



基礎知識
いまさら聞けないInfiniBand:超低遅延ネットワーク技術の進化と活用
2025.12.23

GPUエンジニア

近年、GPUサーバーの計算性能は驚異的なスピードで向上しています。しかし、どれだけ個々のサーバーの計算能力が高くても、マルチノードで並列計算させる場合に、サーバー間でデータをやり取りするネットワークが遅いと、GPUは”データ待ち”の状態となる時間が長くなり、その性能を最大限発揮することができません。
このネットワーク上のボトルネックを解消するために専門的に設計された技術が「InfiniBand」です。実際に、大規模なAI学習基盤において、サーバー間をつなぐ事実上の標準(デファクトスタンダード)技術となっており、従来のEthernetとは次元の異なる通信性能で、GPUクラスタ全体のポテンシャルを解放します。
本記事では、このInfiniBandの基本技術からRDMAやGPU Direct RDMAといった技術の紹介、従来のEthernetとの比較、そしてNVIDIAの提供するInfiniBandプラットフォームまで、その全貌を解説します。
目次:
- InfiniBandとは?AI・HPC時代のデータセンターを支えるネットワーク技術
- Ethernetとの違い:5つのポイント比較
2-1. 超高速な通信を可能とする帯域幅
2-2. 分散処理の効率化を可能とする低遅延(レイテンシ)
2-3. CPU負荷を最小化するRDMA通信
2-4. 安定したデータ転送を可能とするロスレス通信と信頼性
2-5. ROIを高める高性能設計とコストのバランス - InfiniBandの主要技術とは
3-1. スイッチドファブリックアーキテクチャ
3-2. RDMA(Remote Direct Memory Access)とGPU Direct RDMA - InfiniBandの性能を最大化するネットワーク設計
4-1. ネットワークトポロジ:Fat Tree
4-2. In-Network Computing:SHARP - NVIDIAの提供するInfiniBandプラットフォーム
5-1. 世代別プラットフォーム性能比較 - まとめ
1. InfiniBandとは?AI・HPC時代のデータセンターを支えるネットワーク技術
InfiniBandは、極めて高いスループットとサブマイクロ秒レベルの低遅延を特徴とする、次世代の高速ネットワーク通信技術です。InfiniBand Trade Association(IBTA)が策定したオープンな業界標準で、サーバーやストレージを高信頼かつ高速に接続するチャネルベースのスイッチドファブリック型アーキテクチャを採用しています。
当初はCPU間通信や一般的なHPC用途向けのインターコネクトとして誕生しましたが、現在ではAIの大規模分散学習・推論など要求の厳しいワークロードに対応する通信基盤として進化しています。
こうした用途では、従来のEthernetでは対応しきれない通信負荷が課題となることも多く、InfiniBandはそのボトルネックを解消する技術として注目を集めています。
2. Ethernetとの違い:5つのポイント比較
InfiniBandは、通信速度や遅延、CPU負荷など、ネットワーク性能のあらゆる面で従来のEthernetとは大きく異なる特性を持っています。特に、RDMA(リモート・ダイレクト・メモリアクセス)を活用したロスレス通信や超低遅延のアーキテクチャは、AI処理やHPCなどの用途で圧倒的な優位性を発揮します。
ここでは、以下の表に示した帯域幅・遅延・CPU負荷・信頼性・コストという5つの観点から、InfiniBandとEthernetの違いを比較し、その特徴を明確にします。
| 比較ポイント | InfiniBand | Ethernet |
|---|---|---|
| 帯域幅 | 400~800Gb/s(ConnectX-7〜8) | 最大800Gb/s(IEEE 802.3df標準、1.6Tb/s開発中) |
| 遅延 | サブマイクロ秒(例:600ns以下) | 数十マイクロ秒 |
| CPU負荷 | 非常に低い(RDMAによりオフロード) | 高い(TCP/IPスタック処理) |
| 信頼性 | ロスレス通信(パケットロスなし) | パケットロスが発生する可能性あり |
| コスト | 比較的高価(専用NIC/スイッチが必要) | 比較的安価(汎用的なスイッチで構成可能) |
2-1. ポイント1:超高速な通信を可能とする帯域幅
Ethernetも着実に進化していますが、GPUクラスタのような実運用環境では、依然としてInfiniBandが安定した実効性能を発揮するケースが多く見られます。
InfiniBandは、常に最先端の通信速度を追求してきたインターコネクト技術です。たとえば、NVIDIAのConnectX-7(NDR世代)ではポートあたり400Gb/sの帯域幅を実現しており、さらに次世代のConnectX-8(XDR世代)では800Gb/sに達します。
一方、Ethernetも急速に進化しており、2024年2月にIEEE 802.3df標準が正式に標準化されており、IEEE P802.3djタスクフォースでは1.6Tb/s(1.6テラビット)Ethernetの標準化が進行中です。ただし、これらの超高速Ethernetは主にAI/MLクラスタや大規模データセンター間接続向けであり、一般的なデータセンターでは100GbE~400GbEが主流です。
2-2. ポイント2:分散処理の効率化を可能とする低遅延(レイテンシ)
分散学習のように同期処理が頻繁に発生する環境では、Ethernetよりも低遅延なInfiniBandの方が有利です。InfiniBandは、数マイクロ秒という極めて低い遅延を実現しており、最新のConnectX-7では「sub-microsecond」(1マイクロ秒未満)の遅延性能を提供します。
一方で、Ethernetの遅延は通常数十マイクロ秒に及び、InfiniBandと比較すると桁違いの差があります。分散学習では、各GPUが計算した学習の更新量を揃えるための同期通信(All-Reduceなど)が頻繁に発生するため、この差が学習時間に大きく影響します。
2-3. ポイント3:CPU負荷を最小化するRDMA通信
Ethernetは汎用的なTCP/IPプロトコルを用いて通信するため、通信処理時にOSのカーネル(TCP/IPスタック)が介在し、CPUに大きな負荷をかける構造になっています。
一方、InfiniBandは上述したRDMAをネイティブでサポートしており、OSやCPUを介さず、アプリケーションが直接リモートメモリにアクセスできます。
これにより、通信時のCPU使用率が大幅に低減され、CPUリソースを前処理やデータ変換などの本来の演算処理に集中させることが可能になります。とくにAI学習や推論といった高負荷なワークロードでは、この差が最終的なスループットや処理効率の決定的な違いにつながります。
2-4. ポイント4:安定したデータ転送を可能とするロスレス通信と信頼性
InfiniBandは、クレジットベースのフロー制御というメカニズムにより、ネットワーク内でのデータ衝突やパケットロスが発生しないロスレス通信を前提とした設計になっています。この仕組みでは、送信側が受信側のバッファ残量を事前に把握し、受信可能な分だけを送信することで、パケットの取りこぼしが原理的に発生しないようになっています。
ただし、これは帯域幅が十分に確保されていることが前提です。帯域幅が十分に確保されない環境下で、All-to-AllやAll-Reduceなどの高負荷な同期処理を行うと、大きくパフォーマンスが落ちるリスクもあります。
一方、Ethernetではパケットロスや再送が発生する可能性があり、構成によっては通信の再送処理が性能に悪影響を与えることがあります。
分散学習や大規模並列処理では、1ノードの通信遅延が全体の処理速度に波及するため、ネットワーク接続方式がシステム全体のパフォーマンスを左右する重要な要素となります。
常に100点満点の選択肢が存在するわけではなく、利用できる帯域や実装要件によって、InfiniBand/Ethernetのどちらを選定するのが良いかはケースバイケースで判断が必要です。ネットワーク設計にお悩みの方は、NTTPCエンジニアまでお申し付けください。
2-5. ポイント5:ROIを高める高性能設計とコストのバランス
InfiniBandは、専用のスイッチやアダプタが必要となるため、Ethernetに比べて初期導入コストが高いという側面があります。しかしその一方で、AIやHPCといった高負荷な用途では、InfiniBandの高性能・低遅延・ロスレス通信の恩恵により、学習時間や処理時間の大幅短縮が実現され、結果として投資対効果(ROI)が高くなるケースも少なくありません。
Ethernetは非常に安価かつ汎用性に優れ、あらゆるネットワーク環境で広く採用されています。しかし、ロスレス通信をハードウェアレベルで前提としたInfiniBandの設計思想は、安定性と性能の両面で優れています。とくにGPUクラスタやスーパーコンピューターのように性能が事業成果に直結する環境では、InfiniBandが最適な選択肢となる場面が多いといえるでしょう。
ここまでのポイントをふまえ、階層毎にEthernetのInfiniBandとの差分をまとめると下表の通りです。
■Ethernet vs InfiniBand
| 概念 | Ethernetの世界 | InfiniBandの世界 |
|---|---|---|
| 物理層 | 長距離対応の銅線/光ファイバを使用。QSFP/OSFP光モジュール、PAM4+FECで長距離信号を安定化。ただし消費電力は高め。 | 短〜中距離の差動SerDesを使用。低遅延・高効率設計で、400G光モジュールをPHY層で再利用可能。ケーブルは主にDAC/光ファイバ。 |
| リンク層 | Ethernet MACフレーム+CRC。オートネゴシエーションあり。パケットロスは上位層で再送制御。 | InfiniBandフレーム(IBパケット)+CRC+再送。クレジットベース制御でロスレス通信を保証。決定論的なレイテンシを実現。 |
| ネットワーク層 | IPアドレス指定とルーティング(BGP/OSPFなど)。マルチホップ経路・サブネット・ECMPによる負荷分散をサポート。 | サブネットマネージャ(Subnet Manager, SM)がローカルファブリック内ルーティングを管理。IPスタック不要、ポートベース静的経路。 |
| トランスポート層 | TCP/UDPが信頼性とフロー制御を提供。RDMA/RoCEによりゼロコピーGPU通信を実現。ただし輻そう時に可変レイテンシ。 | 信頼性と順序制御はInfiniBandハードウェアで実装済み。RDMA verbsによりCPU介在なしで直接GPUメモリ通信を実現。 |
| フロー制御 | PAUSEフレーム、PFC、ECNにより輻そう制御を行うが、ヘッドオブラインブロッキング(HoL)を発生させることがある。 | クレジットベースフロー制御と仮想チャネル (VC) により輻そうとオーバーランを防止。カットスルー転送により低遅延。 |
| 信頼性 | TCP再送や物理層FECでエラー回復。ただし再送で数ms単位の遅延が発生する可能性あり。 | リンク単位CRC+再送バッファ(ACK/NAK) でマイクロ秒単位のエラー回復。エンドツーエンド再送は不要。 |
| QoS | VLAN、DSCP、802.1p優先度などによりサービス分離とトラフィック制御を行う。 | 仮想チャネル (Virtual Channel) とサービスレベル (SL) により制御トラフィックとデータを分離。ファブリック内部でQoSをハードウェア実装。 |
| 管理 | SNMP、gNMI、NetFlow、CLIなどを使用し、各ノードを分散的に監視・管理。 | Subnet ManagerとNVIDIA UFM (Unified Fabric Manager) によりリンク状態、エラー統計、再送、パーティションを集中管理。 |
| API / アプリケーション層 | ソケット、HTTP、MPI、RDMA verbsなど、CPU駆動のI/O抽象化を経由して通信。 | MPI over InfiniBand、CUDA、NCCL、NVSHMEMなどがGPUネイティブ通信を実現。RDMAを通じてGPU間メモリ共有・集団通信を実施。 |
また、InfiniBandとEthernetの性能差が、実際の学習速度にどのような影響を及ぼすかは、以下の記事で検証しています。ぜひご覧ください。
▶︎ InfiniBandを用いたGPU環境検証
3. InfiniBandの主要技術とは
Ethernetとの違いを確認したうえで、次にInfiniBandが優位性を持つ理由を支える主要技術を見ていきます。InfiniBandの圧倒的な性能は、従来のネットワーク技術とは根本的に異なる独自のアーキテクチャと、スイッチドファブリック、RDMA、GPU Direct RDMAという3つの中核技術によって支えられています。これらが密接に連携することで、超高速・低遅延かつ高効率な通信を実現しています。
ここでは、3つの主要技術について順に解説していきます。
3-1. スイッチドファブリックアーキテクチャ
InfiniBandは、複数のノード(サーバー)がスイッチを介して相互に接続されるスイッチドファブリックアーキテクチャを採用しています。Ethernetとは異なり、すべての通信は各ノードのアダプタから開始・終了し、スイッチを通じてpoint-to-pointで通信が行われます。
この設計により、特定の通信が他の通信を妨げることがなく、複数のノード間で同時に最大限の帯域幅を利用した通信が可能となり、極めて高い集約帯域幅を提供します。
3-2. RDMA(Remote Direct Memory Access)とGPU Direct RDMA
RDMAは、2台のコンピュータ間でOSやCPUを介さずに、アプリケーションが直接お互いのメインメモリ間でデータをやり取りできる技術です。
通常のTCP/IP通信では、データを受信する際にOS(カーネル)が介在し、CPUリソースを消費しながらデータを適切なアプリケーションにコピーする処理が必要です。しかしRDMAでは、ネットワークアダプタがこの処理を肩代わり(オフロード)し、直接アプリケーションのメモリ空間にデータを書き込みます。これにより、以下の3つのメリットが生まれます。
【メリット】
- 低遅延: OSやCPUを介さずに処理することで、データ転送時の待機時間(レイテンシ)を抑制
- 高スループット: ネットワーク処理のボトルネックを解消し、ハードウェアの持つ性能を最大限に発揮
- 低CPU負荷: 通信処理をCPUから切り離すことで、CPUリソースは本来の計算処理に集中
RDMAの応用技術:GPU Direct RDMA
このRDMAをさらにGPU向けに特化・拡張したのが、NVIDIA独自の「GPU Direct RDMA」です。
従来のデータ転送では、GPUメモリ上のデータを一度CPUのメインメモリにコピーし、そこからRDMAを使って相手のCPUメインメモリへ転送、最後に相手のGPUメモリへコピーするという手順を踏んでいました。GPU Direct RDMAでは、この中間ステップを完全に省略し、一方のGPUメモリからネットワークアダプタ(ConnectX®)を介して、直接相手のGPUメモリへデータを転送します。
この、CPUとシステムメモリをバイパスする効率的なデータ転送経路を示したのが以下の図です。
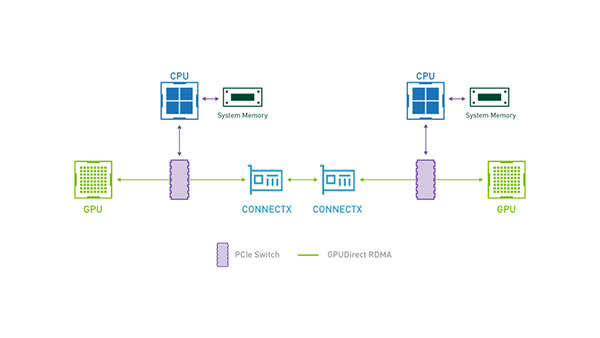
4. InfiniBandの性能を最大化するネットワーク設計
前述のようなInfiniBandの優れた要素技術は、GPUクラスタ全体の通信性能を大きく引き上げるポテンシャルを備えています。
しかし、その真価を発揮するには、それらを結ぶネットワーク設計そのものが適切であることが前提です。
特に、数百〜数千台規模のGPUノードが並列に連携する大規模クラスタでは、ノード間通信のボトルネックをいかに回避し、効率よくデータを流せるかが、全体の演算性能や学習時間に直結します。
そのため、InfiniBandネットワークの構成においては、「ネットワークトポロジ」と「In-Network Computing」という2つの設計概念が非常に重要になります。
4-1. ネットワークトポロジ:Fat Tree
ネットワークトポロジとは、ノード(例:GPUサーバー)やスイッチの接続構造を指します。InfiniBandクラスタでは、代表的なトポロジとして「Fat Tree」などが採用されています。
- Fat Tree(ファットツリー):文字通り「太い幹を持つ木」のような階層構造を持つトポロジであるAI/HPCクラスタの標準構成Fat Treeは、リーフスイッチとスパインスイッチによる階層型構造で、どのサーバー間でも均等な帯域が確保されるノンブロッキングな設計が可能です。このため、All-to-All通信のような負荷の高い通信パターンでも性能が安定し、AIの分散学習やHPC用途で広く採用されています。
4-2. In-Network Computing:SHARP
In-Network Computing(インネットワーク・コンピューティング)とは、データの中継だけでなく、ネットワーク機器自身が通信経路上で計算処理を行うという、InfiniBandが持つ先進的なアプローチです。この代表例が、NVIDIA Quantumスイッチに実装されている「SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)」です。
従来のAll-Reduceのボトルネック
AIの分散学習では、各GPUが計算した勾配データを全体で集約・平均化するAll-Reduceが頻繁に発生します。従来のネットワーク構成では、この処理は以下のような流れで行われ、ルートノード(集約ノード)への通信集中が大きなボトルネックとなっていました。
【処理の流れ】
- 各ノードからのデータがスイッチに送信される
- スイッチ自身がデータをその場で集約・計算(Reduction)
- 集約済みの結果が次のスイッチに送られ、階層的に最終結果が構築される
- 完成した結果が全ノードに配信される
SHARPによるAll-Reduceのボトルネックを解消
一方、SHARPを活用したAll-Reduceでは、演算処理をネットワークスイッチ内で分散的に実行することが可能です。これにより、ルートノードへの通信集中を避けつつ、All-Reduceの処理そのものは変えずに、そのボトルネックを大幅に緩和できます。
【処理の流れ】
- 各GPUが勾配データをルートノードへ送信
- ルートノードのCPUまたはGPUがすべてのデータを集約・演算
- 結果を全GPUにブロードキャスト

このように、CPU/GPUを介さずにネットワーク内で計算が完了するため、データ転送量を劇的に削減し、All-Reduceのレイテンシを大幅に短縮できます。この高速な集約処理により、GPUは待機時間なしで次のステップに移行でき、全体の学習スループットを大幅に向上させることが可能になります。
ここまで見てきたように、InfiniBandは単なる高速なデータ転送路にとどまらず、Fat Treeに代表される効率的なネットワークトポロジや、SHARPのようにネットワーク自体が演算処理を担う先進的な仕組みを通じて、GPUクラスタ全体の通信効率と計算性能を最適化する高度な機能を備えています。
こうしたネットワーク技術は、AI開発の現場において、分散学習の高速化やインフラの安定運用に直結する極めて重要な要素となっています。
実際のGPUクラスタ構成や、導入・運用におけるポイントについては、以下の記事でより詳しく解説しています。ぜひあわせてご覧ください。
▶︎ 生成AI/LLMの開発・学習に欠かせないGPUクラスタについて
5. NVIDIAの提供するInfiniBandプラットフォーム

ここまで見てきたように、InfiniBandは帯域幅・低遅延・低CPU負荷・信頼性・コストといったあらゆる観点で、GPUクラスタの性能を大きく左右します。しかし、こうした通信技術のポテンシャルを実環境で最大限に引き出すためには、基盤となる通信方式だけでなく、それを構成する周辺要素までも含めた“設計全体”が重要です。そこでNVIDIAは、InfiniBandの性能を最大限活かすために、スイッチ・アダプタ・DPU・ケーブルに加え、通信プロトコルや運用管理ツールまでを統合的に設計したプラットフォームを提供しています。
NVIDIA InfiniBandプラットフォームは、次のような価値を提供します。
- UFM(Unified Fabric Manager)による統合管理:数千ノード規模のGPUクラスタを対象とした効率的な監視・運用
- NCCL + SHARP の連携による通信最適化:集合通信(All-Reduce)の大幅な高速化を実現
- 高い柔軟性と投資保護:旧世代との下位互換性と段階的なスケーラビリティにより、拡張も容易
このように、InfiniBandは単なる高速インターコネクトではなく、AI・HPCの基盤全体の効率性と柔軟性を高める“トータルインフラ”として機能するよう設計されています。
5-1. 世代別プラットフォーム性能比較

AIやHPCのさらなる高負荷化・大規模化に対応するため、InfiniBandプラットフォームは世代ごとに段階的な進化を遂げています。
その中でも代表的なのが、Quantum-2(400Gb/s世代)と、次世代として登場したQuantum-X800(800Gb/s世代)です。
以下に、それぞれの世代のアーキテクチャの特徴や主要コンポーネントの違いをまとめました。
| 比較項目 | Quantum-X800プラットフォーム (800Gb/s世代) | Quantum-2プラットフォーム (400Gb/s世代) |
|---|---|---|
| コンセプト | 次世代生成AI向け800Gb/sアクセラレータ、トリリオンパラメータ規模のLLM訓練向け | エクサスケールAIのための性能であり、大規模な科学技術計算にも対応 |
| スイッチ | 144ポート(800Gb/s)を72 OSFPケージで提供、Quantum-3 ASIC搭載 | 64ポート(400Gb/s)を32 OSFPコネクタで提供、51.2Tb/sの双方向スループット |
| アダプタ | ConnectX-8 SuperNIC (800Gb/s, PCIe Gen6) | ConnectX-7 (400Gb/s, PCIe Gen5/Gen4) |
| AI加速技術 | SHARPv4 | SHARPv3 |
| 接続アーキテクチャ | 最小2段のFat Treeで10,000ノード超を接続 | 3-hop Dragonfly+で100万ノード超を接続 |
| その他の特長 | Silicon Photonicsによる高い電力効率 (参考: NVIDIA Quantum-X800公式ページ) |
複数テナント対応、MPI_Alltoallハードウェア加速 (参考: NVIDIA Quantum-2公式ページ) |
Quantum-X800は800Gb/sの次世代スループットに対応し、Co-Packaged Silicon Photonicsにより高い電力効率と集積密度を両立しています。特に、SHARPv4はネットワークインフラ上でAI計算を分散処理できる第4世代技術であり、従来を大きく上回る効率でLLMのトレーニングを可能にします。
このように、InfiniBandプラットフォームは帯域幅の向上にとどまらず、AIやHPCの進化に即したネットワーク全体の最適化へと発展を遂げています。
6. まとめ
本記事では、AI・HPC時代のデータセンターを支える重要なネットワーク技術「InfiniBand」について、その基本概念から核心技術であるRDMA・スイッチドファブリック・チャネルアダプタ、Ethernetとの違い、そしてInfiniBandプラットフォームの世代別の紹介まで包括的に解説しました。
RDMAによるCPUバイパス型のメモリアクセスや、GPU Direct RDMAによるGPU間の高速通信、さらにエンドツーエンドで最適化されたプラットフォーム設計によって、InfiniBandは従来のEthernetでは到達できなかった通信性能と運用効率を実現しています。このような革新的なネットワーク基盤は、AI開発者や研究者はもちろん、企業のデータサイエンティストやITインフラ担当者にとっても、最先端の計算リソースへのアクセスを加速させる原動力となります。
このように、InfiniBandは単なる通信技術にとどまらず、次世代のAI・HPCインフラを支える中核的なネットワーク基盤となりつつあります。新たな技術は当社でも今後検証予定です。InfiniBandを中核とした高性能な計算基盤の導入やGPUクラスタをご検討の際は、構築ノウハウと実績を兼ね備えたNTTPCにぜひご相談ください。
▶︎ お問い合わせはこちら
※NVIDIA、NVIDIA ConnectX、GPU Direct、CUDAは、米国およびその他の国におけるNVIDIA Corporationの商標または登録商標です。
※InfiniBandは、InfiniBand(R) Trade Associationの商標です。
※本記事は2025年10月時点の情報に基づいています。製品に関わる情報等は予告なく変更される場合がありますので、あらかじめご了承ください。メーカーが公表している最新の情報が優先されます。