



性能検証
DGX Sparkを2台でクラスタ化してAIエージェントを構築&GPT-OSS-120Bを実行してみた
2026.01.08

GPUエンジニア
小野 雅也

GPUエンジニア
塩田 晃弘

こんにちは、NTTPCコミュニケーションズ1年目社員の塩田・小野です。普段は GPU クラスタの構築や RAG ChatBot の検証業務に取り組んでいます。
このコラムでは、NVIDIA™ DGX Spark を2台でクラスタ化し、そのうえで Dify AI エージェントを動かすまでの手順をご紹介します。さらに、DGX Spark上でGPT-OSS-120Bを実行した場合の推論速度ベンチマークも調べます。
1. 各 DGX Spark の初回セットアップ
① DHCP が有効化されたネットワークに有線接続
AC アダプターを接続すると自動的に電源が入るため、事前にネットワークと映像出力の接続を完了させておきます。Type-C の USB ポートが搭載されているため、キーボードやマウス用に変換アダプターを用意しましょう。外部接続ポートは下図のとおりです。
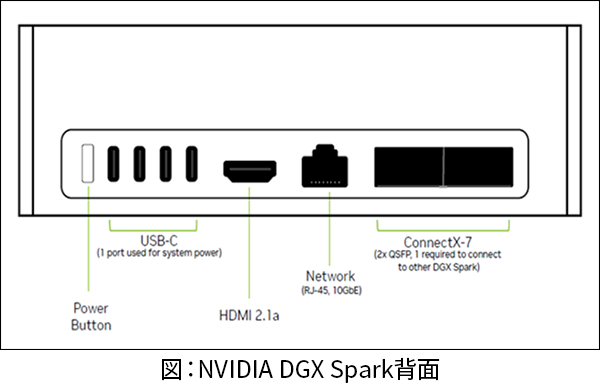
② ユーザー設定
言語・タイムゾーン、ログインユーザーを設定するほか、利用規約と使用統計の収集に同意します。
③ インストール
②のユーザー設定後、自動的にネットワークに接続され、ソフトウェアイメージのダウンロードが始まります。複数回の再起動が行われますが、この間のユーザーによるシャットダウンや再起動は厳禁です。
④ リモートアクセス設定
http://localhost:11000 でアクセスできる DGX ダッシュボードを開き、 update ボタンをクリック。
しばらく時間がかかるので、③と同様に静観してください。
- LANポートのIPアドレス手動設定
設定アプリ -> ネットワーク -> 有線 からIPを手動設定に変更し、IPを入力。 - 設定アプリ -> システム
-> secre shell (SSH) をONに
-> 必要に応じて、リモートデスクトップ(RDP)もON、ログイン用のユーザー名+パスワードを設定 - SSH接続の確認
-> ローカル PC から SSH 接続ができるか確認
ssh <USERNAME>@<DEVICE_IP_ADDRESS>
2. DGX Spark のクラスタ化
2台の DGX Spark マシンを、別売のQSFP ケーブルで物理的に接続します。各マシンは2つのポートを持ちますが、同じ位置のポート同士でつなぐ必要があることに注意が必要です。
connect-two-sparksを参照して、ネットワークインターフェースとパスワードレス SSH 認証の設定を行います。
2-1. 物理接続の確認
nvidia@dxg-spark-1:~$ ibdev2netdev
上記コマンドで、使用されているインターフェースを確認します。
roceP2p1s0f0 port 1 ==> enP2p1s0f0np0 (Down) roceP2p1s0f1 port 1 ==> enP2p1s0f1np1 (Up) rocep1s0f0 port 1 ==> enp1s0f0np0 (Down) rocep1s0f1 port 1 ==> enp1s0f1np1 (Up)
QSFP ポートの IP アドレス設定
マシン1側の設定
# Create the netplan configuration file
sudo tee /etc/netplan/40-cx7.yaml > /dev/null <<EOF
network:
version: 2
ethernets:
enp1s0f0np0:
addresses:
- 192.168.100.10/24
dhcp4: no
enp1s0f1np1:
addresses:
- 192.168.200.12/24
dhcp4: no
enP2p1s0f0np0:
addresses:
- 192.168.100.14/24
dhcp4: no
enP2p1s0f1np1:
addresses:
- 192.168.200.16/24
dhcp4: no
EOF
# Set appropriate permissions
sudo chmod 600 /etc/netplan/40-cx7.yaml
# Apply the configuration
sudo netplan apply
マシン2側の設定
# Create the netplan configuration file
sudo tee /etc/netplan/40-cx7.yaml > /dev/null <<EOF
network:
version: 2
ethernets:
enp1s0f0np0:
addresses:
- 192.168.100.11/24
dhcp4: no
enp1s0f1np1:
addresses:
- 192.168.200.13/24
dhcp4: no
enP2p1s0f0np0:
addresses:
- 192.168.100.15/24
dhcp4: no
enP2p1s0f1np1:
addresses:
- 192.168.200.17/24
dhcp4: no
EOF
# Set appropriate permissions
sudo chmod 600 /etc/netplan/40-cx7.yaml
# Apply the configuration
sudo netplan apply
### DGX間のSSH接続パスワードレス化
#### SSH鍵作成
```bash
wget https://raw.githubusercontent.com/NVIDIA/dgx-spark-playbooks/refs/heads/main/nvidia/connect-two-sparks/assets/discover-sparks
chmod +x ./discover-sparks
bash ./discover-sparks
パスワードレス化
# Copy your SSH public key to both nodes. Please replace the IP addresses with the ones you found in the previous step. ssh-copy-id -i ~/.ssh/id_rsa.pub <username>@<IP for Node 1> ssh-copy-id -i ~/.ssh/id_rsa.pub <username>@<IP for Node 2>
2-2. NCCL のインストール
以下、nccl-for-two-sparkを参照して進めます。
sudo apt-get update && sudo apt-get install -y libopenmpi-dev git clone -b v2.28.3-1 https://github.com/NVIDIA/nccl.git /opt/nccl/ cd /opt/nccl/ make -j src.build NVCC_GENCODE="-gencode=arch=compute_121,code=sm_121"
2-3. NCCL - TEST
NCCL - TEST を用いて NCCL による GPU 間通信の動作確認を行います。インストールコマンドは以下の通りです。
export CUDA_HOME="/usr/local/cuda" export MPI_HOME="/usr/lib/aarch64-linux-gnu/openmpi" export NCCL_HOME="/opt/nccl/build/" export LD_LIBRARY_PATH="$NCCL_HOME/lib:$CUDA_HOME/lib64/:$MPI_HOME/lib:$LD_LIBRARY_PATH" git clone https://github.com/NVIDIA/nccl-tests.git /opt/nccl-tests/ cd /opt/nccl-tests/ make MPI=1
実行コマンドは以下の通りです。ibdev2netdev コマンドで UP になっているインターフェースを指定してください。IP アドレスも適宜変更します。
export UCX_NET_DEVICES=enp1s0f1np1 # (←ibdev2netdevで Upになっていたインターフェースを設定) export NCCL_SOCKET_IFNAME=enp1s0f1np1 export OMPI_MCA_btl_tcp_if_include=enp1s0f1np1 mpirun -np 2 -H 192.168.100.12:1,192.168.100.13:1 \ --mca plm_rsh_agent "ssh -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no" \ -x LD_LIBRARY_PATH=$LD_LIBRARY_PATH \ /opt/nccl-tests/build/all_gather_perf
3. vLLM サーバーの構築
3-1. Docker を sudo なしで実行できるよう設定
sudo groupadd docker sudo usermod -aG docker $USER newgrp docker
3-2. vLLM インストール
今回はvLLMコンテナを利用します。vLLM インストールガイドが参考になります。
docker pull nvcr.io/nvidia/vllm:25.11-py3
なお、GPT-OSSの起動には、vLLMバージョン0.10.2以上が必要なため注意しましょう。
3-3. 分散推論のための準備
以下、vllm stacked-sparksを参照して進めます。
run_cluster.sh をダウンロード
wget https://raw.githubusercontent.com/vllm-project/vllm/refs/heads/main/examples/online_serving/run_cluster.sh chmod +x run_cluster.sh
各 Spark で run_cluster.sh を実行
ノード間通信のための ray server を起動します。
保存先のパス ~/.cache/huggingface は適宜変更してください。
片方のマシンで以下のコマンドを実行。
export MN_IF_NAME=enP2p1s0f1np1 # (←ibdev2netdevで Upになっていたインターフェースを記入) bash run_cluster.sh nvcr.io/nvidia/vllm:25.11-py3 192.168.100.12 --head ~/.cache/huggingface \ -e VLLM_HOST_IP=192.168.100.12 \ -e UCX_NET_DEVICES=$MN_IF_NAME \ -e NCCL_SOCKET_IFNAME=$MN_IF_NAME \ -e OMPI_MCA_btl_tcp_if_include=$MN_IF_NAME \ -e GLOO_SOCKET_IFNAME=$MN_IF_NAME \ -e TP_SOCKET_IFNAME=$MN_IF_NAME \ -e RAY_memory_monitor_refresh_ms=0 \ -e MASTER_ADDR=192.168.100.12
もう一方のマシンで以下のコマンドを実行。
export MN_IF_NAME=enP2p1s0f1np1 # (←上と同じインターフェースを記入) bash run_cluster.sh nvcr.io/nvidia/vllm:25.11-py3 192.168.100.12 --worker ~/.cache/huggingface \ -e VLLM_HOST_IP=192.168.100.13 \ -e UCX_NET_DEVICES=$MN_IF_NAME \ -e NCCL_SOCKET_IFNAME=$MN_IF_NAME \ -e OMPI_MCA_btl_tcp_if_include=$MN_IF_NAME \ -e GLOO_SOCKET_IFNAME=$MN_IF_NAME \ -e TP_SOCKET_IFNAME=$MN_IF_NAME \ -e RAY_memory_monitor_refresh_ms=0 \ -e MASTER_ADDR=192.168.100.12
node 名の確認
docker ps | grep nvcr
run_cluster.sh で起動されたコンテナ名を確認します。node-12345 のように、5桁の数字が付いたコンテナ名になっていると思います。
ray status の確認
前項で確認したコンテナに対し、ray status コマンドを発行します。出力で 0.0/2.0 GPU という行があることを確認します。
docker exec node-12345 ray status
3-4. GPT-OSS-120B のダウンロードと vLLM サーバーの起動
huggingface-cli コマンドで片方のマシンにダウンロードを行い、rsync でもう一方のマシンに共有します。
pip install huggingface-cli hf download openai/gpt-oss-120b
モデルの転送には、rsync -a コマンドを使用します。scp コマンドではシンボリックリンクの中身をたどってコピーされるため、ファイルが重複してコピーされてしまいます。
rsync -avz /home/user/.cache/huggingface/hub/models--openai--gpt-oss-120b user@192.168.100.11:/home/user/.cache/huggingface/hub
vLLM サーバーの起動
docker exec -it node-12345 /bin/bash
今回は2台構成のため、--tensor-parallel-size 2 の設定が必須です。
vllm serve openai/gpt-oss-120b \
--host 0.0.0.0 \
--port 8000 \
--tool-call-parser openai \
--enable-auto-tool-choice \
--gpu-memory-utilization 0.8 \
--tensor-parallel-size 2
(APIServer pid=24) INFO: Application startup complete.
が出力されれば、サーバーの起動は完了です。
確認用コマンド
別ターミナルから以下のコマンドを入力し、起動した vLLM サーバーにクエリを投げます。
curl -X POST "http://192.168.100.10:8000/v1/chat/completions" -H "Content-Type: application/json" -d '{
"model": "openai/gpt-oss-120b",
"messages": [
{"role": "user", "content": "What is the capital of France?"}
],
"max_tokens": 256,
"temperature": 0.7,
"top_p": 0.9,
"stream": false
}'
正常に動作すれば、以下のような出力が得られます。
{...,"choices":[{"index":0,"message":{"role":"assistant","content":"The capital of France is **Paris**."...}}]},
vLLM サーバーを終了する場合は、vllm serve コマンドを実行したターミナルで Ctrl + C を入力します。
4. Dify のインストール
今回はAIエージェントの構築のためDifyを利用します。
Dify環境の構築については、こちらの記事も参考にしてください。
【生成AIによる業務変革LOG #8】DifyでローカルLLMを作ってみよう!|【技業LOG】技術者が紹介するNTTPCのテクノロジー|【公式】NTTPC
まずは、Dify を動かすのに必要な Docker Compose をインストールします。
sudo apt install docker-compose-plugin git clone https://github.com/langgenius/dify cd dify/docker/ cp .env.example .env
docker-compose.yaml ファイルを編集します。
cp docker-compose.yaml docker-compose.yaml.old vim docker-compose.yaml
編集内容は以下の通りです。
sevices: (中略) weaviate: - profiles: - - '' - - weaviate + ports: + - "8080:8080"
編集後、docker コンテナを立ち上げます。
docker compose build docker compose pull docker compose up -d
もし、初期画面でユーザー登録に失敗する場合は、以下のコマンドを試してください。
docker compose down sudo chown -R 1001:1001 ./volumes/app/storage docker compose up -d
5. Dify の動作確認
Dify のモデルプロバイダー画面から、vLLM サーバーを登録します。
今回は、あらかじめ当社にてDify上にチャットアプリを作成し、検索機能を利用するためのtavilyプラグインのインストールと APIキーの設定などを実施しています。本筋から逸れるため、詳しい手順は割愛します。
チャットアプリに、私たちNTTPCコミュニケーションズ株式会社の歴史について聞いてみました。うまく実行できていますね!
実際の動作の様子(スクリーンショット)
6. ベンチマーク
最後に、DGX Spark における LLM の推論速度について紹介します。
vLLM を用いて GPT-OSS-120B を動かした結果、以下の表の通りとなりました。
| モデル名 | ノード数 | スループット [tokens/s] | |
|---|---|---|---|
| 並列度=1 | 並列度=10 | ||
| GPT-OSS-120B | 1 | 32.77 | 87.97 |
| 2 | 37.56 | 112.35 | |
| GPT-OSS-120B (弊社独自のネットワーク最適化を適用) |
2 | 45.26 (+20.65%) | 133.17 (+18.5%) |
ノード数が1つの場合でも、並列度1では約30 tokens/s ということなので、単一ノード構成でも実用的な速度で動作できることが分かります。
一方、ノード数を2つに増やした場合、ノード間通信のオーバーヘッドが大きく、スループットの大幅な向上は見られませんでした。しかし、弊社にて独自にネットワークの最適化を行うことで、約20%のスループット向上が確認できました。
7. まとめ
今回は、DGX Spark 2台構成におけるセットアップと、そのユースケースとしての Dify AI エージェント構築について解説しました。
DGX Spark によって今後ローカル LLM 導入の敷居が下がり、エンタープライズにおける AI 活用が活発化していくことに期待したいです。
※「NVIDIA」「NVIDIA DGX Spark」は、米国およびその他の国における NVIDIA Corporation の商標または登録商標です。
※「Docker」は、米国およびその他の国における Docker Inc. の商標または登録商標です。
※「vLLM」 は vLLM Project の商標です。
※「Dify」は、米国LangGenius社の登録商標です。