GPU間のデータ転送速度です。
従来のPCIeバスでは、巨大なモデルパラメーターやデータをGPU間で共有する際に深刻なボトルネックとなり、GPU本来の性能を十分に引き出せませんでした。この問題を解決し、マルチGPU環境のポテンシャルを最大限に解放する核心技術が、NVIDIA® NVLink®とNVSwitch®です。
本記事では、GPU間を直結する超高速インターコネクトNVLinkと、それを大規模に拡張するNVSwitchの基本概念から技術的特徴、そして具体的な活用シーンや導入のポイントまでを包括的に解説します。
目次:
- NVLinkとNVSwitchとは?マルチGPU環境の核心技術
1-1. マルチGPU環境の必要性 - NVLink:GPU間を直結する高速インターコネクト技術
2-1. NVLinkの基本アーキテクチャーと特徴
2-2. NVLinkによるメモリ統合機能 - NVSwitch:NVLinkを大規模に拡張するスイッチ技術
3-1. NVSwitchの役割とAll-to-All接続の実現
3-2. NVSwitchのノンブロッキング設計:並列処理にもたらす効果 - NVLinkおよびNVSwitchがもたらす性能インパクト
4-1. 世代ごとの圧倒的な帯域幅の進化
4-2. NVSwitchによる通信オーバーヘッドの削減
4-3. 大規模言語モデルにおける推論スループットの向上 - NVLink/NVSwitchを搭載した代表的なシステム
5-1. DGX Spark:小規模AI開発に最適なコンパクトAIスーパーPC
5-2. DGX Station:デスクトップ最上位パーソナルAIスーパーコンピューター
5-3. DGX H100:エンタープライズAIの主力システム
5-4. GB200 NVL72:ラックスケールで動作するAIスーパーコンピューター
5-5. 用途に応じたシステム選択のポイント - まとめ
1. NVLinkとNVSwitchとは?マルチGPU環境の核心技術
大規模なAI開発に不可欠となったマルチGPU環境。しかし、その性能を最大限に引き出すには、GPU同士を繋ぐ「道路」の性能が鍵となります。このGPU間の通信ボトルネックを解消するためにNVIDIAによって開発された革新技術が、NVLink(エヌブイリンク)とNVSwitch(エヌブイスイッチ)です。
1-1. マルチGPU環境の必要性
AIモデルの巨大化やHPC(高性能計算)の高度化により、1枚のGPUだけでは処理が追いつかないケースが急増しています。こうした状況では、複数GPUで計算を分担する「マルチGPU環境」の構築が不可欠です。
しかし、GPUを単純に増やすだけでは十分ではありません。各GPUが効率よく連携するためには、高速かつ正確なGPU間通信が必須となります。
- 学習時:各GPUが分散して計算した勾配(重みの更新情報)を共有しなければ、GPUごとに異なるモデルとなり、正しい学習ができません。
- 推論や大規模モデルの分割実行時:巨大なモデルを複数GPUに分割して実行する場合、あるGPUの出力を次のGPUに渡す必要があり、中間データのやり取りが不可欠です。
2. NVLink:GPU間を直結する高速インターコネクト技術
NVLinkは、NVIDIAが開発したGPU同士を直接接続(Point-to-Point)するための高速インターコネクト技術です。従来、GPU間の接続には、PCやサーバーの標準的な内部バスであるPCIe(PCI Express)が使われてきました。しかし、PCIe経由の通信は「GPU A ⇄ CPU ⇄ GPU B」のように必ずCPUを経由するため、帯域幅に限りがあり、遅延も発生します。この従来のPCIeバスが抱える帯域幅や遅延の課題を解決し、GPU間のデータ転送を劇的に高速化するために設計されました。
2-1. NVLinkの基本アーキテクチャーと特徴
NVLinkは、CPUを介さず、GPU間に専用のデータパスを設けることで、従来のPCIe接続を大きく上回る性能を発揮します。
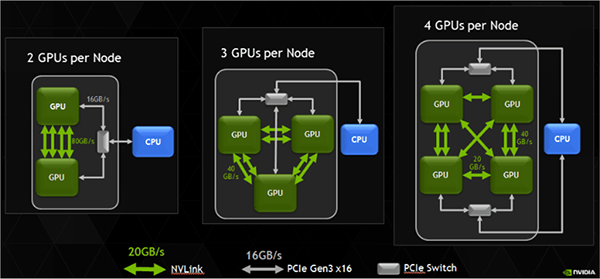
図のように、GPU同士が緑色の線(NVLink)で直接結ばれていることがわかります。このNVLinkには、主に以下のような特徴があります。
【NVLinkの特徴】
- 超高帯域幅: PCIe比で数倍の通信速度を実現し、巨大AIモデルのパラメーターを高速に転送可能。
- 低レイテンシ: CPUを経由しない直接接続により、GPU間通信の待ち時間を大幅に削減。
2-2. NVLinkによるメモリ統合機能
NVLinkで接続されたGPUは、ソフトウェアからは各GPUのHBM(High Bandwidth Memory)を統合的に扱える仮想メモリ空間 として利用できます。たとえば、80GBのGPUを8基つなげば、理論上は合計640GBを参照可能です。ただし、実際には各GPUが独立したHBMを持ち、他GPUのメモリ参照にはNVLinkを介した転送が発生するため、性能はローカルHBMアクセスに比べて低下する 点に注意が必要です。
3. NVSwitch:NVLinkを大規模に拡張するスイッチ技術
NVSwitchは、多数のNVLinkを束ねて相互接続するための、NVIDIAが開発した超高速スイッチチップです。NVLink単体では物理的に困難だった多数のGPU(8基以上)の全対全(All-to-All)接続を可能にし、大規模なマルチGPUシステムを構築するための中核的な役割を担います。
3-1. NVSwitchの役割とAll-to-All接続の実現
NVLinkはあくまで点と点を結ぶ技術であり、GPUの数が増えると、すべてのGPU同士を直接接続する配線が物理的に困難になるという課題がありました。この課題を解決するのがNVSwitchです。NVSwitchをハブとしてGPUを接続することで、すべてのGPUが他のすべてのGPUと、スイッチを介して直接かつ均等に通信できる「All-to-All接続」を効率的に実現します。
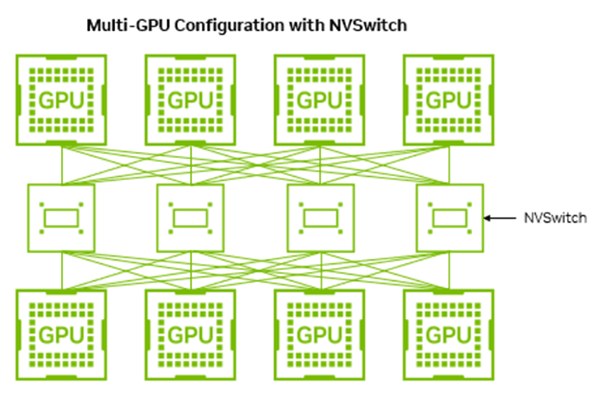
図は、複数のGPUをNVSwitchを介して接続した構成のイメージです。各GPUはスイッチを経由して他のすべてのGPUと均等に通信できるため、大規模な並列処理においても通信ボトルネックを抑えることができます。
3-2. NVSwitchのノンブロッキング設計:並列処理にもたらす効果
NVSwitchは、同時に複数のGPUペアが通信しても、互いの通信が干渉し合わない「ノンブロッキング設計」になっています。これにより、AIの複雑な分散学習のように、多数のGPUが同時に様々な相手と通信を行うような場面でも、通信の詰まりや速度低下が発生せず、常に安定した高パフォーマンスを発揮できます。
4. NVLinkおよびNVSwitchがもたらす性能インパクト
ここまで解説してきたNVLinkとNVSwitchの仕組みは、単なる理論ではありません。実際のベンチマークでは、世代間での性能向上やAI/HPCワークロードにおける大幅な効率改善として表れています。ここからは、具体的なデータをもとに、そのインパクトを確認していきましょう。
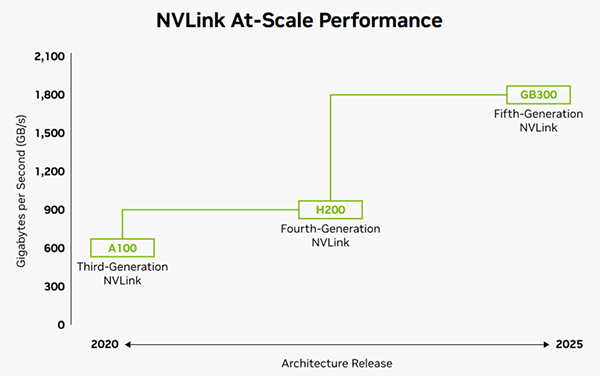
4-1. 世代ごとの圧倒的な帯域幅の進化
NVLinkは世代を重ねるごとに帯域幅を飛躍的に向上させています。特に、最新の第5世代NVLink(Blackwellアーキテクチャー、GB200/GB300)では、GPUあたり最大1.8TB/s(双方向)という驚異的な通信速度を実現しています。
これは、最新のPCIe Gen5 x16(約64GB/s)と比較して約14倍に相当します。
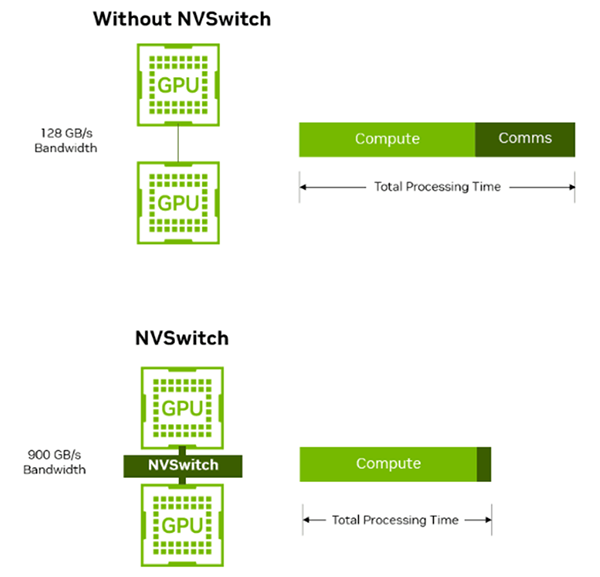
4-2. NVSwitchによる通信オーバーヘッドの削減
NVSwitchは、GPU間通信の帯域を大幅に拡張し、従来のポイントツーポイント方式で発生していた通信オーバーヘッドを削減します。
Without NVSwitch構成では帯域幅が約128GB/sに制約されますが、NVSwitchを介することで最大900GB/sに拡張され、GPU間のデータ転送が格段に効率化されます。
4-3. 大規模言語モデルにおける推論スループットの向上
NVSwitchによるAll-to-Allの高速接続は、大規模言語モデル(LLM)の推論処理で大きな効果を発揮します。GPU間で計算結果をスムーズに共有できるため、処理効率が向上します。
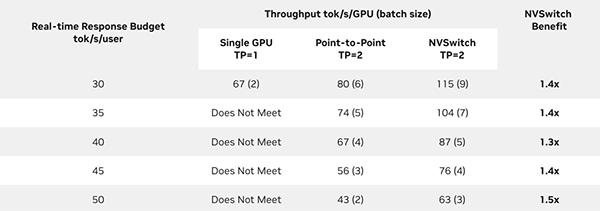
たとえば、Llama 3.1 70Bを2 GPU(TP=2)構成で動かす場合、NVSwitch搭載システムではPoint-to-Point構成と比べて、リアルタイム推論において最大で1.5倍のスループット向上が確認されています。これは、ユーザーが実際に感じる応答速度にも明らかな改善効果をもたらします。
5. NVLink/NVSwitchを搭載した代表的なシステム
NVLinkとNVSwitchは、NVIDIAのAIインフラの中核技術として、さまざまなスケールのシステムに実装されています。ここでは、代表的な製品ラインアップを用途別に紹介します。
5-1. DGX Spark:小規模AI開発に最適なコンパクトAIスーパーPC
2025年に登場したDGX™ Sparkは、Grace Blackwellアーキテクチャーを採用した「GB10」Superchipを搭載しています。1 PetaFLOPS(FP4精度)のAI性能と128GBの統合メモリを備えた小型AIスーパーPCです。CPUとGPUを高速接続するNVIDIA NVLink®-C2Cが採用されています。研究室や個人開発者がプロトタイプを迅速に試す用途に向いています。
【関連記事】
NVIDIA DGX Sparkで変わるAI推論環境 ~特長から他モデルとの比較まで徹底解説~
5-2. DGX Station:デスクトップ最上位パーソナルAIスーパーコンピューター
同じく2025年に発表されたDGX™ Stationは、NVIDIA GB300 Grace Blackwell Ultraデスクトップスーパーチップを搭載しています。最大288GB HBM3eのGPUメモリと最大496GB LPDDR5XのCPUメモリを組み合わせた大規模コヒーレントメモリ構成です。NVIDIA NVLink®-C2Cインターコネクトを介し、デスクトップサイズでデータセンター並みのパフォーマンスを発揮します。企業や研究者が自席で本格的なAI学習・推論を行える環境を実現します。
5-3. DGX H100:エンタープライズAIの主力システム
DGX™ H100は、8基のNVIDIA H100 GPUを第4世代NVLinkとNVSwitchで接続したエンタープライズ向けAIサーバーです。生成AIや大規模モデルの学習を行う企業の標準環境として広く導入されており、SuperPOD™構成へスケールアウトすることで、さらに大規模なAIクラスタの基盤にもなります。
5-4. GB200 NVL72:ラックスケールで動作するAIスーパーコンピューター
最新のGB200 NVL72は、BlackwellアーキテクチャーGPU「B200」を72基、Grace CPUを36基搭載し、1ラック全体を単一の巨大GPUのように動作させるAIスーパーコンピューターです。第5世代NVLinkとNVSwitchにより、72基のGPUが統合メモリ空間を共有。兆単位のパラメーターを持つ大規模言語モデルを、従来比最大30倍のリアルタイム推論性能で処理可能です。
今回紹介したDGX Spark、DGX Station、DGX H100、GB200 NVL72は、NVLink/NVSwitchを活用したシステムです。このほかにも用途や規模に応じて選択できるモデルが提供されており、研究からエンタープライズ利用まで幅広く対応可能です。
各システムの仕様や最新のラインナップについては、以下のページでご確認ください。
▶︎ GPU製品 / サービスの詳細情報ページ
5-5. 用途に応じたシステム選択のポイント
上記のようにNVIDIAのNVLink/NVSwitch搭載システムは、用途や規模に応じて幅広いラインアップが揃っています。研究室での小規模開発から、全社規模での大規模AI基盤まで、適切なシステムを選ぶことができます。
| 用途 | 規模 | 推奨システム | 特徴 |
|---|---|---|---|
| 小規模AI開発・研究室 | 1〜数人 | DGX Spark | GB10 Grace Blackwell Superchip/1PFLOP(FP4)/128GB統合システムメモリ/小型フォームファクタ |
| デスクトップ本格AI開発 | 数人〜部門 | DGX Station | Blackwell Ultra×1/最大288GB HBM3e + 496GB LPDDR5X/Grace 72コア/デスクトップ筐体 |
| 部門レベルのAI学習 | 数十人規模 | DGX H100 | H100×8/640GB/SuperPOD対応 |
| 大規模LLM開発・企業全社 | 研究所・大規模DC | GB200 NVL72 | Blackwell×72/Grace×36/液冷ラック構成 |
たとえば、DGX Sparkは小規模な研究室や個人開発者向けのコンパクトな選択肢であり、DGX Stationはデスクトップサイズながら部門レベルのAI学習をカバーできるパフォーマンスを持ちます。さらに、エンタープライズで標準的に導入されているのがDGX H100で、より大規模な展開にはGB200 NVL72が適しています。
このように、導入環境やワークロードの規模に応じてシステムを選択することで、投資対効果を最大化しながら効率的なAI開発・運用が可能になります。
6. まとめ
本記事では、マルチGPU環境における通信の壁を解決する技術として、NVLinkとNVSwitchの仕組みと効果を解説しました。NVLinkはGPU同士を直接つなぎ、従来のPCIeを大きく超える帯域と低遅延を実現。さらにNVSwitchは多数のGPUを均等に接続し、大規模分散処理や巨大LLMの推論を可能にします。
これらの技術は、研究室レベルの小規模開発から、エンタープライズの大規模クラスタ構築まで、幅広い規模でAIの可能性を押し広げています。特に生成AIやHPC分野においては、今後の性能向上とともに、開発スピードやTCO削減に直結する基盤技術として欠かせない存在です。
NTTPCでは、こうした最先端GPU基盤をお客さまの用途に合わせて設計・導入する支援を行っています。NVLink/NVSwitch対応のシステム導入をご検討の際は、お気軽にご相談ください。
▶︎ お問い合わせはこちら
※NVIDIA、NVLink、NVSwitch、DGX、DGX Spark、DGX SuperPODは、米国およびその他の国におけるNVIDIA Corporationの商標または登録商標です。
※本記事は2025年10月時点の情報に基づいています。製品に関わる情報等は予告なく変更される場合がありますので、あらかじめご了承ください。メーカーが公表している最新の情報が優先されます。