



基礎知識
概要
近年、目覚ましい進歩を遂げている生成AIは、様々な分野に革新をもたらす可能性を秘めています。「gpt-oss:120B」や「Qwen3-Coder 480B」などの膨大なパラメータ数を持つ生成AIの学習・推論をさらに加速させるためには、これまでの常識を覆すより多くの計算リソースが求められます。
そのため、複数のGPUサーバー・ストレージを高速ネットワークで接続することで圧倒的な処理能力を実現する「GPUクラスタ」に注目が集まっています。
GPUクラスタ(GPU Cluster)とは
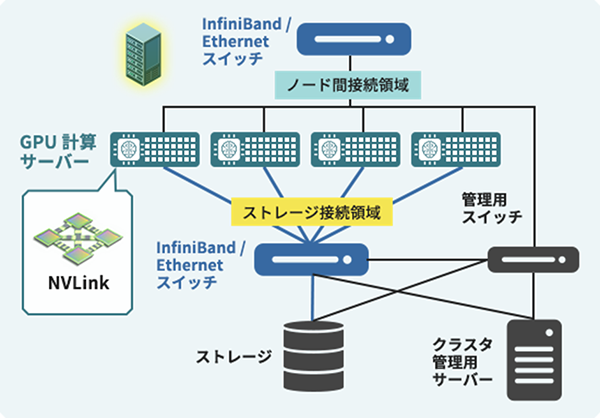
右図のように多数のGPUサーバー(ノード)をネットワークで接続し、それぞれに搭載されたGPUを協調して動かすシステムのことです。
GPUクラスタは「GPUサーバーの集団」であり、巨大なAIやHPCの計算を並列処理で可能にする基盤です。
GPUクラスタを活用することで、1台のGPUサーバーだけでは扱えない大規模パラメータモデルや、複雑なAIアルゴリズムを効率的に学習・推論できるようになります。
設計・構築
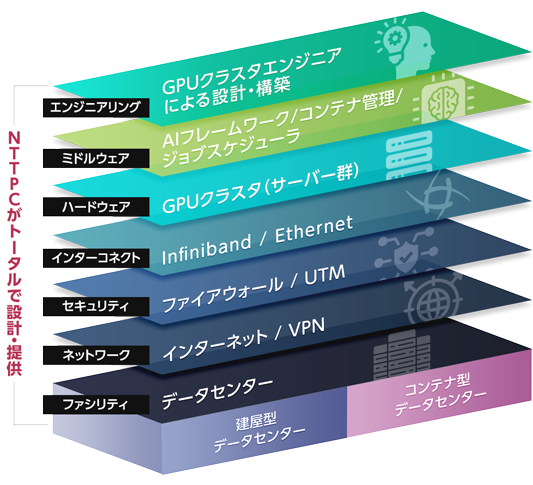
GPUクラスタを構築するには、サーバー単体の設計だけでなく、ノード間通信を高速化するためのインターコネクトやロスなくストレージと接続する技術、計算リソースやジョブを管理するためのマネジメントツールなど、ハードウェアからソフトウェア、ネットワークまでフルスタックなエンジニアリングスキルを総動員する必要があり、いわば「技術の総合格闘技」といえます。
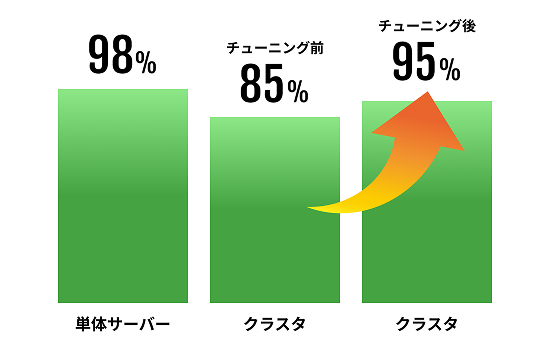
さらに、単に複数のGPUを接続するだけでは、パケットロスやストレージ読み書き時の遅延などの要因により、クラスタ全体のパフォーマンスを引き出すことはできません。チューニングを行わない場合、性能は85%程度まで低下してしまうとも言われています。(右図参照)
統合的なクラスタ設計・構築ノウハウを保有するNTTPCエンジニアが、大規模かつ複雑なジョブを実行可能なAI開発基盤をお求めのお客さまニーズに寄り添い、適切なチューニングを行うことで、GPUクラスタのパフォーマンスを最大化に貢献します。
「何から聞けばいいかわからない」「はじめの一歩から相談に乗ってほしい」という方もぜひお問い合わせください。
構成要素
消費電力が高く発熱量の大きなGPUクラスタを運用するためには、設置環境となるファシリティも綿密に検討する必要があります。さらに、外部ネットワークへの接続やセキュリティの考慮も欠かせません。
自社独自のデータセンター、ネットワークサービスを提供するNTTPCは、GPUサーバーの電源管理、冷却方式(空冷 or 水冷)、外部ネットワーク接続、セキュリティ監視など、インフラ管理のためのナレッジも豊富に有しています。
また、利用状況に応じて必要な分だけリソースを活用でき、運用管理まで一任できるGPUプライベートクラウド™の提供も行っています。
NTTPCは、ミッションクリティカルな商用サービスから、高いパフォーマンスが求められる研究開発基盤に至るまで、用途・予算に合わせて、客観的にマルチメーカー・マルチベンダーを比較し、適切なインフラの設計・構築を行っています。
NTTPC取り扱いメーカー(一例)
NTTPC取り扱いカテゴリ





サーバー冷却方式
GPUの高性能化に伴い、発熱や消費電力の増大、安定稼働の確保といった運用面での課題も顕在化しています。
GPUリソースを最大限に活用するためには、これらの変化に柔軟に対応できるインフラ設計と運用体制が求められています。
ご予算やラックスペース、計算負荷、運用体制などの要件に合わせて、空冷・水冷それぞれのメリット・デメリットを踏まえた適切な冷却方式を提案します。

GPUクラスタの標準設計モデル ― リファレンスアーキテクチャ
AI導入が加速する昨今、その土台となるGPUクラスタにも高い可用性・導入の容易さ・安定稼働が求められています。
しかし、GPUクラスタの設計には、「各GPUノードのスペックをどう見積もるか」「GPUノード間をどのように接続するか」など、膨大な検討が必要です。各企業が独自にGPUクラスタをゼロから設計・構築するのは大きな負担であり、技術的ハードルも高いのが実情です。
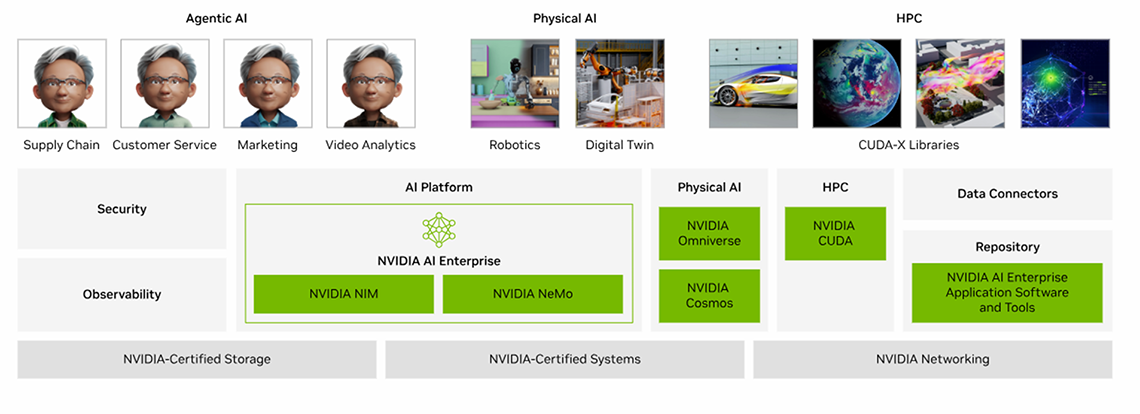
そこでNVIDIAでは、“GPUクラスタの設計図”ともいえる「リファレンスアーキテクチャ」を公開しています。
これは、NVIDIAとパートナー企業が共同で検証し発表した構成例であり、性能や信頼性を両立できる標準設計モデル(ベストプラクティス)です。
このアーキテクチャでは、NVIDIA GPUや高速ネットワーク(InfiniBand / NVLink)、さらにCUDAやNVIDIA AI Enterpriseといったソフトウェアスタックを適切に組み合わせ、パフォーマンス・拡張性・信頼性を兼ね備えた設計を提示しています。
企業はこのリファレンスアーキテクチャに沿って導入を進めることで、複雑なパターンの検証や個別設計プロセスを省略し、短期間でスムーズにAIインフラ基盤を立ち上げることができます。
NTTPCは、NVIDIA が定めるリファレンスアーキテクチャ(BasePOD/SuperPOD)に準拠した GPU クラスタ導入をワンストップで支援しています。
リファレンスアーキテクチャを採用するメリット
-

スケールとパフォーマンス
LLM/Gen AIトレーニングに最適化されており、微調整、エンドツーエンドの推論、コンピューティング、ネットワーク、ストレージソリューションと連携
-

効率性と弾力性
エンドツーエンドでテストされたモジュール式で、NVISまたはNVIDIAパートナーによる導入により、より迅速な実現が可能
-

安全なインフラストラクチャ
最速の導入時間で安全なマルチテナント環境を実現
リファレンス設計の代表例 ― NVIDIA DGX SuperPOD / BasePOD
NVIDIA が定義したGPUクラスタにおけるリファレンスアーキテクチャは、「NVIDIA DGX SuperPOD™」および「NVIDIA DGX BasePOD™」として公開されています。
これらは、NVIDIA DGX™ プラットフォームを中心に、ネットワーク・ストレージ・冷却などを最適化した“統合 AI インフラストラクチャコンピューターです。

-
フルスタックAIインフラストラクチャ
すぐに実行できるターンキー AI スーパーコンピューターとして、高性能コンピューティング、ネットワーキング、ストレージ、ソフトウェア統合を最適化した設計です。
-
開発者の生産性を向上
エンタープライズ グレードのクラスタとワークロード管理、コンピューティング、ストレージ、ネットワーク インフラストラクチャを高速化するライブラリ、AI ワークロード向けに最適化されたオペレーティング システムが含まれ、開発者はシステム構築に煩わされることなく本業に集中できます。
-

NVIDIAにてテストおよび実証済み
実世界のエンタープライズ AI ワークロードで限界まで拡張し、広範にテストされているため、アプリケーションのパフォーマンスについて心配する必要はありません。
-

AIインフラエキスパートによるサポート
インフラストラクチャのライフサイクル全体でガイダンスとサポートを提供し、AI ワークロードを最高のパフォーマンスで実行できるように、フルスタックをカバーするエキスパートへのアクセスを提供します。
| SuperPOD | BasePOD | |
|---|---|---|
| 規模 | 数百〜数千ノード規模まで拡張可能 | 数十ノード規模 |
| 用途 | エンタープライズレベルの大規模モデル学習やハイブリッド AI/HPC ワークロードに適しています | 導入コスト・運用負荷が比較的低く、部門レベルのモデル開発・検証などに適しています |
| 詳細 | https://www.nvidia.com/ja-jp/data-center/dgx-superpod/ | https://www.nvidia.com/ja-jp/data-center/dgx-basepod/ |
















FAQ
- GPUクラスタはどのような分野で利用されていますか?
- 主に以下のような分野で利用されています。
・生成AI /LLM / VLMの学習・推論
・医薬品開発や分子シミュレーション
・自動運転システム
・画像・音声認識
・デジタルツインやシミュレーション
- なぜ単一のGPUサーバーでは不十分なのですか?
- 数百億〜それ以上のパラメータを持つ生成AI/LLMモデルの学習・推論を行う際には、1台のGPUサーバーの計算性能では足りないケースがあります。GPUをクラスタリングすることで、複数ノードで分散処理することが可能です。
- GPUクラスタを導入する場合に必要な設備・環境はありますか?
- 電力・冷却・重量・ネットワークなどの多層的なインフラ要件を同時にクリアする必要があります。規模や用途によっても大きく異なりますので、詳しくはお問い合わせください。
- 小規模サーバーを導入した後、徐々にGPUクラスタに拡張することは可能ですか?
- 将来的な拡張性を見越して設計することで、ビジネス規模の拡大に合わせてノードを追加し、スケールアウトすることも可能です。
- 投資額はどの程度を見込めばいいですか?
- 構成・規模によって大きく異なりますので、詳しくはお問い合わせください。