



性能検証
水冷GPUサーバーの効果を徹底検証【後編】
2025.12.16
NTTPCコミュニケーションズ株式会社
岡本 朋之
株式会社ゲットワークス
林 竜太朗
株式会社フィックスターズ
野崎 雅章

1. はじめに
前編記事ではHPC系ベンチマークでの比較から、水冷サーバーの温度安定性と電力効率の優位性を確認しました。それでは、よりGPUにかかる負荷の大きい大規模AI学習や推論処理ではどうでしょうか? 後編では、LLM学習(NVIDIA NeMo™)およびLLM推論(vLLMエンジン)での検証結果を報告します。水冷の効果が一段と際立つポイントに注目してください。
2. LLM学習時の温度挙動と安定性
まず、大規模言語モデルの事前学習ジョブを実行中の温度推移を比較します。100ステップの学習を約15分かけて行いました。前編で実施したHPCテストよりGPU負荷が高く、水冷/空冷どちらも平均GPU温度が60℃を超える重負荷となりました。
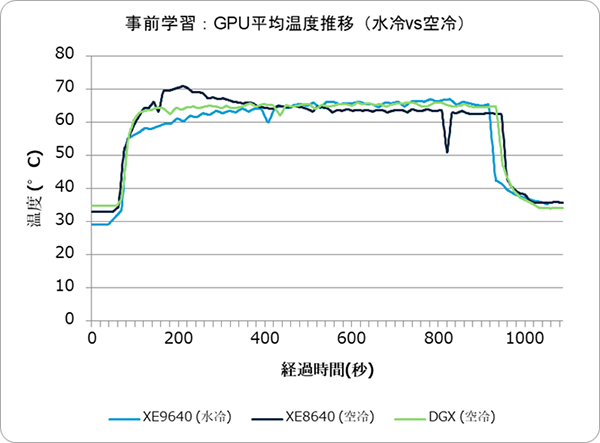
図2.1:GPU平均温度推移比較(LLM学習)
温度上昇パターンの違い: 学習の序盤、空冷サーバー(XE8640, DGX)はGPU温度がすぐ50〜60℃台に達しファン回転数が最大化しました。一方、水冷サーバー(XE9640)は緩やかな温度上昇に留まり、学習ステップ後半までピーク温度に達しない傾向が見られました。
これは冷却水の高い熱容量により温度変化が緩和され、またGPUの発熱が即座に水へ逃げることで急激な温度上昇が抑制されたためと考えられます。
一方、空冷はGPU温度がピーク付近(約65〜70℃)まで上がるとファンでの制御が始まってやや温度は下がり、その後は一定温度を維持する動作となりました。つまり水冷は「温度上昇自体を小さく抑える」、空冷は「温度上昇後に冷却制御してそのまま維持する」という動きの違いが見られました。
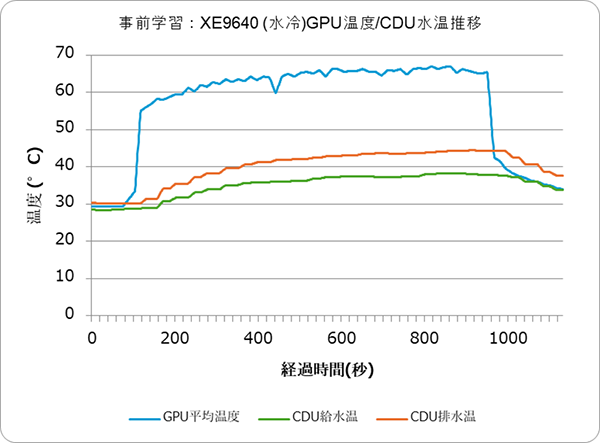
図2.2:GPU温度/CDU水温推移(事前学習)(LLM学習)
加えて、水冷システムではGPU温度の変化に遅れて冷却水温が変化する様子も観測されました。結果は図2.2をご覧ください。
GPUから出る温水がCDUで冷やされて戻ってくる循環に数秒〜十数秒かかるため、GPU温度の波形に少し遅延してCDU給水温が上下する特徴が確認されています。なお、本検証のCDUは排水を空気で冷却する”Liquid to Air”方式であり、排水を水で冷却する”Liquid to Liquid”方式のCDUは結果が異なる可能性があります。
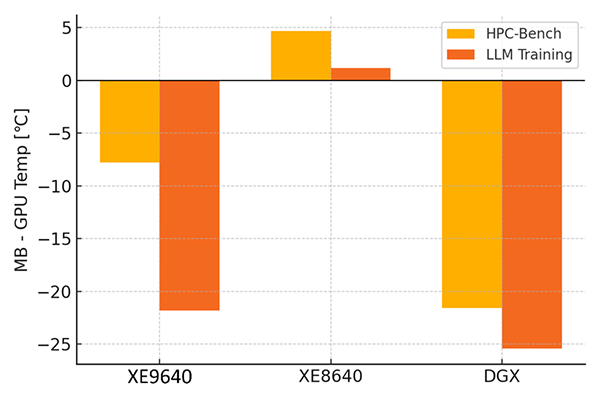
図2.3: GPU温度に対するマザーボード温度差(MB−GPU)
内部温度への影響: 学習時も、水冷と空冷で「GPU以外の温度」にも差が出ました。図2.3はHPC時と学習時での各構成の「マザーボード温度 − GPU温度」の差をまとめたものです。
空冷サーバー(XE8640)ではGPUが70℃近くまで上昇した影響で、マザーボードも最終的に約65℃前後に達しました。一方、水冷サーバーではGPUが58℃程度に抑えられたおかげでマザーボード温度は約37℃にとどまり、その差は21.8℃にも開きました。
図2.3の棒グラフの下方向は「マザーボードがGPUより低温」であることを示します。水冷サーバーではHPC負荷時でマザーボードがGPUより約7.8℃低温でしたが、学習時には21.8℃も低温となり差が拡大しています。これは、HPC-Benchmarkと比較して学習時におけるGPU発熱は10数℃上昇したものの、マザーボードなど周囲の温度は上昇していないことを示しており、水冷方式がGPUの熱を周囲に拡散しにくいことを裏付けていると言えます。一方、空冷サーバー(XE8640)ではGPUとマザーボードの差がわずか1.2℃(マザーボードの方が高温)となり、HPC時に比べGPUと周辺の温度差がほぼ無くなっています。むしろHPC時にはMBがGPUより+4.7℃高温になる局面もあったため、空冷では引き続きGPUの発熱が他部品を温めてしまう状況です。DGX H100についてはマザーボードがGPUより常に20℃以上低温を維持し、空冷機としては良好な結果でした。
水冷の効果: 安定性と効率 – 高負荷の事前学習ジョブにおいて、水冷サーバーは温度面で明確なアドバンテージを示しました。GPU/内部/排気すべてで温度抑制効果が発揮され、学習のような長時間高負荷シナリオではその恩恵が特に大きいと言えます。では、そのことは性能面の「安定性」や「ばらつき」に表れているのでしょうか?次に、各ステップ処理時間の統計値やGPU動作クロックのばらつきを分析しました。
表2.1:事前学習実行結果比較(Step時間)
| 方式 | 平均Step時間(s) | p50(s) | p95(s) |
|---|---|---|---|
| XE9640 (水冷) | 7.726 | 7.647 | 7.985 |
| XE8640 (空冷) | 7.785 | 7.707 | 8.287 |
| DGX (空冷) | 7.701 | 7.627 | 7.993 |
処理速度と安定性: 学習ジョブの平均ステップ時間(Iteration時間)を比較すると、水冷・空冷・DGX間で平均値や中央値(p50)は±1%以内と僅差でした。冷却方式で「処理の速さ」自体は大きく変わりません。一方で、遅いケースの指標であるp95(95%分位点)では水冷が最も短く、空冷が最も長い結果となりました。具体的には、水冷XE9640はp95が約8.0秒、空冷XE8640は約8.3秒で、その差は3.7%程度ですが無視できません。
これは、空冷サーバーでは時折「異常に遅いステップ」が発生したのに対し、水冷では少なかったことを意味します。空冷サーバー(XE8640)ではファン制御や温度変動の影響で処理がばらつき、一部ステップで遅延が生じました。一方、水冷サーバーではステップ時間のばらつきが小さく、重負荷時も安定した処理速度を維持できました。
この安定性の違いを裏付けるデータとして、GPUコアクロックの揺らぎを解析しました。
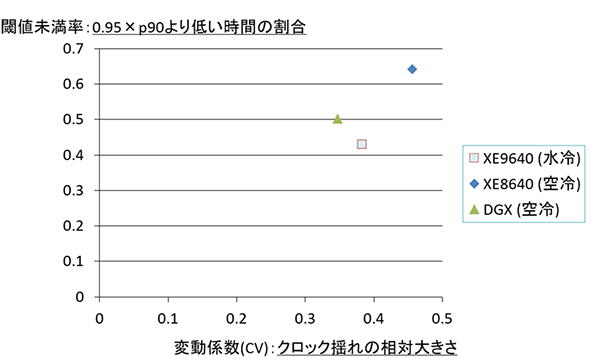
図2.4: GPUクロック変動係数(CV) vs 低クロック発生率(事前学習)
横軸はクロックの揺らぎ幅(変動係数: 大きいほどクロックが不安定)、縦軸は閾値未満率(低クロック状態の時間割合: 高いほど頻繁にクロックが低下)を示します。左下に位置するほど安定、右上に位置するほど不安定といえます。
水冷サーバーXE9640(水色□プロット)はCV=0.383、閾値未満率0.429で、最も閾値未満率が低く、明らかにクロック安定性が高いことが読み取れます。逆に空冷サーバー(青◆)はCV=0.456、未満率0.640と、最もクロック変動が大きく低速状態が頻発しています。
DGX H100(緑▲)はCV=0.347、未満率0.500で、水冷ほどではないものの十分に良好な安定度を示しました。このことからも、水冷冷却によって温度起因のサーマルスロットリングが効果的に抑制され、高負荷時の処理ムラが減少することが読み取れます。
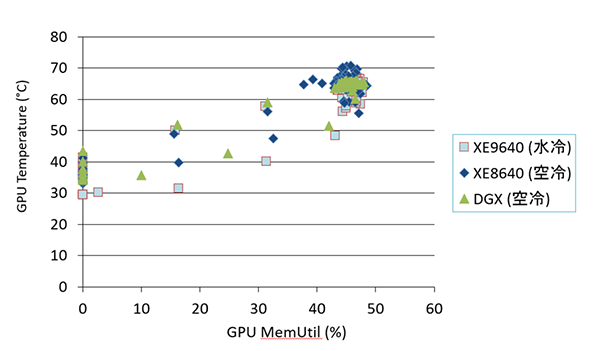
図2.5: GPUメモリ使用率とGPU温度の関係(事前学習)
図2.5は各構成の学習中ログから、GPUメモリ使用率とGPU温度の散布図を示したものです。水冷サーバーのプロット群(水色□)は、空冷プロット群(青◆と緑▲)より明らかに低い温度領域に分布していることがわかります。つまり、同じメモリ使用率でも水冷GPUの方が温度上昇が緩やかであることを意味します。
このように、水冷は高負荷時の温度上昇を抑えることで、システム全体の動作を安定化させる効果がデータから裏付けられました。
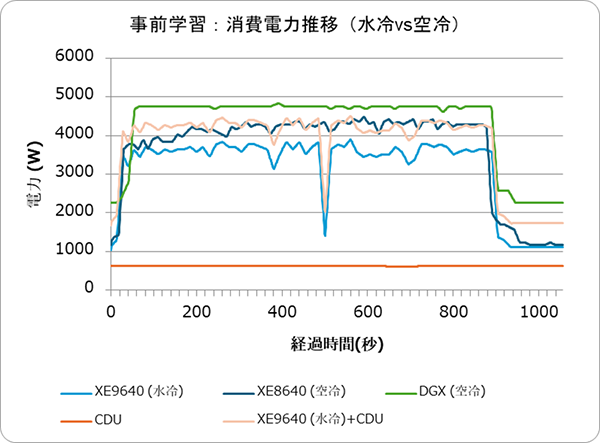
図2.6: LLM学習実行中のサーバー消費電力推移(水冷 vs 空冷)
図2.6は各サーバーの消費電力の推移です。負荷の増大に伴い全体の消費電力が増加する中、XE8640(空冷)の消費電力の上昇が特に大きく、水冷サーバー+CDUとほぼ同等の消費電力量となりました。
3. LLM推論時の挙動と総合評価
次に、大規模モデルの推論処理における比較結果です。前提として、推論ワークロードでは学習時とは異なりGPU負荷が間欠的(バースト的)になります。今回のテストでも、512並列のリクエストを一定間隔で送り続けましたが、GPUの使用率は常に100%というわけではなく、アイドルとフル負荷を繰り返すパターンでした。この特性により、温度や消費電力の変動傾向も学習時とは異なるものとなりました。
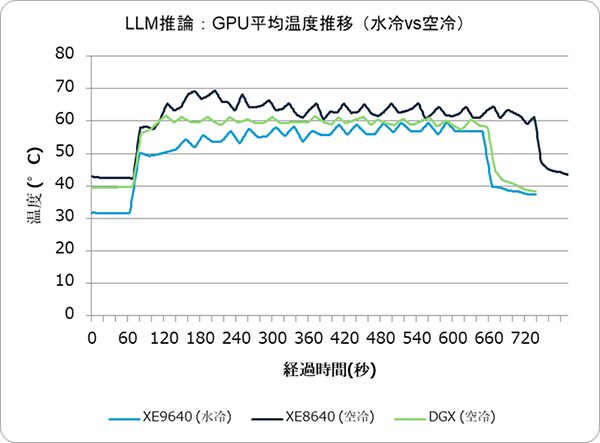
図3.1: LLM推論実行中のGPU温度推移(水冷 vs 空冷)
温度挙動: 推論実行中の平均GPU温度推移を観測すると、グラフ形状自体は学習時と大きく異なりました(負荷のオンオフがあるため)。しかし各サーバー固有の温度特性、すなわち「水冷は上昇が緩やか」「空冷は急上昇して一定を保つ」といった傾向は推論時でも類似していました。水冷サーバーは推論処理中もGPU温度が50℃台で安定していましたが、空冷サーバーは60℃近辺まで上昇する場面が見られました。
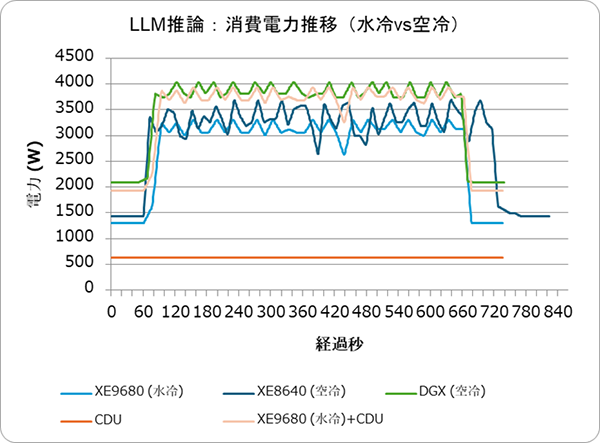
図3.2: LLM推論実行中のサーバー消費電力推移(水冷 vs 空冷)
学習時と同様に、水冷サーバー単体(青実線)は空冷(橙実線)より低い消費電力で推移しています(GPUファン負荷が小さいため)。しかしCDU込みの合計(青点線)では、空冷とほぼ同等か僅かに上回る程度になりました。
推論処理はGPU負荷の変動が大きく、要求の谷間にGPUが休息できるため、アイドル時には空冷ファンも回転数を下げて無駄な電力消費を減らせる利点があります。その結果、水冷の省電力メリットは学習時ほど大きく出ない傾向が見られました。
最後に、推論処理のパフォーマンス指標を比較します。
表3.1:事前学習実行結果比較(Step時間)
| 構成 | Req/s | Avg Latency(ms) | p95 Latency(ms) | Tok/s |
|---|---|---|---|---|
| XE9640 (水冷) | 14.02 | 36443.9 | 37741.2 | 36844.3 |
| XE8640 (空冷) | 13.87 | 36590.7 | 37988.4 | 36612.6 |
| DGX (空冷) | 13.71 | 36680.1 | 38045.6 | 36502.2 |
応答性能への影響:測定したスループット(Req/s)やレイテンシ、トークン生成速度はいずれも水冷・空冷間で±3%以内の僅差であり、統計的に有意な性能差は確認できませんでした。例えばReq/sは水冷14.02に対し空冷13.87、平均レイテンシは水冷36.44秒 vs 空冷36.59秒と、ほぼ同等です。これは、推論のように負荷が断続的な場合、水冷による温度安定性が性能向上に結び付きにくいことを示唆します。実際、GPUが常にフル稼働する学習時とは異なり、推論時はGPU温度も適度にクールダウンする余裕があります。そのため空冷でもスロットリングがほぼ発生せず、どの構成でも安定した性能を発揮しました。
以上を踏まえると、水冷のメリットが最大限発揮されるのは「常にGPUに高負荷がかかり続ける環境」であると言えます。例えば大規模モデルの継続的な学習やHPC業務など、長時間にわたりGPUがフル利用されるケースです。一方、GPU負荷が断続的または低〜中程度に留まるケースでは、水冷による性能向上は限定的であり、場合によっては従来型の空冷や小規模GPU構成でも十分かもしれません。
4. コンテナ型データセンターにおけるpPUEの検証
今回の水冷サーバーの検証はコンテナ型データセンター内で実施しています。そこで最後に、コンテナ型データセンター内におけるエネルギー効率の指標である pPUE について考察します。
一般に PUE(Power Usage Effectiveness)はデータセンター全体のエネルギー効率を示す指標で、設備全体の消費電力をIT機器の消費電力で割った値として定義されます。一方、pPUE(partial PUE)は特定の区画やコンテナなど限定した範囲内でのエネルギー効率を評価するための指標です。今回の検証では、検証を実施した水冷コンテナ内部のサーバールーム単位を対象に、コンテナ内部の総消費電力(ICT機器+内部補助設備)をICT機器(GPUサーバー)の消費電力で割った値をpPUEと定義しました。

一般に、pPUEが1.0に近いほど付帯設備によるエネルギー消費が少なく高効率であると解釈できます。水冷コンテナでは、サーバー冷却に外部の冷水(CDU経由で供給)を利用しており、CDU自体の冷却も外部の地下水で冷やすInRow空調に委ねています。そのため、コンテナ内部だけを見れば、冷却に関わる電力の大部分が外部設備にオフロードされており、空冷型のデータセンターに比べてpPUEは低くなる傾向があります。
図4.1および図4.2に、低負荷時と高負荷時それぞれのコンテナ内pPUEの計測結果を示します。なお、この結果画面は株式会社フィックスターズが作成したデータ収集&計算用ページの画面ショットです。SNMP,API等で取得したデータを計算しグラフィカルに表示しています。
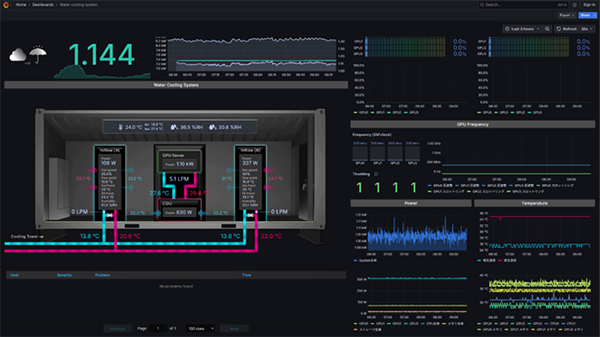
図4.1 低負荷時のコンテナ内pPUE
図4.1はコンテナ内のGPUサーバーの負荷が低い状態(約1.0kW)の際のpPUE測定結果です。pPUEは約1.144で、ICT機器に対して約14.4%のエネルギーが補助設備で消費されていることを示します。低負荷時はICT機器の消費電力が小さいため、一定のベース電力を要する補助設備の比率が相対的に大きくなり、pPUEはやや高めになります。
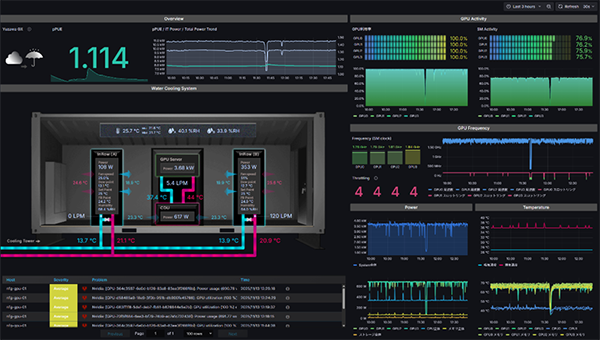
図4.2 高負荷時のコンテナ内pPUE
図4.2はGPUサーバーを高負荷で稼働させた状態(約3.7kW)の際のpPUE測定結果です。pPUE(1.0に近いほど付帯設備によるエネルギー消費が少なく高効率といわれる)は約1.114まで改善しており、ICT機器電力に対する冷却など付帯電力の割合が約11.4%に抑えられています。高負荷ではICT機器の消費電力が大きくなるためこのような結果が出たと考えられます。
これらの結果から、水冷対応コンテナの優位性について、主に次の3点が確認できました。
① GPU高負荷時は高効率: GPU負荷が高い時ほどpPUEが1.0に近づき、負荷が低い時にはpPUEがやや悪化(上昇)する傾向が見られました。これは、コンテナ内で稼働する補助設備(ポンプ、照明、制御系など)の消費電力がGPU負荷に関わらず一定である一方、ICT機器側の消費電力は負荷に比例して変動するためです。
ICT機器の電力が小さい低負荷時には補助設備のオーバーヘッドが相対的に大きくなり値が上がりやすくなりますが、高負荷時にはICT機器の電力が増えるため比率が小さくなりpPUEが改善します。これは一般的なPUE指標と同様の傾向です。
② 水冷コンテナならではの効率性: 水冷構成では冷却の主要部分(熱交換器・冷却塔・大型CDUなど)がコンテナ外部に配置されます。その結果、コンテナ内部にはICT機器と内部循環用の最小限の補助系のみが残り、コンテナ単体で見るpPUEはほぼ1.1前後に維持されました。
特にGPUサーバーを高負荷で稼働させてもpPUEが1.1程度で安定しており、冷却に伴う消費電力がICT電力に対して線形に増えない、すなわち冷却コストが低く抑えられていることを示しています。
③ 水冷コンテナに適した用途: 高密度GPUワークロードを長時間稼働させるほど、相対的なエネルギー効率(pPUE)は向上する傾向があります。そのため、AI学習やHPCのような連続高負荷ワークロードに水冷コンテナは適したプラットフォームと言えます。また、GPU利用率が下がった際にもpPUEの悪化が小さいため、部分負荷の領域でも一定の省エネ性を保てる点は運用上の強みです。
さらに、冷却電力の大部分を外部設備に任せているおかげで、コンテナ内部の電源設備(PDU・UPS)の容量設計が容易になり、設置場所の自由度や将来的な増設のしやすさといった面でもメリットが期待できます。
5. 後編のまとめ
まず、水冷冷却はGPUをフルに使う高負荷・長時間のタスクで最も効果が顕著に発揮されました。特に、LLM学習では空冷に比べシステムの安定性が向上し、終始高い性能を維持できました。
一方、断続的な負荷のLLM推論処理では水冷・空冷の性能差はほとんどありませんでした。短時間のHPCベンチマークでも両者の性能値はほぼ同等です。
とはいえ、水冷の温度安定性によって排熱温度は常に低く抑えられています。ラック背面の排気温度を比較すると、水冷では周囲温度+約10℃程度に留まったのに対し、空冷では+25℃前後まで上昇しました。空調への負荷や周辺機器への熱影響の差は歴然と言えるでしょう。
水冷によってこのような低温排熱が得られることは、複数ラックにまたがるGPUクラスタ環境やコンテナデータセンターの運用上、大きな利点です。空冷では装置密度が高まるほどホットスポットが生じやすく、大規模空調設備やラック配置の工夫が必要となりますが、水冷ならこうした課題を大幅に緩和できるでしょう。
ただし、水冷設備の導入にあたっては、CDUなど冷却装置の消費電力まで含めたトータルのエネルギー効率や初期導入コスト、運用時の冷却水温の制御範囲(例:22〜30℃)など、検討すべき事項もあります。これらはシステム規模や設置環境によって最適解が変わるため、個別の条件に応じた設計・チューニングが必要となるでしょう。
今回の検証ではHopper世代GPU(現行では空冷方式が主流)とLiquid to Air方式の水冷設備を組み合わせましたが、それでも空冷を上回る良好な結果が得られた点は非常に興味深いものです。特にLLM学習における性能・効率の向上から、大規模AIモデルの開発環境や高密度GPUを用いたAIサービス基盤への水冷技術の適用可能性が示唆されます。発熱の多いGPUサーバーをいかに効率よく冷却し、安定して能力を引き出すかは、今後のAI/HPCインフラにおいて重要なテーマです。
本検証結果が、その解決策の一つとして水冷方式を検討する際の一助になれば幸いです。
水冷対応GPUサーバーの導入をお考えの方は、NTTPCまでぜひお問い合わせください。
▶︎ お問い合わせはこちら
※「NVIDIA DGX H100」は米国およびその他の国における NVIDIA Corporation の登録商標です。