



技業LOG
NTTPCの生成AI業務変革LOG
- 活用事例/技術調査レポート -
本記事では、NTTPCが取り組む生成AIの活用事例や技術調査レポートをご紹介します。生成AIの導入により、私たちの業務やサービスの質が飛躍的に向上し、業務効率化や新たな価値創造を実現しています。
本記事を通じて、当社の生成AI活用の具体的な取り組み内容や技術的な調査結果を詳しくお伝えし、業務変革に対する積極的な姿勢を示すことで、お客さまの信頼と関心を得て、共に成長できるパートナーであることを目指しています。
目次
-
1.
-
2.
-
3.
-
4.
-
5.
-
6.
-
7.
1. はじめに
本記事ではDifyがどのようなサービスか、実際にどのように動作させるか、そしてローカル環境でDifyを実行する手順を簡潔に解説します(2025年9月時点の情報です)。
内容は弊社が独自に検証した結果であり、LangGenius社への確認は取っておりません。ご利用に際しては、最新の公式ドキュメントをご参照ください。
NTTPCではエンタープライズ領域でのAI活用に関し、弊社では自社の取り組みの中で培ってきたノウハウや、ハードウェア選定・構成に関する知見をご紹介しています。AI導入を検討される際の参考情報としてご覧いただければ幸いです。より詳しい情報が必要な場合は、状況に応じて営業部へお問い合わせください。
2. Difyとは
DifyとはオープンソースのAIアプリ開発プラットフォームです。
1つ目の特徴として、Webブラウザ上で誰でも簡単にノーコードもしくはローコードでAIアプリケーションを作ることができるものになっています。ただしDifyで作成したAIアプリケーションは基本的にはDifyの環境上でのみ動作するものになります。ここでのノーコードとはコーディングを行わずWebブラウザ上の操作のみでアプリケーションを作ることを指します。ローコードとはコーディングを行うもののアプリケーションの機能の一部のみをコーディングすることを指します。
2つ目の特徴として、AIモデルを含めてすべてローカルのマシン上で実行できる点があります。DifyにはセルフホストサービスのCommunity版というローカルでDifyの環境を実行できるものとWeb上で既に構築された環境にアクセスするクラウドサービスの2種類があります。それぞれのサービスに3つのプランが存在します。クラウドサービスではSandbox,Professional,Teamの3種類のサービスが展開されています。セルフホストサービスではCommunity,Premium,Enterpriseの3種類のサービスが展開されています。本記事では無料で使用可能なクラウドサービスのSandboxプランとセルフホストサービスのCommunityプランについてのみの紹介になります。
またAIの実行に関しても様々なモデルプロバイダーがサポートされていることでLLMなどを手元のマシン上のGPUで実行することもできます。他にもDifyにはRAGも搭載されているので、Community版を運用する際には完全にインターネットから切り離した状態で社内データを学習したAIをご自身でも構築が可能です。
3つ目の特徴として、複数種類のAIを組み合わせることが可能ということです。昨今では日々多くのLLMなどがHugging Face上などに公開されています。こうしたLLMを自由に組み合わせることでそれぞれのAIが得意とする分野に限定して用途別に組み合わせることができます。基本的にLLMとのチャットサービス等では1社が作ったAIのみ使用されることが多いのでこれはDify独自の強みだとも言えます。
4つ目の特徴として、RAGが搭載されていることです。RAGとはドキュメントファイルなどをドラッグ&ドロップするだけでAIがすぐにそれらのドキュメントの内容を踏まえた回答ができるようになる機能です。
また、RAGの機能はDifyの機能としてインストール時に自動的に導入されていますが、Rerankerといったドキュメントの検索精度を向上させるAIを導入することでより高度な検索によりAIにより正確な回答を行わせることもできます。
3. 用語解説
- LLM(Large Language Model l)
1つのAIで複数の言語処理ができるのが特徴。
翻訳・要約・質問への回答を自然な言語で行える。AIともよく言われる。 - RAG(Retrieval-Augmented Generation:検索拡張生成)
事前に用意した文書をLLMが参照する仕組み。
ドキュメントなどをそのまま参照することができる。 - Reranker
検索アルゴリズムの1種。RAGで使用することで、検索の精度が上がる。
一度必要文書から情報を検索した後に再度並べ替える。 - Docker
アプリケーションをコンテナという単位で分離・実行する仕組み。
どこでも同じ環境で動作させられるのが強み。 - Docker Compose
複数のDockerコンテナをまとめて定義・起動できるツール。
docker-compose.yaml に設定を記述し、環境を一括で管理できる。 - Fine-tuning(ファインチューニング)
既存のLLMに追加のデータを学習させ、特定用途に最適化する手法。
精度は上がるがコストや時間がかかる。 - chunk
RAGのために使用するドキュメントを分割すること。
改行や空白等のドキュメント内を一定の規則に従って分割する。 - Embedding-model(埋め込みモデル)
テキストや画像などのデータを数値ベクトルに変換するモデル。
Embedding-modelは文章や文字などの意味を数値で表すモデル
4. Dify環境の作り方(Sandboxプラン)
Web版にアクセスするにはDify Cloudと検索してにログインすれば使用可能です。
Githubアカウント・Googleアカウントもしくはメールアドレスでの認証でのログインが可能です。
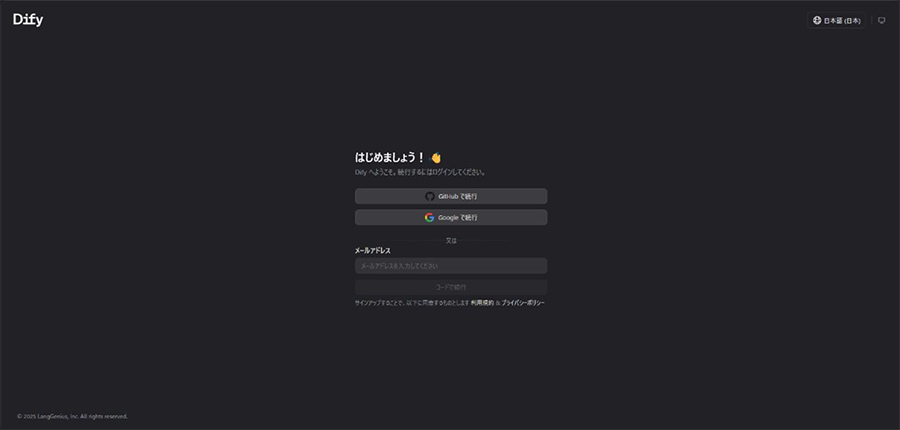
まずはSandboxプランからお試しいただけます。クレジットカード不要で200回のOpenAI APIコールを無料で試すことができます。クラウドサービスのSandboxプランのご利用には、GitHubまたはGoogleアカウント、および有効なOpenAI APIキーが必要です。
5. Dify環境の作り方(Communityプラン・ローカル実行)
セルフホストサービスのCommunity版はGitHub上に公開されている公式コンテナをローカル環境で実行することで実行できます。
LLMのモデルなどを使用する際には使用するモデルに依存しますが、Windows及びLinux(Ubuntu等)で大きなモデルを動作させるためにはVRAM容量の多いGPUとGPUドライバーが必要になってくる点に注意してください。
例としてはChatGPTのOpenAIがリリースしたモデルを例に挙げると次のVRAMが必要とされています。
gpt-oss-20B: VRAM 16GB
gpt-oss-120B: VRAM 80GB
参照元:
https://huggingface.co/openai/gpt-oss-20b
https://huggingface.co/openai/gpt-oss-120b
これだけではなくDifyでアプリケーションとして動作させる場合、これ以外にも複数のモデルを組み合わせて動作させる必要があります。そのためLLM単体を動作させるVRAM容量に余裕を持たせることがポイントとなります。
今回紹介する環境構築方法はCPUのみで実行できます。
また、ローカルLLMを使用する際にはモデルプロバイダーというものが必要になります。
Dify自体はLLMを直接持っていません。その代わりにモデルプロバイダーを通して、外部やローカルのモデルにアクセスを可能にします。
多くのモデルプロバイダーがサポートされていますが、今回はollamaを使った環境の作成方法について説明します。
Difyシステムの最小インストール要件
またDify インストール前に, マシンが下記の最小インストール要件を満たしていることを確認してください:
- CPU >= 2Core
- RAM >= 4GiB
また同じマシン上でollamaなどを使用する際にはこれ以上のスペックが必要になることを考慮していただければと思います。
OSごとの構成上の注意等
WSL 2を有効にしたWindows:
ソースコードやその他のデータをLinuxコンテナにバインドする際には、それらをWindowsファイルシステムではなくLinuxファイルシステムに保存することをお勧めします。
Linuxプラットフォーム:
詳細についてはDockerのインストールおよびDocker Composeのインストールを参照してください。
参考元:
Docker Compose デプロイ | Dify
Windowsでの準備
ここではWindows11での環境設定方法も前準備として記載します。
Difyを今回はコンテナとして実行するためDockerおよびDocker Composeが必要になります。
DockerはWSL2をベースとしたものであることがDify公式ドキュメントにおいて推奨されています。
今回はWSL2をベースとしたコンテナを簡単にインストールできるDocker Desktopのインストールでご紹介しますが、WSL2のLinux(Ubuntu)の中にDockerおよびDocker Composeをインストールしても動作します。ご自身の環境に合わせて使用いただければと思います。
初めてWindowsのWSL2バックエンドでコンテナを動作させる場合次の作業が必要になります。
-
1.
WSL2のインストール
[管理者として実行]を選択して管理者モードでPowerShellを開き、wsl --install コマンドを入力して、コンピューターを再起動します。
この際に自動的にUbuntuがインストールされます。
再起動後、Docker Desktopをインストールします。
参照
WSL のインストール | Microsoft Learn -
2.
Docker Desktop(Docker)のインストール
Docker DesktopはMicrosoft storeからの入手が最も簡単です。
Microsoft storeで Docker Desktop で検索します。
もしくは下記リンクへアクセスします。
Docker Desktop - Download and install on Windows | Microsoft Store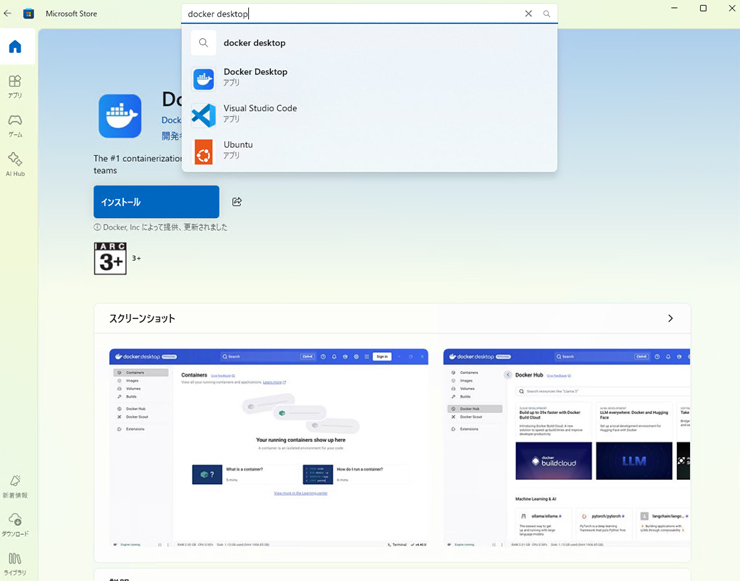
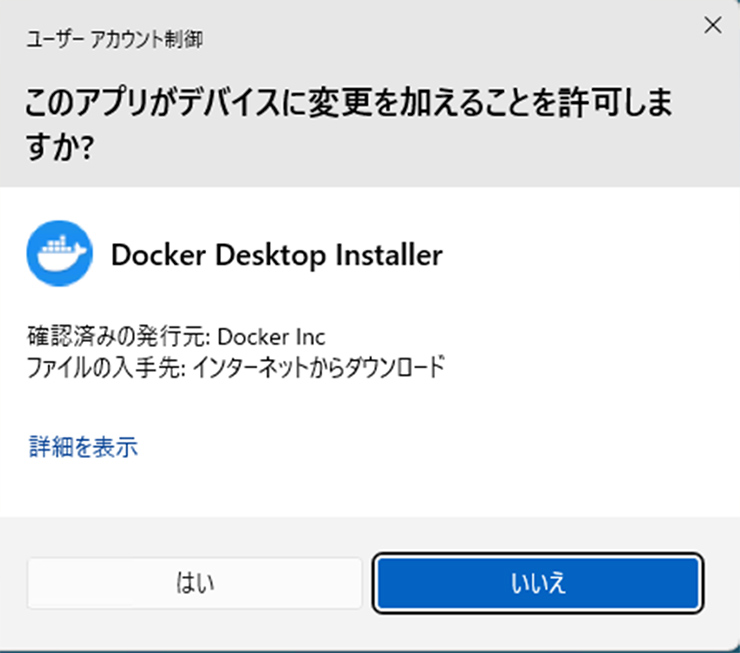
ダウンロードをクリックしてダウンロード完了です。
このアプリが変更を加えることを許可しますか?と表示された場合、「はい」を選択します。
ダウンロードが終了しインストーラーが起動するとこのような画面になります。
Use WSL 2 instead of Hyper-V(recommended)に必ずチェックを入れます。
その他は自由に設定して頂いて問題ありません。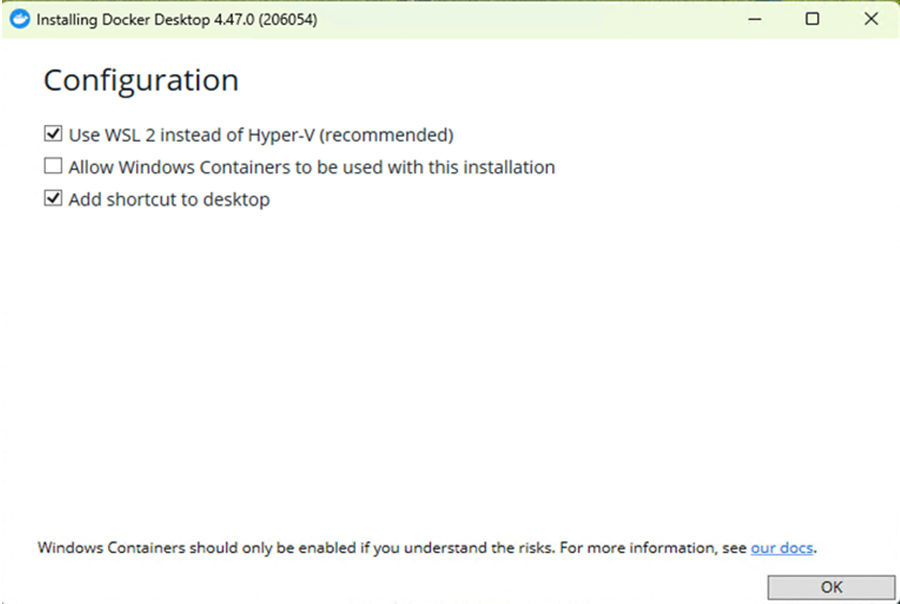
OKをクリックします。
インストールが開始されます。
インストールが完了するとこの画面になります。
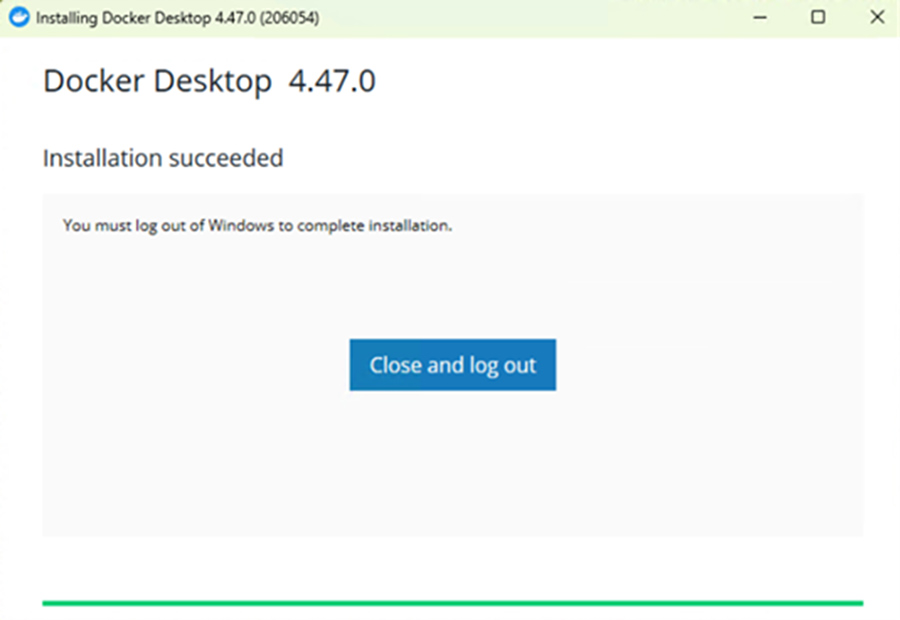
Close and logoutやrebootなどが表示されるのでクリックします。
再度WindowsにログインしDocker Desktopを起動します。
このような画面になりますが今回はログイン必要ありません。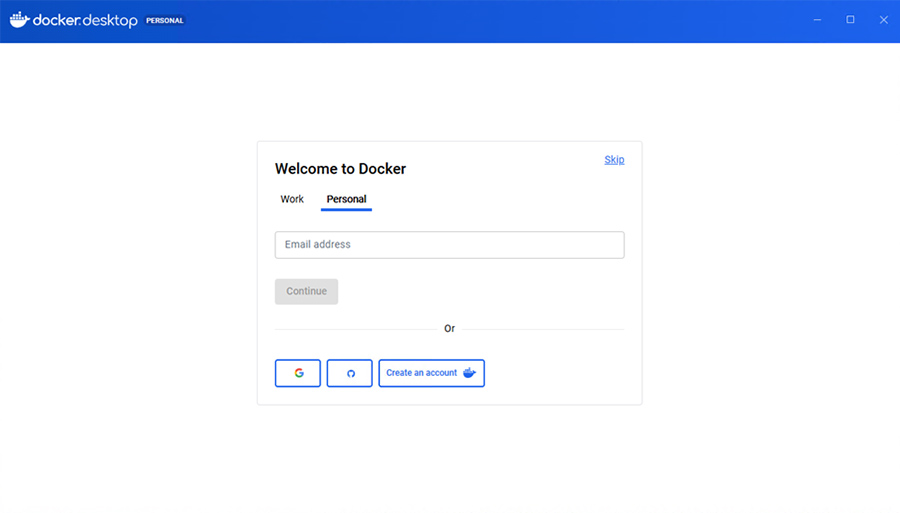
右上のskipをクリックします。
この画面になれば準備は完了です。
その他のインストール方法については公式ドキュメントを参照してください。
参考
Windows | Docker Docs
Docker Desktop とWSL2のubuntuとの連携
タブの+の隣のVをクリックするとこのようになります。
-
※タブがない場合Windows Terminalのバージョンが古い状態です。
こちらもWindows TerminalでMicrosoft Storeで最新版をダウンロードできます。
Ubuntuをクリックします。
これでWSL2のUbuntuが操作できます。
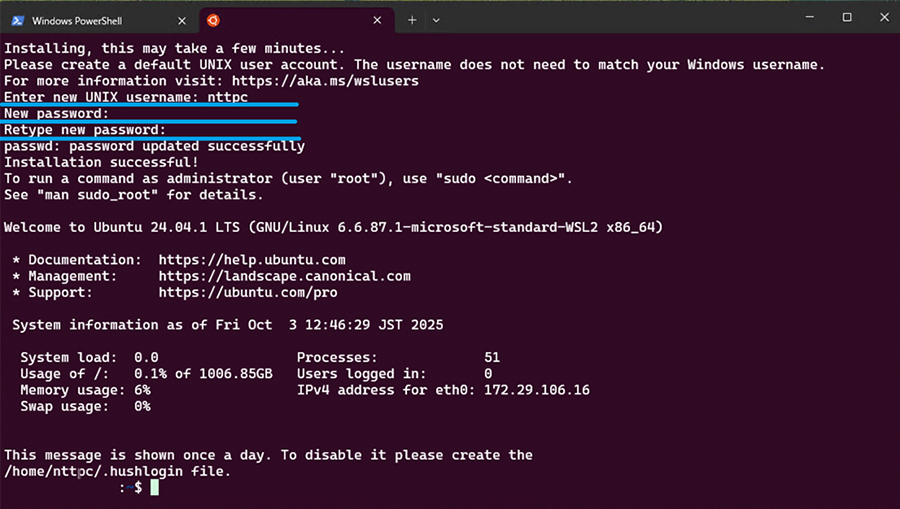
初回起動時はユーザー名とパスワードを入力する必要があります。
ここで一度Dockerが既にインストールされているか確認します。
$ docker -v $ docker-compose -v
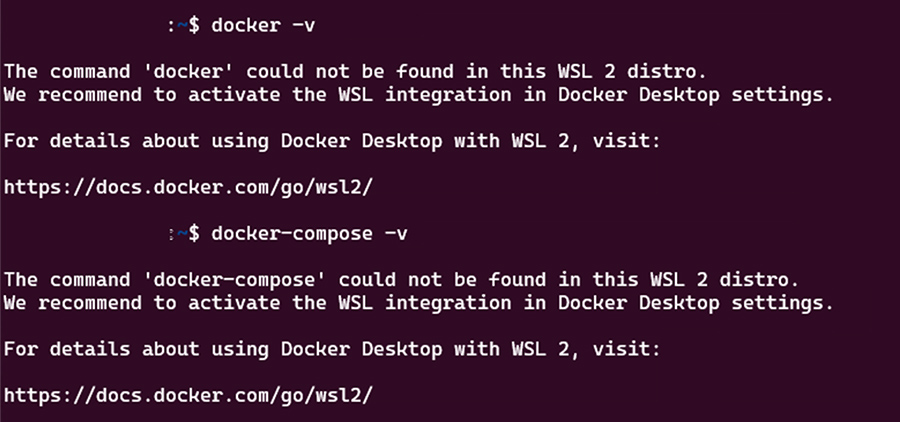
手順通り進めた場合このようにDocker DesktopをインストールしていてもWSL2内ではDockerが使用できない状態になっています。
標準でUbuntuを開くようにするには次の手順が必要です。
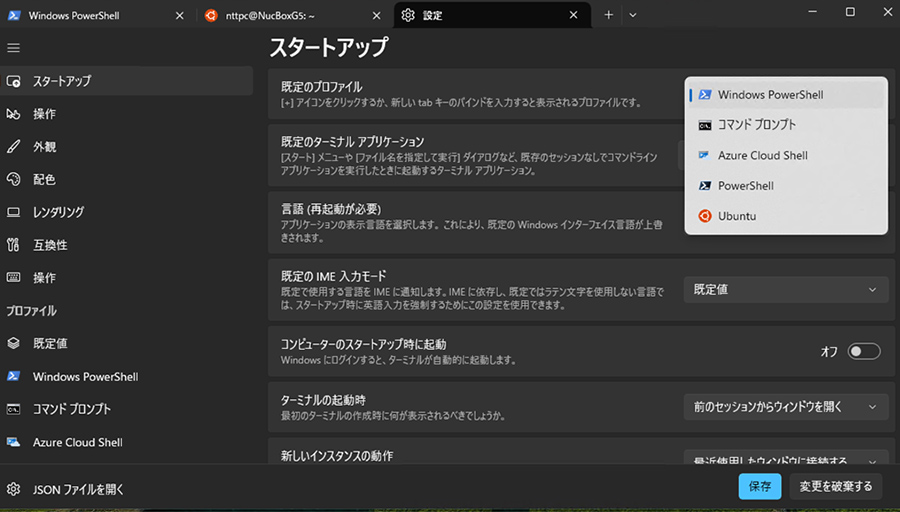
タブの設定を開きます。
スタートアップの既定のプロファイルをUbuntuに変更することでターミナル起動時にUbuntuが開くようになります。
WSL2内でDocker DesktopのDocker Engineを使うためにはDocker Desktopの設定>Resources>WSL IntegrationのEnable integration with additional distros:からWSL2にインストールしたディストリビューション(Ubuntu等)にチェックを入れます。表示がされない場合はDocker DesktopとWSL2を閉じてそれぞれ再度起動する等を試してください。

これでWSL2内のOS(Ubuntu)でDockerが使用できます。
6. Dify環境の構築
ここまででDifyの起動に必要なDocker DesktopとWSL2(Ubuntu)をインストールすることができました。この後の操作を行うことでDifyを動作させることができます。
-
1.
Difyのソースコードをローカルにクローン
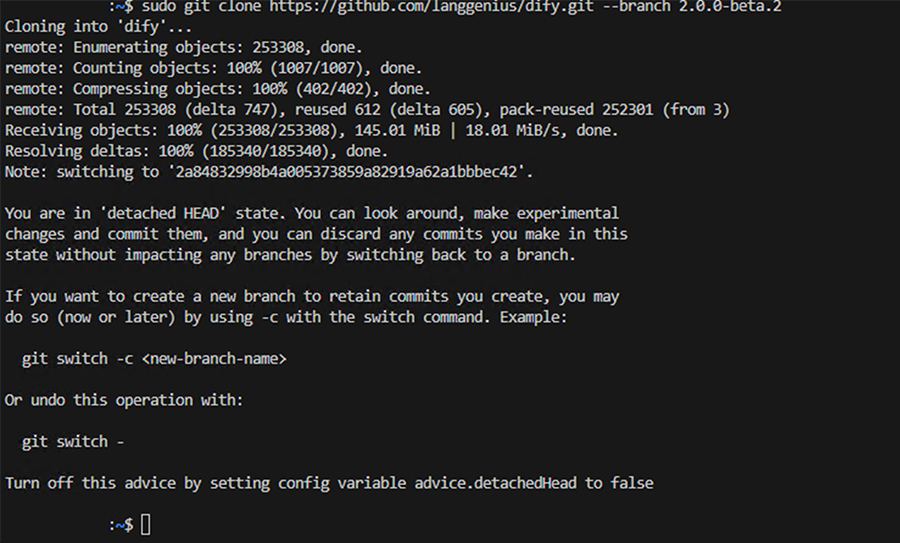
# 執筆時点のDifyの最新バージョンは2.0.0-beta.2なのでこちらをgitからクローンします。
WSL2のUbuntuにはデフォルトでgitがインストールされています。# WSL2の場合起動時にWindows側のディレクトリを開くことがあるので移動する $cd # gitからのDifyのバージョン2.0.0-beta.2をクローン $ git clone https://github.com/langgenius/dify.git --branch 2.0.0-beta.2
-
2.
環境配置ファイルをコピー
環境変数ファイルが初期の状態では作成されていません。
テンプレートのenv.exampleが封入されているのでコピーして環境変数ファイルを作成します。# クローン↓difyファイル内dockerファイル内で作業するため移動 $cd dify/docker # コピーして環境変数ファイルを作成 $ cp .env.example .env # .envファイルができているのか確認 $ls -a
-
3.
dockercompose.yamlファイルのバックアップの作成
Difyソースコードのdockerディレクトリに移動し、dockercompose.yamlファイルをコピー&ペーストし、dockercompose.yaml.orgというファイルを作成します。これはもしも編集などに失敗した時等のリカバリーに使用できます。# dockercompose.yamlファイルのバックアップの作成 $ cd dify/docker $ cp docker-compose.yaml docker-compose.yaml.org
-
4.
Ollama(NVIDIA CUDA版)を同時に起動できるようcomposeファイルに追記
NVIDIAのGPUを搭載している場合はモデルの実行などを行うOllamaをより高速に動作させることができます。dockercompose.yamlファイルを編集します。これによりDify起動時にモデルプロバイダーのollamaも同時起動できます。
変更が必要な箇所のみ掲載しますので参考にしていただければと思います。
次のコマンドでDocker composeの設定ファイルを編集します。$ cd ~/dify/docker $ mv docker-compose.yaml docker-compose.yaml-org $ vim docker-compose.yaml
services: # API service api: image: langgenius/dify-api:2.0.0-beta.2 depends_on: db: condition: service_healthy redis: condition: service_started ollama: condition: service_started worker: image: langgenius/dify-api:2.0.0-beta.2 restart: always environment: depends_on: db: condition: service_healthy redis: condition: service_started ollama: condition: service_started weaviate: image: semitechnologies/weaviate:1.19.0 ports: - "8080:8080" ollama: image: ollama/ollama:latest container_name: ollama restart: always ports: - "11434:11434" volumes: - ollama:/root/.ollama volumes: ollama: -
5.
DifyコンテナをDocker Composeで起動させる
下記のコマンドをWSL2内のUbuntuで入力します。# docker-compose.yamlがあるディレクトリに移動してコンテナを起動する。 $ cd ~/dify/docker $ docker compose up -d
上記のコマンドを実行すると、すべてのコンテナの状態を表示する次のような出力が表示されます。
※バージョンにより異なる可能性があります。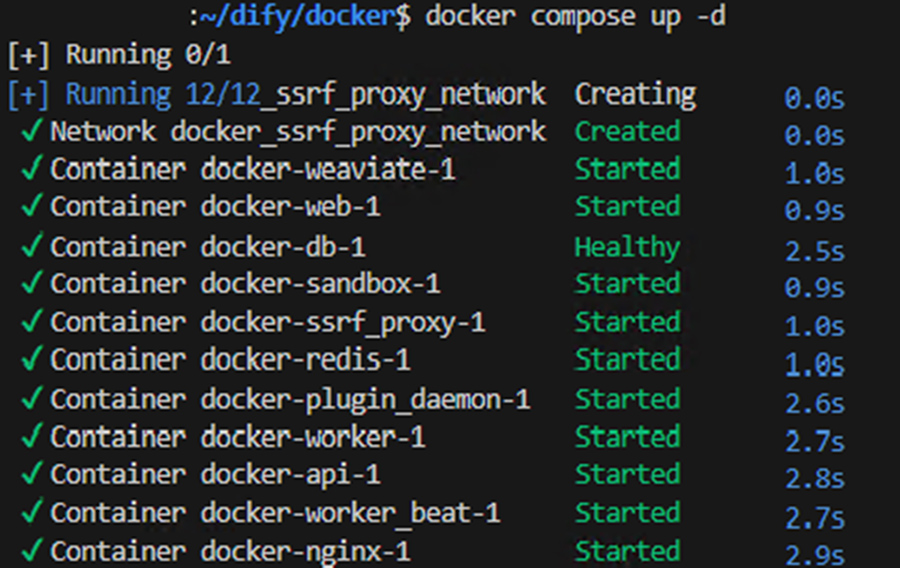
-
6.
すべてのコンテナが正常に稼働しているか確認
Ubuntu内のコマンドで確認する場合、次のコマンドで確認できます。$ docker ps

Docker Desktopからコンテナが見えているのか確認します。
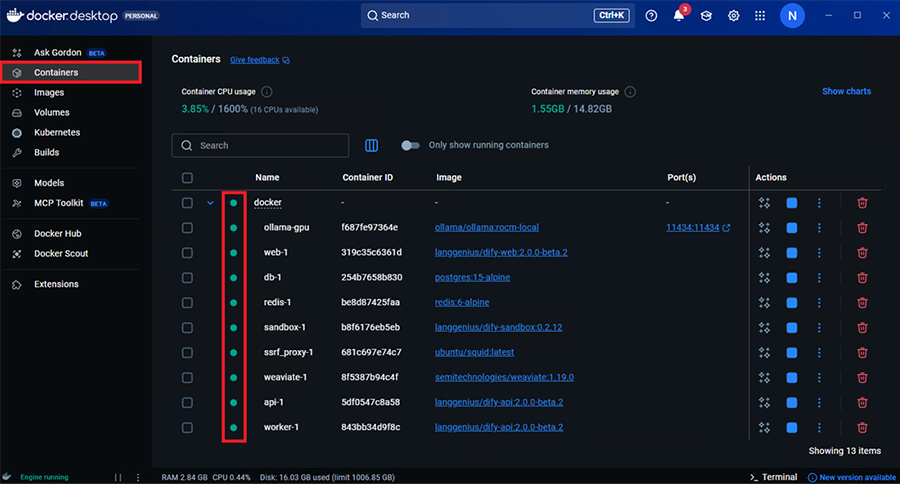
Containersページでdockerコンテナ内のすべてのコンテナの状態が緑色のステータスになっていれば問題ありません。
-
7.
Difyへのアクセス
サーバーを起動したらwebブラウザから下記のアドレスでDifyへアクセスできます。
http://localhost:8080
IPアドレスでアクセスできるようにした場合は次のようにIPアドレスを指定してアクセスします。
http://<yourserverIP>:8080
Docker Desktopの場合は次のようにポートをクリックするとサインインページが開きます。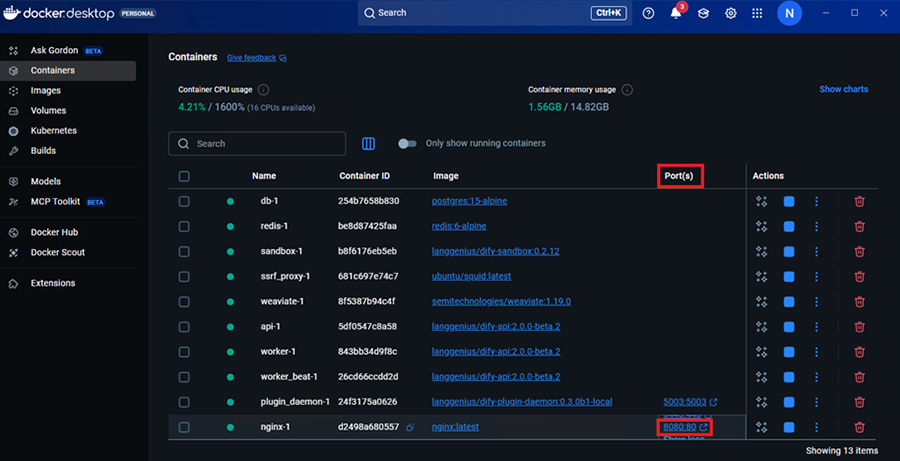
-
8.
管理者アカウントを作成します。
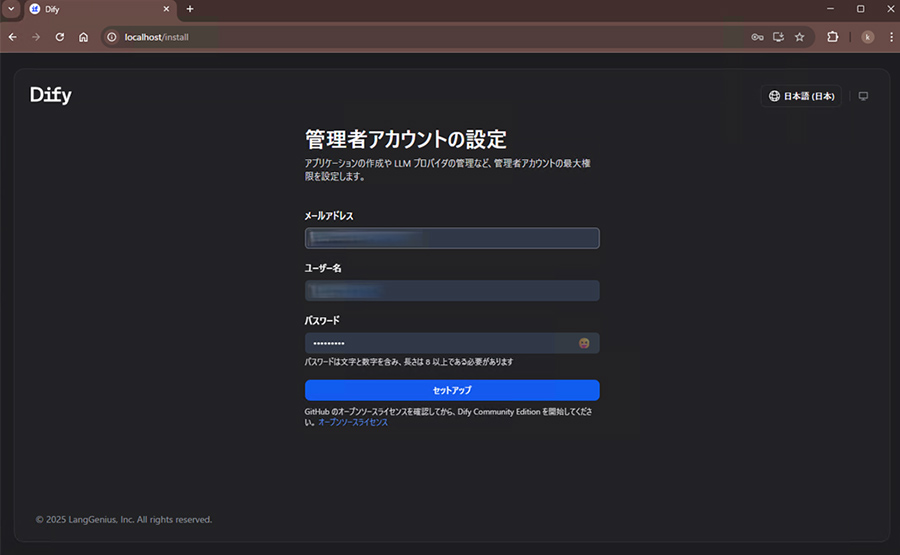
初回ログイン時にWeb画面で管理者アカウントを作成できるのでメールアドレス・パスワードを設定しログインします。

ログインするとこのような画面になります。
-
9.
モデルプロバイダー設定
DifyのWeb画面にログインし設定からモデルプロバイダーを設定します。今回はollamaを使用する方法を紹介します。各モデルプロバイダーで設定項目が異なるのでご自身の使用するモデルプロバイダーにあった設定を行ってください。ここでのダウンロードはソフトウェアのダウンロードのようなものではなく、それぞれのモデルプロバイダーと接続するための機能をダウンロードするものになっています。
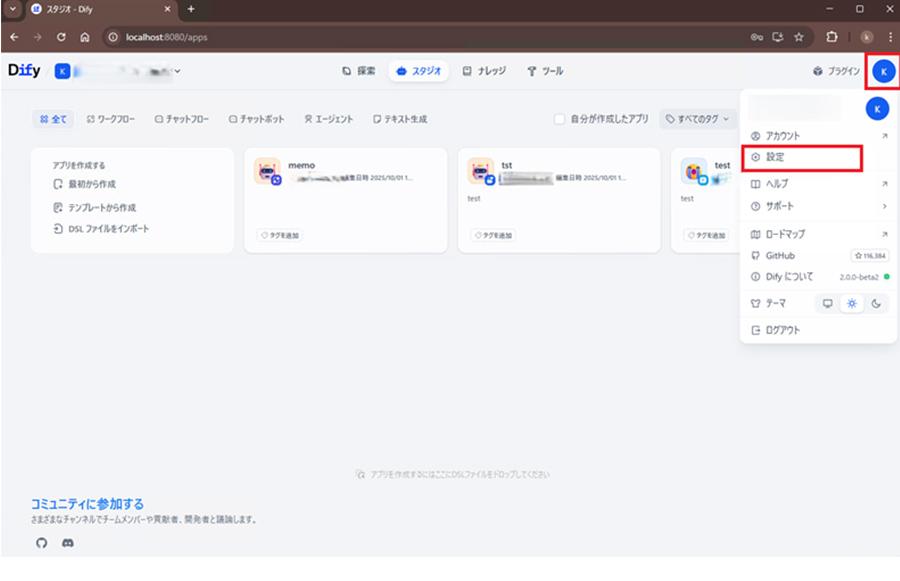
そのため各モデルプロバイダーの動作環境は別で作成する必要があります。
ユーザーアイコンをクリックし、設定をクリックします。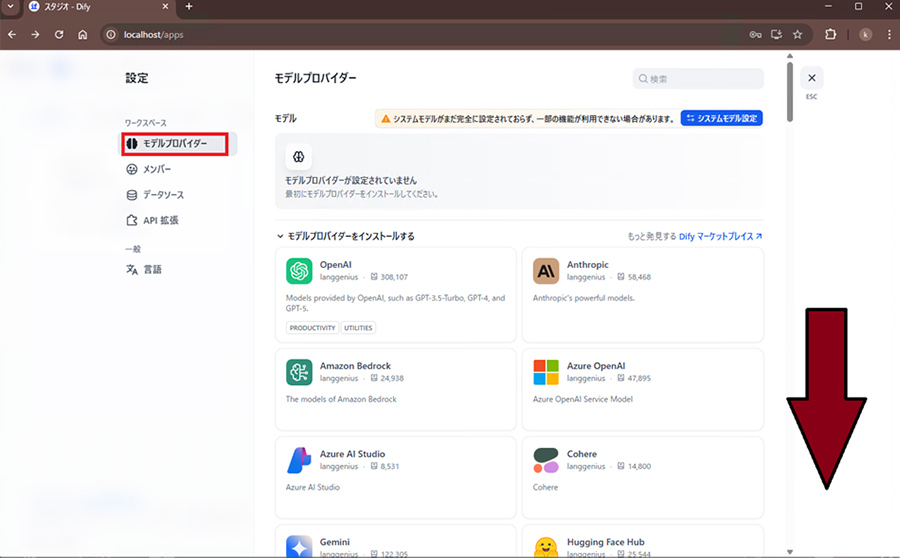
設定画面を開くと「メンバー」が開くので「モデルプロバイダー」のに移動し下にスクロールしてollamaを見つけてください。
マウスカーソルをollamaに合わせるとインストールボタンが表示されるのでクリックします。
このインストールはollamaを環境にインストールする等ではなく、Difyとollamaが連携するためのDify側のツールのインストールだととらえてください。
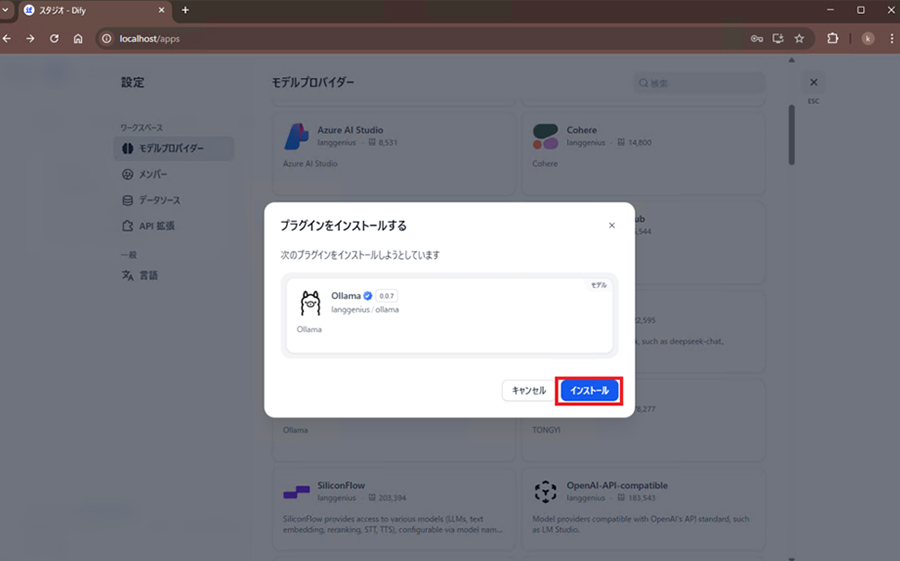
インストールをクリックした後にバージョン情報などが表示されるので再度インストールをクリックします。
その後この画面になればインストールは完了です。

-
10.
モデルのダウンロード
今回はollamaを使用してのモデルのダウンロード方法を紹介します
Docker execを使用して起動中のollamaコンテナ内で作業を行います。
Docker Desktopの場合はコンテナを選択しexecタブから直接コンテナ内で作業することもできます。コンテナにログインしてコンテナ内で作業を行います。
# コンテナにログイン $ docker ps $ docker exec -it containerID /bin/bash
もしくはDocker Desktopの場合はコンテナ詳細のexecタブからコマンド入力ができます。
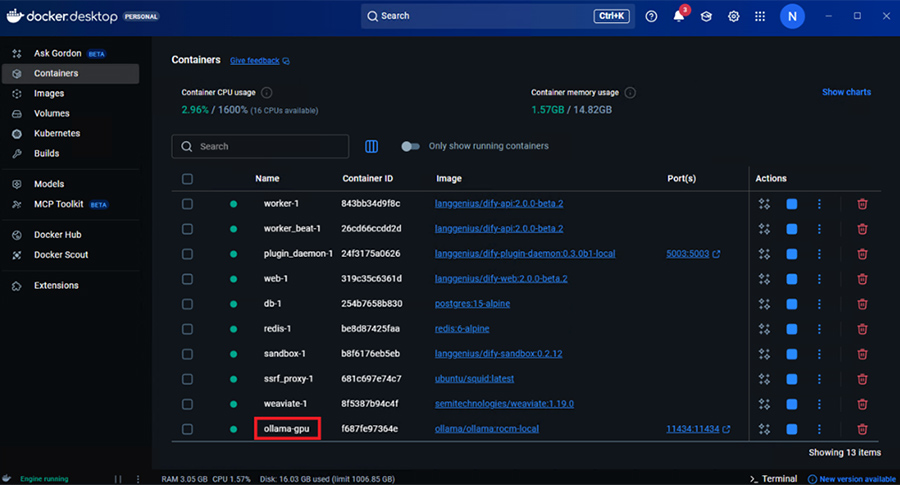
Docker コンテナのollama コンテナをクリックします。
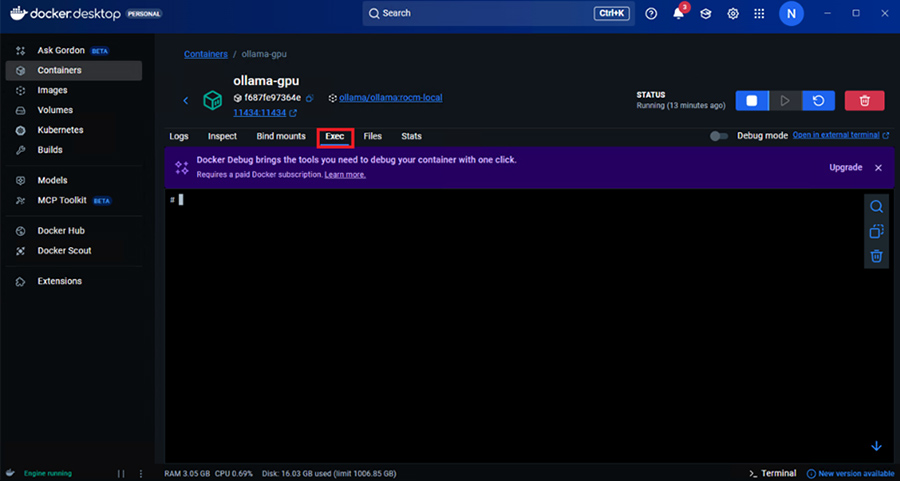
Execのタブに移動するとコンテナ内でコマンド操作ができます。
ダウンロードするモデルの確認
https://ollama.com/library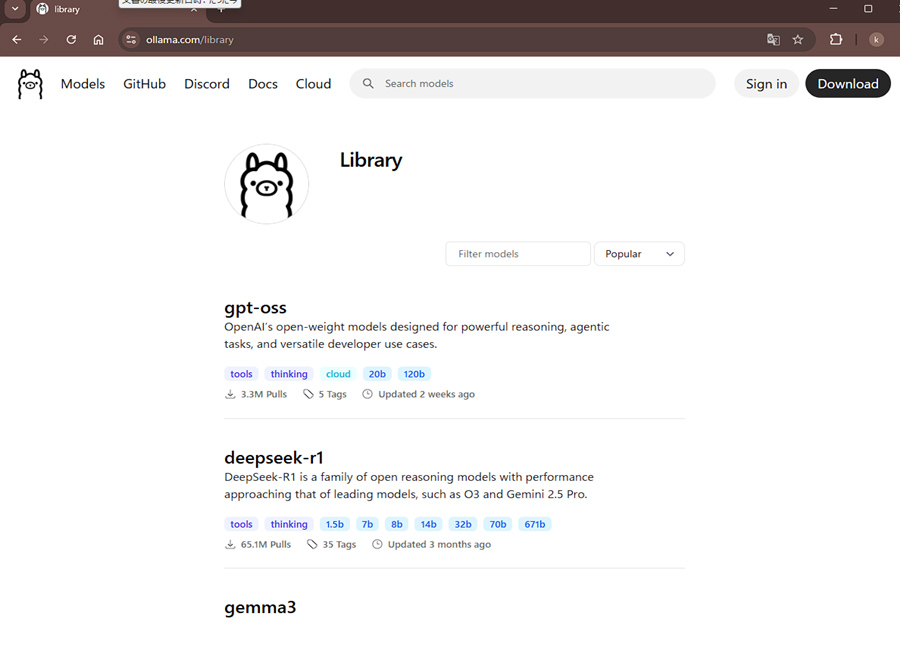
こちらのサイトからollamaで公開されているモデルを確認することができます。
ここでモデルのページを確認してみます。
画面上右上にollamaでのダウンロードコマンドが表示されています。
このコマンドではgpt-ossの場合、モデルサイズが20Bのタグがlatestに設定されているものがダウンロードされます。
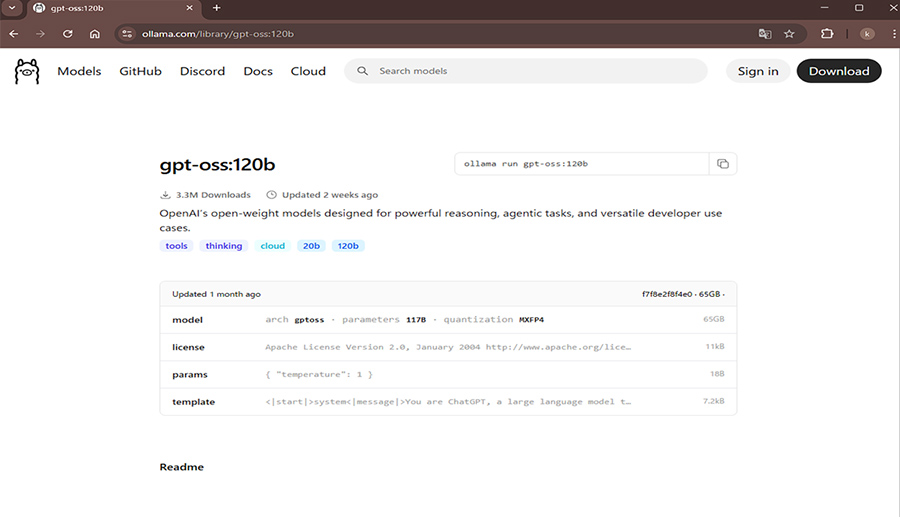
モデルのサイズなどを指定してダウンロードしたい場合はダウンロードしたいモデルサイズのページを開くとコマンドの表記が変わりますのでそのコマンドでダウンロードできます。
コンテナ内でモデルのダウンロードを行います。
# ollamaで公開されているモデルのダウンロード $ ollama pull 〈モデル名〉
# huggingfaceで公開されているモデルのダウンロード $ ollama pull
またollamaコンテナではコンテナ内だけでダウンロードしたモデルが実行できます。
ダウンロードされていない場合はダウンロードも自動で行われます。# モデルの実行 $ ollama run 〈モデル名〉 # 実行例 $ ollama run gema3:4B $ ollama run gpt-oss-20B
ダウンロードしたモデルの確認
# ollama list NAME ID SIZE MODIFIED gemma3:4B a2af6cc3eb7f 3.3 GB About a minute ago
-
11.
Difyでのモデルの設定
モデルプロバイダー設定で事前にインストールしているollamaの「モデルを追加」をクリックします。
次のような画面になるので参考にして設定を行います。モデル名の指定については、ollamaコンテナ内でollama listのコマンドで確認できます。
今回はgemma3なのでvision supportをonにしています。不要な場合などはoffにしていても特に問題はありません。
Gemma3のようにモデルによってはvision supportを使用することができます。モデル名やモデルカードなどで検索することでvision supportに対応済みか確認きる場合が多いので確認することをお勧めします。vision supportを使用可能な場合は画像を入力として使用可能になります。この機能が使用できる場合には写真などの画像情報を入力として使用することができます。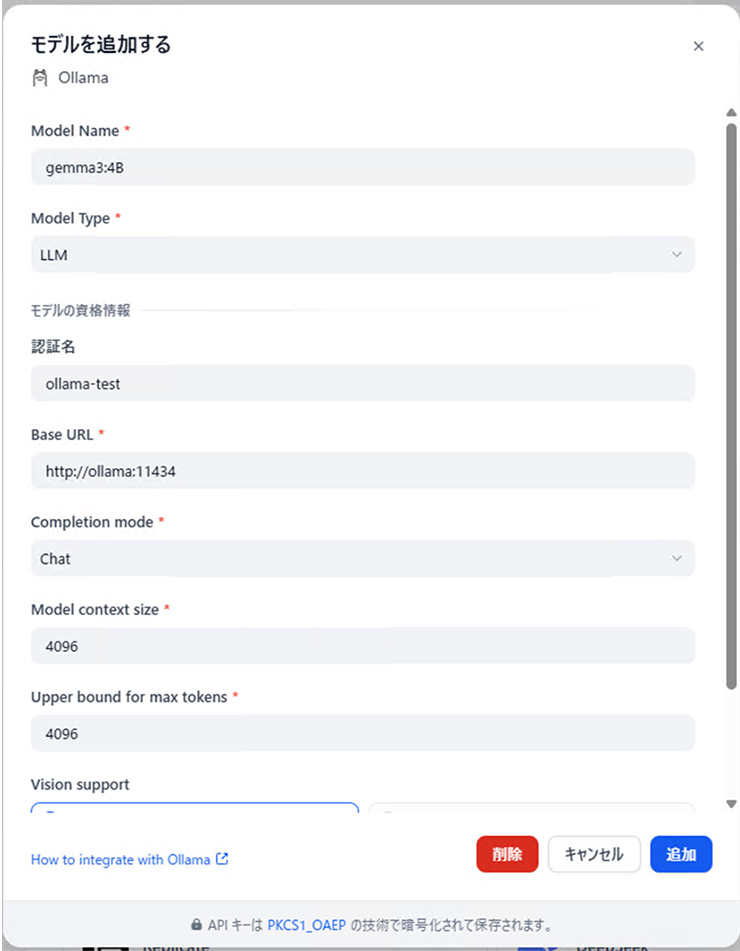

最後にDifyのシステムモデル設定を行います。
設定>モデルプロバイダー>システムモデル設定>モデルを設定の順にクリックします。
すると追加したモデルが表示されて選択できますのでクリックして保存をクリックします。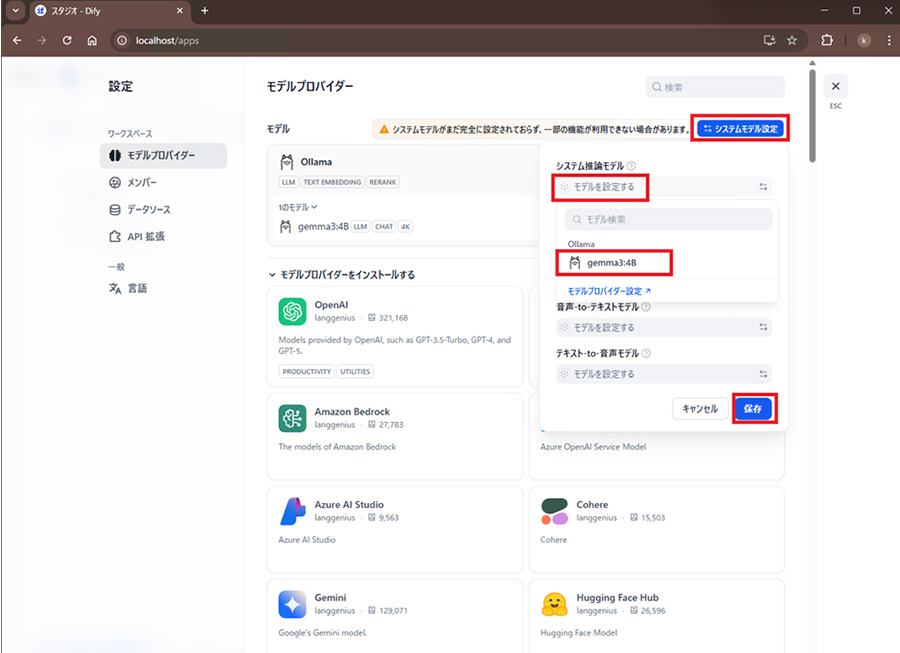
Dify環境の構築完了
お疲れ様でした以上でDifyの環境設定は完了しました。
これでAIアプリケーションを作成できるようになっています。
7. 最後に
今回はDifyとローカル上でLLMを同時に動作させる環境を構築する方法を紹介しました。
ローカルならではのカスタマイズ性や自由度といった面白い点がたくさんあるので、是非この記事を読んでいる方にもローカルLLMを使ってみるきっかけやサポートになればうれしいです。
-
※Windowsは、米国Microsoft Corporationの米国およびその他の国における登録商標または商標です。
-
※Linuxは、Linus Torvalds 氏の日本およびその他の国における登録商標または商標です。
-
※Microsoftは、米国 Microsoft Corporation およびその関連会社の商標です。
-
※DockerおよびDockerロゴは、米国およびその他の国におけるDocker, Inc.の商標または登録商標です。Docker, Inc. およびその他の当事者は、本書で使用される他の用語の商標権も有する場合があります。
-
※Difyは、米国LangGenius社の登録商標です。
-
※その他の商品名、会社名、団体名は、各社の商標または登録商標です。
技業LOG
NTTPCのサービスについても、ぜひご覧ください