



性能検証
DGX SparkでOSS映像生成モデル「LTX-2」を動かしてみた
2026.02.16

GPUエンジニア
小野 雅也

GPUエンジニア
塩田 晃弘
こんにちは、NTTPCコミュニケーションズ1年目社員の小野・塩田です。普段は GPU クラスタの構築や RAG ChatBotの検証業務に取り組んでいます。
この記事では、2026年1月にオープンソース公開された映像生成モデル「LTX-2」を紹介します。また、当社が保有するNVIDIA DGX™ Spark検証機でLTX-2を動かすまでの手順と、その結果も公開します。
【目次】
1. LTX-2とは? 圧倒的な高速性の理由
LTX-2とは、映像と音声を同時に生成できる本格的なオープンソース映像生成モデルです。従来モデルと比較して大幅に高速化されており、短い推論時間で高品質な音声付き映像を生成できる点が大きな特徴です。
次の表は、LTX‑2 の論文[1]から引用した、従来モデル(Wan 2.2)との速度比較です。いずれもNVIDIA H100 GPU上で測定された値ですが、LTX‑2 は 1ステップを約 1 秒で処理しており、Wan 2.2と比較して約18倍の圧倒的な高速性を示しています。
Table1: Inference Speed. Comparison of time per diffusion-step on H100 GPU
| Model | Modality | Params | Sec/Step |
|---|---|---|---|
| Wan2.2 | Video Only | 14B | 22.30s |
| LTX-2 | Audio + Video | 19B | 1.22s |
[1] HaCohen, Y., Brazowski, B., Chiprut, N., Bitterman, Y., Kvochko, A., Berkowitz, A., ... & Farbman, Z. (2026). LTX-2: Efficient Joint Audio-Visual Foundation Model. arXiv preprint arXiv:2601.03233.から引用
このような高速化が可能になっている理由は、LTX / LTX‑2 が情報を高い圧縮率で削減し、高度に抽象化された表現を用いて生成を行うためです。動画は連続した画像(フレーム)で構成されます。 画像をそのまま扱うとピクセル数が膨大になるため、まず Variational Autoencoder と呼ばれるネットワークで「潜在空間」へ圧縮 し、圧縮された表現を トークン として扱います。具体的には、空間(横×縦)と時間(フレーム)方向をまとめて圧縮して 1 トークンに変換しています。
- 従来の多くのモデル:空間を 8 × 8(=64 ピクセル)に、時間を 4 フレーム にまとめ、1 トークン=256 ピクセル の情報を表します。
- LTX/LTX‑2 系列:空間を 32 × 32(=1 024 ピクセル)に、時間を 8 フレーム にまとめ、1 トークン=8,192 ピクセル を表します。
これにより、 1 トークンに含まれるピクセル数は 32 倍(256 → 8,192)になり、トークン総数は約 1/32 に減ります。トークン数が減ると、Transformer の自己注意計算は O(N²) で減少するため、GPU 上の演算量が数百倍〜数千倍に削減されます。その結果、映像生成は 数倍から数十倍の高速化 が実現し、同じハードウェアでも高解像度・長尺の動画をリアルタイムに近い速度で生成できます。
2. 環境構築
それでは、LTX-2の利用環境を構築していきます。
検証に用いたマシンは「NVIDIA DGX Spark」です。
2-1. (未インストールの場合)ComfyUIのインストール
ComfyUIのレポジトリをクローンし、pip install を行います。
python3 -m venv comfyui-env source comfyui-env/bin/activate pip install torch torchvision --index-url https://download.pytorch.org/whl/cu130 git clone https://github.com/comfyanonymous/ComfyUI.git cd ComfyUI/ pip install -r requirements.txt
2-2. (インストール済みの場合)ComfyUIのアップデート
ComfyUIのバージョンが古い場合はLTX-2が動作しないことがあります。その際には適宜アップデートしてください。
source comfyui-env/bin/activate cd ComfyUI/ git pull pip install -r requirements.txt
2-3. モデルのダウンロード
hf downloadコマンドを使用して、必要な重みファイルをダウンロードします。hf downloadコマンドを使うには、huggingface_hub のインストールが必要です。
※ モデルのダウンロードに時間がかかる場合があります
# huggingface_hub のインストール pip install huggingface_hub # ベースモデル hf download Lightricks/LTX-2 --include "ltx-2-19b-dev-fp8.safetensors" --local-dir models/checkpoints/ # TextEncorderモデル wget -O models/text_encoders/split_files/gemma_3_12B_it_fp4_mixed.safetensors \ https://huggingface.co/Comfy-Org/ltx-2/resolve/main/split_files/text_encoders/gemma_3_12B_it_fp4_mixed.safetensors # ltx-2-spatial-upscaler hf download Lightricks/LTX-2 --include "ltx-2-spatial-upscaler-x2-1.0.safetensors" --local-dir models/latent_upscale_models
2-4. カスタムノードインストール
ComfyUIで LTX-2を使うためのプラグインをインストールします。ComfyUI ディレクトリ直下の custom_nodes ディレクトリに移動し、ComfyUI-LTXVideo.git と ComfyMath.gitをクローンしましょう。
cd custom_nodes git clone https://github.com/Lightricks/ComfyUI-LTXVideo.git cd ComfyUI-LTXVideo pip install -r requirements.txt cd .. git clone https://github.com/evanspearman/ComfyMath.git cd ComfyMath/ pip install -r requirements.txt
2-5. 起動
ComfyUIディレクトリに戻り、main.pyを実行しましょう。リモートで接続している場合は、--listen 0.0.0.0オプションが必要ですが、ローカルの場合は不要です。
cd .. python main.py --listen 0.0.0.0
コマンドを実行すると、ポート8188でComfyUI の Webアプリが起動します。ブラウザからアクセスして、正常に動作しているか確認してください。
3. ComfyUIでLTX-2のワークフロー作成
LTX-2のワークフローを作成する方法について説明します。
3-1. フルモデル
Text-to-Videoをダウンロードし、video_ltx2_t2v.jsonという名前で保存します。
ComfyUIの画面から、左上のマーク → [ファイル] → [開く] を選択し、先ほどダウンロードしたファイルを選択します。
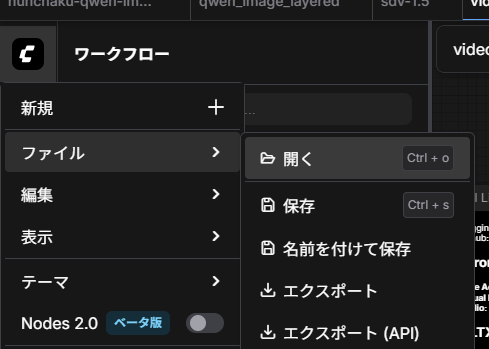
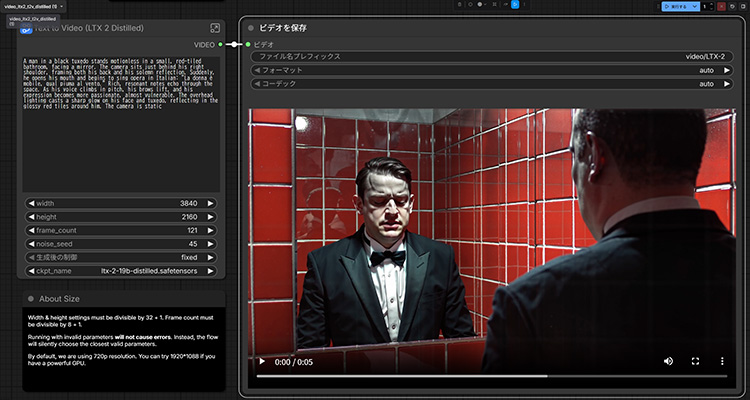
ファイルを開くと以下のような画面が表示されます。右上の[実行する]ボタンを押すことで、映像生成が行われます。中央のノードから、プロンプトや映像サイズのパラメータを変更することも可能です。
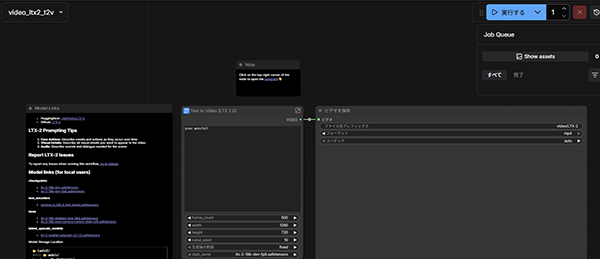
3-2. 蒸留モデル
以下コマンドでモデルをダウンロードします。
※ モデルのダウンロードに時間がかかる場合があります
wget https://huggingface.co/Lightricks/LTX-2/resolve/main/ltx-2-19b-distilled.safetensors
次に、Text-to-Video-Distilledから蒸留用のワークフローをダウンロードし、video_ltx2_t2v_distilled.jsonという名前で保存します。その後は、通常モデルの場合と同様の方法で実行可能です。
4. 実行結果
今回は、LTX-2公式が提供しているデフォルトのプロンプトを用いて動画生成しました。
プロンプト
A man in a black tuxedo stands motionless in a small, red-tiled bathroom, facing a mirror. The camera sits just behind his right shoulder, framing both his back and his solemn reflection. Suddenly, he opens his mouth and begins to sing opera in Italian: "La donna è mobile, qual piuma al vento." Rich, resonant notes echo through the space. As his voice climbs in pitch, his brows lift, and his expression becomes more passionate, almost vulnerable. The overhead lighting casts a sharp glow on his face and tuxedo, reflecting in the glossy red tiles around him. The camera is static
生成した動画
各モデルでの実行結果は下表の通りです。なお、24FPSで生成しています。
| モデル | 生成した動画の再生時間 | 3840×2160 | 2560×1440 | 2048×1152 | 1280x720 | 832×480 |
|---|---|---|---|---|---|---|
| full | 12s | クラッシュ | 30m | 22m | 10m | 3m10s |
| full | 5s | 31m | 10m | 5m | 3m53s | 1m10s |
| 蒸留 | 12s | クラッシュ | 19m22s | 12m21s | 3m | 1m10s |
| 蒸留 | 5s | 18m | 6m57s | 3m50s | 1m9s | 34s |
832x480 の低解像度の場合、通常モデル/蒸留モデルともに20秒の長尺動画でも3分程度で生成可能でした。
今回の検証では、最高で2560×1440という高解像度での生成も可能でした。ただしDGX Sparkだと12秒間の動画生成に30分費やすため、体感でいうとここが実用的な上限でしょうか。
5. まとめ
LTX‑2 の検証では、短尺動画における高い映像品質が特に際立ちました。5〜10 秒程度のクリップであれば滑らかな生成が可能で、企業利用のオープニング映像やプロモーション用途にも十分耐えうるクオリティだと感じました。
一方で、日本語音声の自然さにはまだばらつきがあり、音声付き動画を制作する際には追加の調整が必要となる場面も見受けられました。
また、蒸留モデルはクオリティを大きく損なわずに 1.5~2 倍の高速化が確認できました。一方で、20 秒を超える長尺の生成は不安定になりやすく、現時点ではおおむね 20 秒前後がDGX Sparkでの実用的な上限と考えられます。
最後に、LTX‑2は高いVRAMを要求するモデルですが、128GBと大容量のVRAMを備えている DGX Sparkであれば映像生成を気軽に試せる点は有用でした。試行・検証段階の利用であれば十分な環境だと思います。
さらに高速な処理を行いたい場合は、NVIDIA RTX PRO™ 6000 Blackwellを複数搭載したサーバーなど、よりハイスペックな実行環境を用意するのが良いでしょう。
DGX SparkをはじめとするGPU製品や、LLM実行環境の導入をご検討の際は、ぜひNTTPCにご相談ください。お客さまの要件に応じたGPUソリューションを提案します。
▶︎ お問い合わせはこちら
※ 本記事に掲載しているコマンド、設定例、手順等は、執筆時点での情報をもとに作成しています。
本記事の内容を実行した際に発生する損害について、弊社は一切の責任を負いません。また、設定手順等が記載通りに再現されない場合があります。
※「NVIDIA」「NVIDIA DGX Spark」「NVIDIA H100」「NVIDIA RTX PRO 6000 Blackwell」は、米国およびその他の国における NVIDIA Corporation の商標または登録商標です。
※ 「ComfyUI」は、米国およびその他の国における Drip Artificial Inc. の商標または登録商標です。
※ 「LTX」「LTX-2」は、イスラエルおよびその他の国における LIGHTRICKS LTD (PRIVATE LIMITED COMPANY; Israel, Israel) の商標または登録商標です。
※ 「Wan」は、中国およびその他の国における ALIBABA INNOVATION PRIVATE LIMITED (Private Limited Company; Singapore) の商標または登録商標です。