



基礎知識
「TensorRTとは?“AIが遅い”を解決する、NVIDIAの頭脳チューナー」
— AIがもっと速く、軽く、手の届く存在になるために —
2026.01.29

GPUエンジニア

あなたが使っているチャットAIや画像生成AI。
その「返答の速さ」や「描き出すスピード」は、実は「裏側の“頭の回転”」に左右されています。もしAIがほんの1〜2秒でも遅れたら、私たちは少しストレスを感じる。自動運転なら、その1秒の遅れが命取りにもなるかもしれません。
そんな“AIのスピード問題”を解決するのが、NVIDIAのTensorRT(テンソルアールティー)。
AIの頭脳を“賢く作り直す”ことで、同じGPUでも最大8倍速く動かしてしまう——。
本記事では、TensorRTの基本から、ビジネスにおいて不可欠とされる理由、AIを高速化する技術的仕組み、そして具体的な導入事例までを、わかりやすく解説します。
目次:
- TensorRTとは?AIモデルを“賢く”高速化する最適化エンジン
- AI推論の高速化がビジネスで重要視される3つの背景
2-1. 生成AI(LLM)の爆発的普及と運用コスト
2-2. 自動運転やスマート工場を支える「エッジAI」の台頭
2-3. ユーザー体験(UX)に直結する「応答速度」 - TensorRTによるAIモデルの高速化技術
3-1. 最適化の全体フロー:ONNX変換から推論エンジンの生成まで
3-2. 高速化を実現する3つのコア技術 - TensorRTのエコシステム:LLMからクラウドまで対応するツール群
4-1. TensorRT-LLM:大規模言語モデルの推論を高速化
4-2. TensorRT Model Optimizer:モデルの軽量化と最適化
4-3. TensorRT for RTX / Cloud:開発環境に応じたソリューション - TensorRTの導入効果:性能ベンチマークとコスト削減
5-1. 推論性能の向上:最大8倍の高速化を実現
5-2. TCO(総保有コスト)の削減効果 - TensorRTの企業における活用事例
6-1. 【Amazon】リアルタイム検索機能で顧客満足度を向上
6-2. 【Perplexity】:LLMの応答速度とコストを劇的に改善
6-3. 【Google Cloud】:大規模データ処理パイプラインを高速化 - まとめ
1. TensorRTとは?AIモデルを“賢く”高速化する最適化エンジン
TensorRT(テンソルアールティー)は、NVIDIAが提供するAIモデルを“賢く”高速化するためのソフトウェア開発キット(SDK)です。学習を終えたAIモデルを分析し、NVIDIAのGPU上で最も速く、最も効率的に動くように「作り変える」ことに特化しています。

TensorRTの役割は、「AIモデルを本番環境で実用化するための最適化」 です。具体的には、学習済みのモデル(PyTorchやTensorFlowなど)を入力すると、その演算グラフを解析し、ターゲットGPUの特性に合わせて次のような最適化を実行します。
- 量子化
→精度を落とさずに、数字の扱いを軽量化
「小数点まで細かく考えすぎないよう」処理を高速化 - レイヤー融合
→たくさんの小さな計算をまとめて処理
メモリアクセスの無駄を省いて一括実行 - カーネルチューニング
→GPUの種類ごとに最適なチューニング
GPUに合わせてハードウェア性能を最大化
その結果、モデル精度を可能な限り維持しながら、推論速度を大幅に向上させ、メモリ使用量や計算リソースを削減した「TensorRTエンジン」が生成されます。このエンジンを呼び出すことで、GPU性能を最大限に引き出した高速推論が可能になります。
2. AI推論の高速化がビジネスで重要視される3つの背景
AI開発には 「学習」と「推論」 の2つのフェーズがあります。学習は研究開発で行われますが、実際のサービス運用では推論が日々繰り返されます。高性能なモデルを開発できても、推論の段階で 処理速度・リソース・コスト の壁に直面し、本番導入が停滞するケースは少なくありません。では、なぜこの「推論の壁」が今これほどまでに深刻化しているのでしょうか。
背景には次の3つの市場トレンドがあります。
2-1. 生成AI(LLM)の爆発的普及と運用コスト
ChatGPTに代表される大規模言語モデル(LLM)は、多くのビジネスに革命をもたらす一方、その巨大さゆえに膨大な運用コストという課題を抱えています。ユーザーからの無数のリクエストにリアルタイムで応答し続けるためには、強力なGPUを常時稼働させる必要があります。推論処理をいかに効率化し、より少ないGPUで、より多くのユーザーをさばけるようにするか。これが、生成AIサービスの収益性を左右する喫緊の経営課題となっています。
2-2. 自動運転やスマート工場を支える「エッジAI」の台頭
AIの活躍の場は、クラウド上のサーバーから、自動車、ドローン、工場の生産ラインといった「現場(エッジデバイス上)」へと急速に拡大しています。これらのエッジデバイスでは、インターネットを介する通信の遅延が許されず、限られた電力とスペースの中でAIが瞬時に判断を下さなければなりません。学習済みの巨大なAIモデルを、現場のハードウェアで動くように軽量化・高速化する技術は、エッジAIの実現に不可欠な要素です。
2-3. ユーザー体験(UX)に直結する「応答速度」
AIアシスタント、リアルタイム翻訳、AIによる画像生成など、AIが消費者の日常に浸透するにつれ、その応答速度(レイテンシ)への要求はますます厳しくなっています。AIの反応がコンマ数秒遅れるだけで、ユーザーはストレスを感じ、サービスから離脱してしまう可能性があります。もはやAIの応答速度は単なる技術指標ではなく、サービスの品質、ひいては顧客満足度やブランドイメージを決定づける重要なビジネス指標となっています。
このように、推論段階で直面する コスト・リソース・速度の壁 は、いまや企業にとって避けて通れない課題となっています。その解決策の一つとして注目されているのが、 「TensorRT」なのです。
3. TensorRTによるAIモデルの高速化技術
ここでは、TensorRTがAIモデルを高速化する具体的なプロセスと、その中核をなす技術について詳しく解説します。
3-1. 最適化の全体フロー:ONNX変換から推論エンジンの生成まで
TensorRTを使ったAIの高速化は、一般的に次のような4ステップで進みます。
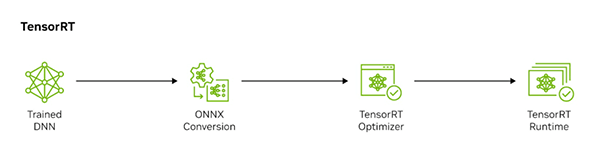
1. 学習済みモデルの作成
PyTorchやTensorFlowなどのフレームワークで学習させたAIモデル(DNN)を用意します。
2. モデルのONNX変換
フレームワークごとに形式が異なるモデルを、異なるAIフレームワーク間でモデルをやり取りできる標準フォーマットである「ONNX(Open Neural Network Exchange)」に変換します。これにより、TensorRTが様々なモデルを統一的に扱えるようになります。

3. TensorRTによる最適化
TensorRTはONNX形式のモデルを読み込み、その構造を解析します。そして、ターゲットとなるGPUに特化した最も効率的な実行プラン(TensorRTエンジン)へと変換・最適化を行います。
4. 推論実行
最適化されたTensorRTエンジンをPythonやC++などのプログラムから呼び出し、実際のデータを入力して高速な推論を実行します。
3-2. 高速化を実現する3つのコア技術
上記の最適化ステップにおいて、TensorRTは主に次の3つの技術を自動的に組み合わせ、モデルを高速化します。
1. 量子化 (Quantization)
量子化とは、AIモデルが扱うデータの精度を、性能に影響が出ない範囲で意図的に下げる技術です。AIモデルは通常「FP32(32ビット浮動小数点)」という高精度な数値で計算しますが、推論時にはより低い精度でも十分な性能を維持できることが多くあります。
そこで、数値をより軽量な「INT8(8ビット整数)」や「FP8(8ビット浮動小数点)」などに変換することで、モデルサイズを大幅に圧縮。メモリ使用量と計算負荷を削減し、処理速度を向上させます。
2. レイヤー融合とテンソル融合 (Layer and Tensor Fusion)
AIモデルは多数の演算層(レイヤー)で構成されています。これらを一つずつ個別に実行すると、その都度GPUメモリへの読み書きが発生し、大きなオーバーヘッドとなります。TensorRTは、連続する複数のレイヤーや、同じような処理を行うテンソル(データ配列)を一つにまとめ、一括で実行します。これにより、メモリアクセスの回数を劇的に減らし、中間結果の保存も不要になるため、処理時間とメモリ使用量を大幅に削減できます。
3. カーネルの自動チューニング (Kernel Auto-Tuning)
GPUは「カーネル」と呼ばれる小さなプログラムで演算を実行します。同じ処理でも、GPUの種類やデータサイズによって最も効率的なカーネルは異なります。TensorRTは、最適化の際にターゲットとなるGPUの特性を分析し、様々なカーネルの組み合わせを自動で試行します。その中から最も高速に処理できるパターンを選択することで、ハードウェアの性能を限界まで引き出す、オーダーメイドの実行プランを構築します。
4. TensorRTのエコシステム:LLMからクラウドまで対応するツール群
このようにTensorRTは非常に強力な最適化を行いますが、その能力は単体のツールにとどまりません。近年では、TensorRTは単体のライブラリにとどまらず、LLMからクラウドまで幅広い開発ニーズに対応する「エコシステム」 へと進化しています。ここからは、その主要なコンポーネントを紹介します。
4-1. TensorRT-LLM:大規模言語モデルの推論を高速化
現在のAIトレンドの中心である大規模言語モデル(LLM)の推論に特化したオープンソースライブラリです。標準的なPythonフレームワーク(PyTorchなど)で構築されたLLMの推論処理を劇的に高速化し、運用コストを削減します。チャットAIや文書生成AIといったサービスの根幹を支える重要な技術です。
4-2. TensorRT Model Optimizer:モデルの軽量化と最適化
学習済みモデルをTensorRTエンジンに変換する前処理として、モデルの軽量化(最適化)を行うためのツール群です。AIモデルの精度への影響を最小限に抑えながら、量子化(INT8/FP8への変換など)を実行し、モデルサイズを圧縮することで、推論の高速化とメモリ効率の向上に貢献します。
4-3. TensorRT for RTX / Cloud:開発環境に応じたソリューション
開発者の環境に応じたソリューションも提供されています。ゲーミングPCやワークステーションに搭載されるRTX GPU向けに最適化された「TensorRT for RTX」は、開発者が手元の環境で迅速に推論エンジンをビルドし、テストすることを可能にします。また、クラウド上で最適なエンジンを自動生成するサービス「TensorRT Cloud」も登場しています。
5. TensorRTの導入効果:性能ベンチマークとコスト削減
ここまで見てきたように、TensorRTはモデルの最適化や推論効率化を多角的に支援します。では、実際にどの程度の性能向上とコスト削減が期待できるのでしょうか。NVIDIAが公開している代表的なベンチマークデータ2つを見ていきます。
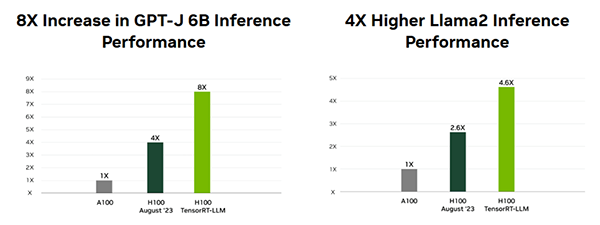
5-1. 推論性能の向上:最大8倍の高速化を実現
TensorRT、特に TensorRT-LLM は、NVIDIA H100 GPUと組み合わせることで、大規模言語モデルの推論を加速します。ベンチマークでは、GPT-Jで最大8倍、Llama 2で約4倍 の高速化が確認されており、最新GPUとの組み合わせによる最適化効果の大きさが示されています。
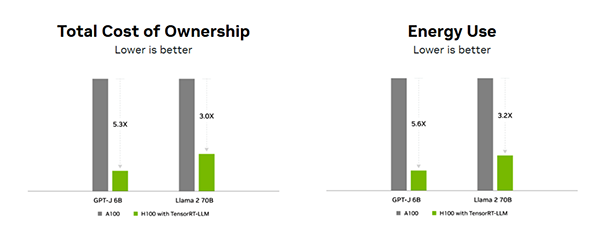
5-2. TCO(総保有コスト)の削減効果
この推論の高速化は、必要なGPU台数や稼働時間を大幅に減らし、クラウド利用料や電力消費といった運用コストを直接削減します。実際に大規模AIモデルでは、約3~5倍のTCO削減効果 が報告されており、AIサービスの収益性改善に直結しています。
TensorRTは推論性能を大幅に引き上げると同時に、GPU利用台数や稼働時間を削減し、クラウド費用や電力消費を含む運用コストを抑制します。こうしたメリットは理論上の話にとどまらず、すでに世界中のサービスで実際に成果を上げています。
6. TensorRTの企業における活用事例
TensorRTの圧倒的なパフォーマンスは、すでに世界中の様々なサービスで実用化され、具体的なビジネス価値を生み出しています。ここでは、先進的な企業がどのようにTensorRTを活用しているかその活用例を見ていきましょう。
※NTTPCコミュニケーションズの事例だけでなく、業界全体の事例を含みます。
6-1. 【Amazon】リアルタイム検索機能で顧客満足度を向上
世界最大級のECサイトAmazonでは、顧客が検索窓に入力したキーワードのスペルミスをAIがリアルタイムで自動修正する機能にTensorRTが活用されています。
Amazonは、自然言語処理モデル「T5」をNVIDIA Triton Inference ServerとTensorRTで高速化。これにより、推論スループットを5倍に向上させ、50ミリ秒以下のリアルタイム応答という厳しい要件をクリアしました。
この高速な応答により、顧客は探している商品をより迅速かつ簡単に見つけられるようになり、顧客満足度の向上に直接貢献しています。
6-2. 【Perplexity】:LLMの応答速度とコストを劇的に改善
最先端の対話型AI検索サービス「Perplexity AI」を提供するスタートアップPerplexityは、同社のAPI「pplx-api」の基盤にTensorRT-LLMを採用しています。 同社は、急成長に伴うLLMの推論コストの増大という課題に直面していましたが、NVIDIA A100/H100 GPU上でTensorRT-LLMによる最適化を徹底しました。
その結果、他のプラットフォームと比較してレイテンシを最大3.1倍低減し、さらにコストを4倍削減することに成功しました。これは年間60万ドルものコスト削減に相当します。
(参考: NVIDIA Blog – Accelerating Large Language Model Inference with NVIDIA in the Cloud)
6-3. 【Google Cloud】:大規模データ処理パイプラインを高速化
Google CloudはNVIDIAとの協業により、同社のデータ処理サービス「Dataflow」上でApache Beamを利用する開発者が、NVIDIA GPUとTensorRTをシームレスに利用できる連携機能を開発しました。 大規模なデータを扱う処理パイプライン内で、AIモデルによる推論が性能のボトルネックになるケースは少なくありません。 この連携により、開発者は複雑なコードを書くことなく、データ処理のワークフローにTensorRTで最適化されたAI推論を組み込めるようになりました。
ハードウェアの使用率を最大化し、トータルコストを抑えながら、データからより迅速に洞察を得ることが可能になります。
(参考: Google Cloud – Scaling machine learning inference with NVIDIA TensorRT and Google Dataflow)
7. まとめ
本記事では、AIモデルの実用化に不可欠な推論高速化エンジン「TensorRT」について、その基本からエコシステム、重要性が高まる背景、具体的な技術、そして導入事例までを網羅的に解説しました。生成AIやエッジAIの普及により、AIをただ開発するだけでなく、いかに高速かつ低コストで安定運用するかが、ビジネスの競争力を直接左右する時代になっています。TensorRTは、NVIDIA GPUの性能を最大限に引き出し、AIプロジェクトの「最後の壁」である推論パフォーマンスの問題を解決する強力なソリューションです。
最新のNVIDIA GPU導入やTensorRTの活用をご検討の際は、ぜひNTTPCにご相談ください。豊富な導入実績と専門知識を活かし、お客様のAIプロジェクトの成功に向けて、最適なソリューションをご提案いたします。
▶︎ お問い合わせはこちら
※NVIDIAは、米国およびその他の国におけるNVIDIA Corporationの商標または登録商標です。
※PyTorchは、The Linux Foundationの商標または登録商標です。
※TensorFlow、Google Cloudは、Google LLCの商標または登録商標です。
※Apache Beamは、Apache Software Foundationまたは米国その他の諸国における関連会社の商標です。
※本記事は2025年10月時点の情報に基づいています。製品に関わる情報等は予告なく変更される場合がありますので、あらかじめご了承ください。NVIDIAが公表している最新の情報が優先されます。