



基礎知識
セキュア×高速!ローカルLLMが変える企業AI活用とデータガバナンス最前線
2025.12.23

GPUエンジニア

生成AIのビジネス活用が急速に進む一方、クラウドベースのAIサービスを利用する際に「情報漏えいリスク」や「高額なAPI利用料」、「レスポンスの遅延」などを懸念されている方も多いのではないでしょうか。特に機密情報や個人情報を扱う業務では、外部サービスの利用はデータガバナンスの観点から大きなハードルとなっていました。
このような課題を根本から解決するアプローチとして、自身の保有するマシン上(オンプレ環境で)でLLMを動作させる「ローカルLLM」が今、大きな注目を集めています。
本記事では、クラウドベースのLLMの課題を解決するローカルLLMの核心的なメリットから、導入・運用におけるデータガバナンス上の注意点、さらには企業活用がもたらす未来の姿までを網羅的に解説します。
目次:
- ローカルLLMとは?
1-1. クラウドLLMとは? - ローカルLLMとクラウドLLMの違い
- ローカルLLMの4つのメリット
- ローカルLLM導入手順:構築から選定までを解説
4-1. 構築に必要な要素
4-2. 実行環境の選択(オンプレミス or クラウド・ソフトウェア基盤)
4-3. モデルの選定
4-4. 計算リソースの選定 - ローカルLLM導入時のガバナンスのポイント
5-1. AI利用ガイドラインとセキュリティポリシーの策定
5-2. ハルシネーション対策と品質評価体制の構築
5-3. 法的・倫理的配慮と責任あるAIの推進
5-4. 人材育成と全社的なAIリテラシー向上 - ローカルLLMの活用事例
6-1. 三重大学とNTT西日本が医療DX推進に向けた包括連携協定を締結
~NTT版LLM「tsuzumi」による電子カルテ要約の実証実験を開始~
6-2. 機微データを扱う業務への大規模言語モデル「tsuzumi」活用に関する実証実験を開始 - まとめ
1. ローカルLLMとは?
ローカルLLM(Large Language Model:大規模言語モデル)とは、外部のクラウドLLMサービス(例:ChatGPTなど)を利用するのではなく、自社が選定した環境上でモデルを直接保持・実行する方式を指します。
データを外部に送信することなく、マシン内で処理を完結できるため、機密情報の漏えいリスクを大幅に抑えられるのがローカルLLMの大きな特徴です。
特に、顧客情報・診療データ・行政文書など機密性の高いテキストデータを扱う企業や、金融機関・医療機関・官公庁など高度なセキュリティやガバナンスが求められる分野での利用が進んでいます。また、最近では画像生成や音声認識など、マルチモーダルなAI処理をローカル環境で行いたいというニーズも増えており、生成AIのローカル運用全般を支える基盤として注目が集まっています。
1-1. クラウドLLMとは?
ローカルLLMが注目を集める背景には、クラウドLLMの急速な普及と、それに伴って浮き彫りになった課題があります。
そもそもクラウドLLMとは、外部のクラウドサーバーを利用して大規模言語モデルを稼働させる方式を指します。たとえば、ChatGPT(OpenAI)やClaude(Anthropic)に代表されるクラウドLLMは、インターネット経由で高性能なAIモデルを手軽に利用できる仕組みです。初期コストも低く、APIやWebインターフェースを通じてすぐに業務へ導入できる利便性から、日本国内でも急速に活用が広がっています。
2. ローカルLLMとクラウドLLMの違い
クラウドLLMの普及が進む一方で、データの安全性や業務要件との適合性といった観点から、導入を慎重に検討せざるを得ないケースも少なくありません。この場合には、ローカルLLMが有力な選択肢となります。

ローカルLLMとクラウドLLMのイメージ画像
以下に、ローカルLLMとクラウドLLMの主な違いを整理しました。
| 比較項目 | ローカルLLM | クラウドLLM |
|---|---|---|
| データの送信先 | 自社ネットワーク内で完結 | 外部クラウド(インターネット経由) |
| セキュリティ | ネットワーク的に物理的隔離も可能 | 通信・保存の暗号化が前提 |
| カスタマイズ性 | モデル自体を選定・制御可能 | プロンプト調整が中心 |
| 導入の手軽さ | インフラ整備と導入が必要 | 非常に高い(即利用可能) |
| 利用コスト | 初期投資が大きいが長期的には抑えやすい | 月額課金(API課金等) |
このようにクラウドLLMは、手軽に導入できる一方で、「データを外部に送信する」という性質上の制約があります。こうした制約に対して、「自社環境内で安全に運用できるLLM」がメリットとなり、使用される例が増えています。
3. ローカルLLMの4つのメリット
ここでは、ローカルLLM(オンプレミス環境)がもたらす4つの核心的なメリットを、クラウドLLMが抱える課題と対比させながら具体的に解説します。
メリット1:高セキュリティとデータガバナンス
クラウドサービスを利用する際に常に付きまとうのが、情報漏えいのリスクです。
たとえば、プロンプトに入力した機密情報が、知らないうちに外部のサーバーに送られたり、AIの学習に使われてしまったりすることを心配されている方もいると思います。「外部にデータを送信しない」というオプションを選択できるサービスもあるとはいえ、厳しい業界ルールや社内規定がある企業では、LLMの利用に制限をかけているという話も耳にします。
ローカルLLMは、AIがオンプレミス環境や閉域ネットワーク内で動作するため、外部へのデータ送信が発生せず、情報漏えいリスクを原理的に最小化できます
メリット2:複数のレスポンスの同時処理
クラウド上で提供されるLLMは、大規模な計算リソースを活用しておりトークン生成速度の面ではローカルLLMよりも優位なケースも多く見られます。
一方で、ローカルLLMはエンタープライズ向けGPU(例:NVIDIA H100等)を搭載したサーバーを利用することで複数のリクエストを同時に処理してもクラウドサービスに匹敵する速度を実現でき、結果的に効率を上げることができます。
また、社内ネットワーク内で完結するためインターネットの障害や遅延の影響を受けにくい点も強みです。
メリット3:ビジネスに合わせたカスタマイズ性
LLMを業務に合わせてカスタマイズするには、RAG(Retrieval-Augmented Generation)を活用するのが効果的です。
RAGは、外部のドキュメントやデータベースをLLMが理解することができるようになる技術で、モデル自体を再学習する必要がなく、管理が容易で効果も得やすいというメリットがあります。
クラウド上で提供されるLLMでもRAGは利用できますが、その場合は社内ドキュメントを外部にアップロードする必要があり、情報漏えいリスクが残ります。
一方、ローカルLLMとRAGを組み合わせれば、完全にローカルサーバー内の処理にのみ使用されるため、クラウド上で提供されるLLMと比べ安全に利用が可能です。これにより、クラウド上で提供されるLLMと同等の柔軟性を確保しながら、セキュリティ面で圧倒的に安心というメリットがあります。
メリット4:予測可能なコスト管理
クラウドLLMは、使った分だけ料金が増える従量課金が一般的です。少量利用なら安くても、開発やテストで試行回数が増えると一気にコストが膨らむことがあります。
その反面、ローカルLLMは、ハードウェアへの初期投資こそ必要ですが、一度環境を構築すれば、リクエスト数を気にすることなく定額で利用できます。そのため予算管理がしやすいこと、長期的に費用対効果が高くなりやすいことがメリットだといえるでしょう。
4. ローカルLLM導入手順:構築から選定までを解説
では、実際にローカルLLMを導入するには何から始めればよいのでしょうか。ここでは、導入形態の検討からハードウェアの選定まで、実践的な手順をご紹介します。
4-1. 構築に必要な要素
ローカルLLMを構築・運用するには、大きく分けて以下の3つの要素が必要です。
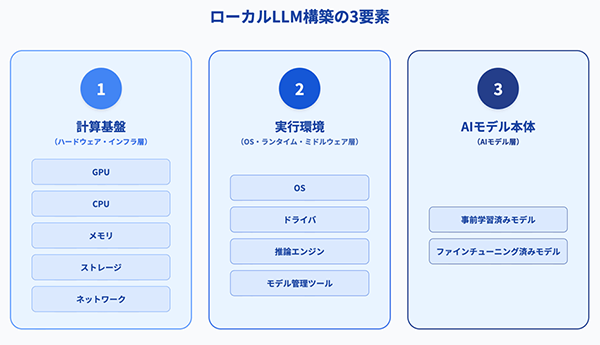
ローカルLLM構築の3要素
1. 計算基盤
LLMの推論処理を行うためのハードウェア。GPU(例:NVIDIA H200、NVIDIA B200 など)や、十分なメモリ・ストレージを備えたマシンが必要です。
2. 実行環境
LLMを動作させるためのソフトウェア基盤。主にOS(Linuxなど)、Python、CUDAなどのランタイムや依存ライブラリ群が含まれます。
3. AIモデル本体
ローカル環境で動作可能なLLM本体です。主に OSS(オープンソースソフトウェア)またはライセンス付きの事前学習済みモデルが使われます。代表的モデルには、MetaのLlamaシリーズ、Mistral AIの Mistral / Mixtralシリーズ、Googleの Gemma、Microsoftの phiシリーズなどがあり、いずれもローカル環境での実行が可能です。
4-2. 実行環境の選択(オンプレミス or クラウド・ソフトウェア基盤)
ローカルLLMとは、クラウドAPI型のLLM(例:ChatGPT)とは異なり、モデル本体を自社で保持・実行する方式です。とはいえ、実行環境はオンプレミスに限らず、クラウドIaaS上でも構築可能です。
インフラ基盤の選定(オンプレ or クラウド)
- オンプレミスで「所有」する方式
自社でGPUサーバーを調達・設置し、閉域ネットワークやオフライン環境で運用します。制御性・可用性・セキュリティ面に優れ、本番環境に適しています。 - クラウドIaaSで「一時的に借りる」方式
AWS・Azure・GCPなどが提供するGPU仮想マシンを使い、PoCや初期チューニングに活用する方式です。初期投資を抑えつつ、必要性能の見極めが可能です。
また、すぐに利用開始できるためオンプレミス環境の提供までの期間でクラウドをご利用いただくことで空白期間をなくすという使い方も適しています。
NTTPCではオンプレミス・クラウドどちらも提供が可能です。クラウドに関する詳細は以下からご覧ください。
関連製品:
▶ GPUプライベートクラウド™ソリューション
ソフトウェア基盤の構成
LLMを動かすには、ハードウェアだけでなく、以下のようなソフトウェア基盤の整備も必要です。
ローカルLLM推論環境のソフトウェア基盤
| カテゴリ | 内容 |
|---|---|
| OS | • Ubuntu 24.04 / Debian 系 Linux(推奨) |
| Python 実行環境 | • Python 3.10+ • PyTorch(GPUサポート付き) • Transformers(Hugging Face ライブラリ) • Accelerate(分散推論サポート) |
| GPU演算ライブラリ (NVIDIAの場合) |
• CUDA Toolkit 12.x • cuDNN 8.x • NCCL(マルチGPU通信ライブラリ) |
| 依存管理・仮想環境 | • venv / conda / poetry • Docker(推奨、環境汚染防止・再現性確保) |
| 推論エンジン / LLMラッパー |
• Ollama(ローカル LLaMA 系モデル用) • vLLM(高速バッチ推論対応) • LM Studio(GUIベースのローカルLLM実行環境) • Text Generation WebUI(Hugging Face モデルをローカルで動かすWeb GUI) |
4-3. モデルの選定
次に、使用するローカルLLMを選定します。用途や環境に応じて、さまざまなモデルがありますが、代表的なモデルの一部を下記にご紹介します。
| モデル(開発企業) | 特徴 |
|---|---|
| Llama(Meta) | オープンウェイトの代表格。派生モデルも豊富で、多くの用途に対応可能。 |
| Mistral(Mistral AI) | 小型でも高精度。「Mistral 7B」などが広く利用され、軽量環境にも適している。 |
| Gemma(Google) | Google製の軽量モデル。高品質かつ効率的で、研究用途や検証環境にも向いている。 |
| Phi(Microsoft) | 非常に小型で省リソース。簡易なローカル動作やエッジ環境での活用に適している。 |
| GPT-OSS | オープンウェイトのLLMモデル。カスタマイズ性が高く、研究用途でも適用可能。 |
| tsuzumi(NTT) | 日本語特化の国産モデル。小規模でも精度が高く、日本語環境でのローカルLLM用途に有望。 |
ライセンスについて
モデルにはMIT、Apache 2.0、独自ライセンスなどがあり、商用利用や再配布、実行要件に制限がある場合があります。利用前に必ず公式情報をご確認ください。
4-4. 計算リソースの選定
ローカルLLMを動かすうえで、高性能GPUを搭載したサーバーの選定は極めて重要です。中でも鍵となるのが「VRAM(ビデオメモリ)容量」です。
VRAMは、モデルの重みや推論中の中間データを保持する役割を担っており、容量が不足するとモデルを正常に読み込むことすらできません。大規模なモデルほど必要なVRAMも増えるため、用途や対象モデルに応じた設計が不可欠です。
またそれ以外にもGPUの演算性能、メモリ帯域幅なども考慮して計算リソースを選定する必要があります。
詳細は関連記事をご覧ください。
関連記事:
▶ データセンターGPU性能比較:指標別に見る製品の選定ポイント
ローカルLLMを活かすためのアプリ開発基盤
ローカルLLMを導入した後、業務に合わせたAIアプリを構築するには、Difyのようなオープンソースプラットフォームが有力な選択肢です。
Difyは、RAGやワークフロー構築をノーコードで実現でき、オンプレミス環境でも運用可能なため、セキュリティ要件を満たしつつ柔軟なAI活用を支援します。特に、社内データを安全に活用しながらAIアプリを開発できる点が、企業利用における大きな強みです。
5. ローカルLLM導入時のガバナンスのポイント
ローカルLLMは技術的に安全な環境を提供しますが、それを組織として正しく運用するための「ガバナンス※1」が伴わなければ、その価値は半減します。
ここでは、企業が押さえておきたい導入・運用のポイントについて解説します
※1ここでいう「ガバナンス」は、ローカルLLMを導入する際に組織として守るべきルールや管理体制のことを指します。責任範囲やリスク管理を明確にすることが重要です。
5-1. AI利用ガイドラインとセキュリティポリシーの策定
まずは誰が、何を、どのように使えるのかを明確に定めた利用ルールを作ることが重要です。このルールを定めることで、現場での混乱や意図しない不正利用を防止できます。ガイドラインには、次のような要素を盛り込むことが重要です。
【ガイドラインの要素】
- 機密情報・個人情報の取り扱いルール:入力禁止データや取り扱い条件を明記する。
- アクセス権限の管理:役職や部署に応じた利用範囲、申請・承認フローを設定する。
- インシデント対応手順:情報漏洩や不正利用が発生した際の報告ルートと対応プロセスを明文化する。
5-2. ハルシネーション対策と品質評価体制の構築
LLMには、もっともらしいが事実ではない情報(ハルシネーション)を生成するリスクが存在します。このリスクを組織として管理し、応答品質を維持・向上させるためには、以下のような仕組みが必要です。
【ハルシネーション対策の仕組み】
- ユーザーリテラシーの向上: 生成結果を鵜呑みにせず、必ず一次情報や信頼できるデータでファクトチェックを行う文化を浸透させる。
- 品質評価サイクルの構築: 定期的にモデルの応答精度を検証し、品質が期待値を下回れば、RAGの知識源更新やモデルの再チューニングを行うPDCAサイクルを実施する。
5-3. 法的・倫理的配慮と責任あるAIの推進
生成AIの活用は、著作権、個人情報保護、アルゴリズムバイアスなど、法的・倫理的な課題と密接に関わります。法令違反や不適切な利用を防ぐためには、次のような専門家を交えた監督体制が重要です。
【AI推進体制の要素】
- 法規制の遵守: 著作権法や個人情報保護法など、自社事業に関連する国内外の法規制に沿った利用を徹底する。
- 公平性の確保: 応答に偏りや差別的要素が含まれていないかを定期的に検証し、公平で透明性のある利用を推進する。
5-4. 人材育成と全社的なAIリテラシー向上
AIを安全かつ効果的に活用するには、一部の専門家だけでなく、全社員が適切に使いこなせる状態を目指す必要があります。そのために必要なのが以下のような対策です。
【人材育成と教育の要素】
- スキル開発: 高度なプロンプト作成スキルや、LLMを業務システムに統合する開発スキルを持つ人材を計画的に育成する。
- リテラシー教育: AIの仕組みや限界、潜在的リスクを全社員が理解できるよう、教育・研修の機会を提供する。
このように、技術的な導入だけでなく、組織全体でのガバナンス体制を整備することが、ローカルLLMを安全かつ効果的に活用するための鍵となるでしょう。
6. ローカルLLMの活用事例
ここでは、ローカルLLMが企業のどのような課題を解決し、実際にどのように使用されているのか、具体的な事例をご紹介します。
※NTTPCコミュニケーションズの事例だけでなく、業界全体の事例を含みます。
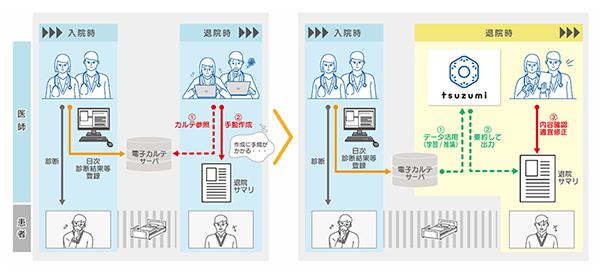
6-1. 三重大学とNTT西日本が医療DX推進に向けた包括連携協定を締結~NTT版LLM「tsuzumi🄬」による電子カルテ要約の実証実験を開始~
本実証では、医師の事務作業の1つである、患者の入院期間中の診療経過をまとめた「退院サマリ」(年間約1.5万件作成)の作成過程において、「tsuzumi」が生成した電子カルテの要約文章を活用することで、作成業務が効率化できるかを検証します。電子カルテデータを基に医師自らが文章を作成するのではなく、「tsuzumi」が生成した文章を医師が確認・修正することで、作成に要する時間を短縮しつつ、最終的なアウトプットの質を落さない業務フローの実現をめざします。
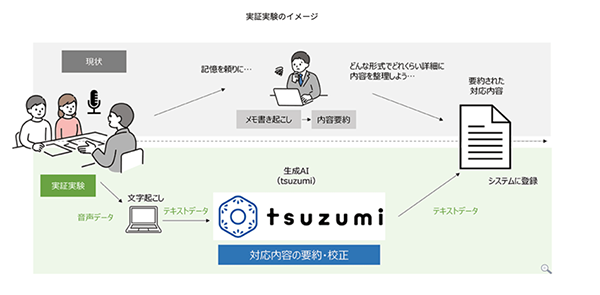
6-2. 機微データを扱う業務への大規模言語モデル「tsuzumi」活用に関する実証実験を開始
本実証実験では、機微なデータを扱うためにオンプレミス環境において小型のGPUサーバーで「tsuzumi」を動作させ、庁内の実データ活用を想定した実証を行います。
具体的な対象業務としては、業務上の機微なデータを扱う業務の対応記録の要約・校正や、各種業務マニュアルの検索・要約等を想定しています。
精度向上に向けて業務に特化したチューニング※4を行い、業務への適用性を高め、評価を行います。
7. まとめ
本記事では、ローカルLLMが企業にとって「セキュリティ要件」と「AI活用のしやすさ」という、相反する課題を同時に解決できる有力な選択肢であることを解説しました。
クラウドサービスのように手軽に導入することは難しい一方で、その導入ハードルを乗り越えれば、データを完全に自社で管理できる安心感、コストを計画的にコントロールできる柔軟性、そしてビジネスに合わせた自由なカスタマイズ性といった大きな価値を得ることができるでしょう。
そして、ローカルLLMの真価を引き出すには、導入形態の検討から、モデルの規模に見合った戦略的なGPUサーバーの選定まで、一貫した計画が不可欠です。お客さまのビジネスゴールに適したハードウェア構成については、ぜひNTTPCにご相談ください。
▶︎ お問い合わせはこちら
※「ChatGPT」は、米国Open AIの商標または登録商標です。
※「Claude」は、Anthropic社の商標または登録商標です。
※「NVIDIA」「NVIDIA H100」「NVIDIA H200」「NVIDIA B200」「CUDA」「cuDNN」はNVIDIA Corporation の商標または登録商標です。
※「Linux」は、Linus Torvalds氏の米国およびその他の国における商標または登録商標です。
※「Python」は、Python Software Foundationの商標または登録商標です。
※「Meta」「Llama」は、Meta Platforms, Inc.の商標または登録商標です。
※「Mistral AI」はMistral AIの商標または登録商標です。
※「Google」「Gemma」「GCP」はGoogle LLCの商標または登録商標です。
※「Microsoft」「Azure」はMicrosoft Corporationの商標または登録商標です。
※「Ubuntu」は、Canonical Ltd.の商標または登録商標です。
※「Debian」 は、 Software in the Public Interest, Inc. の登録商標です。
※「PyTorch」は、The Linux Foundationの商標または登録商標です。
※「conda」は、Anaconda, Inc.の商標または登録商標です。
※「Docker」はDocker, Inc.の商標または登録商標です。
※「Ollama」は、米国のOllama Inc.の商標または登録商標です。
※「vLLM」 は vLLM Project の商標です。
※「tsuzumi」はNTT株式会社の商標または登録商標です。
※「AWS」は、Amazon.com, Inc. またはその関連会社の商標です。