



設計・構築
GPUクラスタを構築するには、サーバー単体の設計だけでなく、ノード間通信を高速化するためのインターコネクトやロスなくストレージと接続する技術、計算リソースやジョブを管理するためのマネジメントツールなど、ハードウェアからソフトウェア、ネットワークまでフルスタックなエンジニアリングスキルを総動員する必要があり、いわば「技術の総合格闘技」といえます。
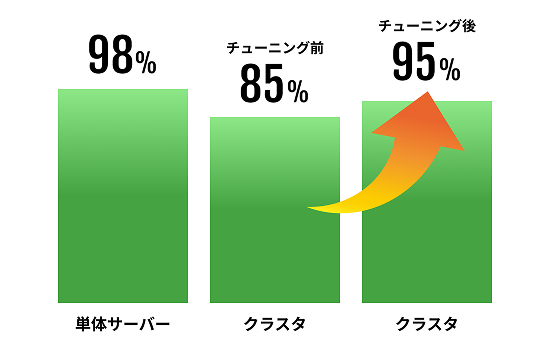
さらに、単に複数のGPUを接続するだけでは、パケットロスやストレージ読み書き時の遅延などの要因により、クラスタ全体のパフォーマンスを引き出すことはできません。チューニングを行わない場合、性能は85%程度まで低下してしまうとも言われています。(右図参照)
統合的なクラスタ設計・構築ノウハウを保有するNTTPCエンジニアが、大規模かつ複雑なジョブを実行可能なAI開発基盤をお求めのお客さまニーズに寄り添い、適切なチューニングを行うことで、GPUクラスタのパフォーマンスを最大化に貢献します。
「何から聞けばいいかわからない」「はじめの一歩から相談に乗ってほしい」という方もぜひお問い合わせください。
ご提供内容
提案フェーズ
お客さま要件に寄り添った提言
-

要件定義
ビジネスゴール、対象ワークロード特性、予算・納期をお客様と共に明確化し、プロジェクト全体のロードマップを策定
-
ハードウエア選定
GPUの演算性能・メモリ容量、CPU、メモリ、電源、冷却システムなどの組み合わせを、性能・拡張性・コストのバランスで選定
-

データセンター選定・
電力供給サーバラックへの二重化冗長電源(UPS)導入支援
GPUクラスタを安定稼働できる高電力データセンターの提案
コンテナ型データセンターの設計・導入
設計フェーズ
適切なシステム・ソリューションを選定
-

ファシリティ設計
ラック内の機器配置における重量・重心バランスなどの物理設計から、冷却・空調・搬入経路などの導入ポイントを考慮し、施設との調整をサポート
-

ネットワーク設計
InfiniBand/高速 Ethernet のスイッチ選定、Spine‑Leaf もしくはファブリックトポロジの設計・構築により、GPU 間の高速通信を実現
-
ストレージ設計
各種ハードウェアメーカー製品、ファイルシステム(Lustre・BeeGFS など)から適切な選択肢をチョイスし、容量・スループット・コスト要件を満足するストレージ基盤を設計・提供
-

GPU利用設定
最新 NVIDIA ドライバ、CUDA Toolkitのインストールと動作検証により、GPUをすぐに利用開始できる環境を提供
-

ソフトウェアインストール
OS/ファームウェアのデプロイや、今後のスケールアウトに備えた自動化基盤の構築、各種AIフレームワークの導入を実施
-

クラスタ管理基盤導入
クラスタ管理基盤を導入し、ノードの自動登録・リソース管理を統一的に実行
実装フェーズ
セットアップ・環境構築
-

ジョブ管理
リソース定義・QoS 設定、GPU パススルー・CNI 設定等を最適化し、効率的にジョブを実行できるよう適切に調整
-

高可用性設計
コントロールノードの冗長化、フェイルオーバー機構、ネットワークの冗長リンク等を設計し、システム全体の可用性を向上
-

セキュリティ対策
ネットワーク分離、ファイアウォール/UTM設定、監査ログ取得などにより、情報資産を安全に保護
運用フェーズ
システム監視・最適化
-

ドキュメント整備・運用監視
物理・論理構成図、配線表、パラメータシートの作成、可視化ツールによるリアルタイム監視、障害切り分け手順書の整備を通じて、運用までのロードマップを整備
関連コラム

生成AI/LLMの開発を加速するGPUクラスタ Vol.2:NVIDIA Base Command Manager ™ によるGPUクラスタの運用管理
2024.04.10

GPUエンジニア
大野 泰弘

サーバーエンジニア
力石 誠也

ネットワークエンジニア
古賀 祥治郎

生成AI/LLMの開発を加速するGPUクラスタ Vol.1【後編】インターコネクトのトポロジーとシステム構成
2024.03.12
GPUエンジニア
大野 泰弘
GPUエンジニア
力石 誠也
ネットワークエンジニア
古賀 祥治郎

生成AI/LLMの開発を加速するGPUクラスタ Vol.1【前編】マルチノードGPUシステムとインターコネクト
2024.01.25
GPUエンジニア
大野 泰弘
GPUエンジニア
力石 誠也
ネットワークエンジニア
古賀 祥治郎

これだけは押さえたい!ジョブスケジューラの基礎知識
2025.08.27

GPUエンジニア
今井 雄貴