



性能検証
DGX SparkでのLLM推論ベンチマーク ~チャットアプリとして使ってみた~
2026.01.29

GPUエンジニア
今井 雄貴

【目次】
こんにちは。西日本エリアでインフラやGPUの構築・設計を担当しているエンジニアの今井です。
このたび、NVIDIA DGX™ Sparkを利用できる環境が整ったため、以前から関心のあったLLM推論性能のベンチマーク検証を実施しました。
小型ワークステーションを用いた推論環境に関するお客さまからのお問い合わせも増えており、そうした背景も踏まえ今回の検証を行っています。
本記事では、DGX Spark上で複数の実行環境(コンテナ)・推論フレームワーク・LLMモデルを用いてLLM推論ベンチマークを実行した結果を紹介します。後半ではOpen WebUIを用い、ベンチマーク結果だけでは見えにくい実際の利用感についても少しだけ触れたいと思います。
これからLLM推論の検証や選定を行う方にとって、少しでも参考になれば嬉しいです。
1. はじめに
• 対象読者:
- 小型ワークステーションを用いたオンプレミス推論環境に関心のある方
- vLLMやSGLangなどの推論フレームワークをこれから試そうとしている方
- 数値ベースのベンチマーク結果に加え、実際の使用感も知りたい方
• 前提:
- DGX Sparkの初期セットアップは完了済であることを前提としています
- DGX Sparkの仕様解説や初期セットアップ手順については本記事では扱いません。初期セットアップについては下記の「DGX Spark User Guide」や、当社エンジニアが執筆した関連記事をご参照ください
DGX Spark User Guide:DGX Spark User Guide — DGX Spark User Guide
関連記事:DGX Sparkを2台でクラスタ化してAIエージェントを構築&GPT-OSS-120Bを実行してみた|GPUならNTTPC|NVIDIAエリートパートナー
※DGX Sparkで利用可能な機能やユースケース全般については、以下の「Playbook」に詳しくまとめられています
Start Building on DGX Spark
• 注意事項:
本記事で紹介する検証内容および結果は、2025年12月時点における特定の環境および条件下で実施したものです。LLM推論環境の関連ソフトウェアは更新頻度が高く、実行環境はバージョン違いによって挙動や性能が変わる可能性があるため、本記事の内容はあくまで参考情報としてご利用ください。
なお、本検証では各LLMモデルの応答性能に着目しています。
生成される文章の品質や内容といった言語性能の評価を目的としたものではありませんので、あらかじめご了承ください。
2. ベンチマーク検証環境
2-1. 推論フレームワーク
本検証では、次のLLM推論フレームワークを対象としました。各フレームワークは最適化されたコンテナが提供されているため、それらを利用することにしました。
| 推論フレームワーク | 使用コンテナイメージ |
|---|---|
| vLLM | nvcr.io/nvidia/vllm:25.12-py3 |
| SGLang | nvcr.io/nvidia/sglang:25.12-py3 |
| SGLang | lmsysorg/sglang:spark |
| ollama | ollama/ollama:0.13.5 |
「SG Lang」については、LMSYS ORG(Large Model Systems Organization)よりDGX Spak向けに最適化されたコンテナが出ているため、NGC(nvcr.io)コンテナとの双方で比較しています。
DGX Spark Playbook内にも当該コンテナを用いたSGLangの利用例がありますので参考にしてください。
参考:dgx-spark-playbooks/nvidia/sglang at main · NVIDIA/dgx-spark-playbooks · GitHub
2-2. 使用モデル一覧(vLLM / SGLang)
検証に使用したLLMモデルは下表のとおりです。
| モデル名 | パラメーター規模 | 重み形式(量子化/精度) |
|---|---|---|
| openai/gpt-oss-120b | 120B | MXFP4 |
| openai/gpt-oss-20b | 20B | MXFP4 |
| nvidia/Llama-3.3-70B-Instruct-NVFP4 | 70B | NVFP4 |
| meta-llama/Llama-3.1-8B | 8B | BF16 |
| meta-llama/Llama-3.2-3B | 3B | BF16 |
| google/gemma-3-27b | 27B | BF16 |
| google/gemma-3-12b | 12B | BF16 |
| google/gemma-3-4b | 4B | BF16 |
※「llama3.3-70B」モデルについては、BF16では、Out of MemoryでGPUメモリ上に展開できないため、NVIDIAがHugging Face上で公開している量子化(NVFP4)モデルを利用
参考:nvidia/Llama-3.3-70B-Instruct-NVFP4 · Hugging Face
DGX Sparkは、128GBと比較的大きいサイズのGPUメモリを備えており、大規模なLLMでも単一GPUでの推論が可能です。
本検証では、この特性を活かし、小規模モデルから大規模モデルまでを幅広く動作させたうえで、モデルやパラメーター数の違いが推論性能にどのような影響を与えるのかを確認しました。
2-3. 使用モデル一覧(ollama)
ollamaについては、主にGGUF形式の量子化済みモデルを使用しています。
GGUFはllama.cpp系で利用されている量子化モデル形式であり、Hugging Face上のモデルを直接利用するvLLMやSGLangとは、モデル形式が異なります。
※gpt-ossモデルについては、ollamaでも「MXFP4」が利用可能です
| モデル名 | パラメーター規模 | 重み形式(量子化/精度) |
|---|---|---|
| gpt-oss:120b | 120B | MXFP4 |
| gpt-oss:20b | 20B | MXFP4 |
| llama3.3:70b | 70B | Q4_K_M |
| llama3.1:8b | 8B | Q4_K_M |
| llama3.2:3b | 3B | Q4_K_M |
| gemma3:27b | 27B | Q4_K_M |
| gemma3:12b | 12B | Q4_K_M |
| gemma3:4b | 4B | Q4_K_M |
3. ベンチマーク結果の見方
ベンチマークの結果を整理・比較するために、本検証で取得した値について以下に整理します。
LLM推論は単純な生成速度(スループット)だけでなく、初期応答の早さや、どの程度のモデルサイズを現実的に展開できるかといった要素も実際の運用設計に影響します。
モデルのメモリ展開サイズについては、おおよその理論値を見積もることは可能ですが、本記事では実際にモデルを展開した際の使用量も確認・記録しています。
なお、実利用では、KV Cacheなどのメモリ消費量なども考慮する必要があり、この点については注意が必要です。
| 項目 | 単位 | 概要 |
|---|---|---|
| モデル展開サイズ | GiB | 推論時にGPUメモリ上へ展開されるモデルのサイズ |
| TTFT(Time To First Token) | 秒(ms) | リクエスト送信から最初のトークンが返却されるまでの時間 簡単に言うと、チャットを送信した後、回答の一文字目が出力されるまでの時間 |
| Decode Throughput | token/s | トークン生成(decodeフェーズ)における生成速度 |
💡 補足:Prefill/Decodeとは?
推論には「Prefill」と「Decode」といった2つのフェーズがあります。
Prefillは、入力されたプロンプトをモデルが読み込むフェーズです。
プロンプトが長いほどこの時間が増え、長文入力時に影響が大きくなります。(=TTFTに影響します)
Decodeは、モデルがトークンを1つずつ生成していくフェーズで、実際の文章生成速度に直結します。
LLMをチャットアプリ形式で利用した際に、回答生成時のレスポンス(早い/遅い)を特に体感しやすい部分です。
- Prefill:質問文を読み込んで「考える準備」
- Decode:1トークンずつ回答を「作成する時間」
4. ベンチマーク手法とパラメーター
ベンチマークには、vLLMに標準で提供されているvllm benchを使用しました。
vllm benchは、vLLMの推論性能を評価するために提供されている公式ベンチマークツールで、OpenAI 互換APIエンドポイントに対応しています。
今回の検証では、このOpenAI API互換という特性を活かし、vLLMに限らず、SGLang、ollamaといった他の推論フレームワークについても、vllm benchでベンチマークを取得します。
これにより、下記の3点で公平なベンチマーク結果を得ることができると考えています。
① クライアント側(ベンチマーク実行側)の実装を共通化できる
② 推論フレームワークごとの差分や、API実装や測定ロジックの違いによる影響を最小限に抑えられる
③ 実運用で一般的な「OpenAI互換API経由での推論呼び出し」に近い形で評価できる
また、今回の検証で使用したvllm benchのパラメーター設定は下表の通りです。
vllm benchでは同時実行数(並列数)を指定することが可能ですが、本検証では基本的な応答性能に着目するため、並列処理は行わず同時実行数は「1」に固定しています。
※パラメーターは必要な部分のみ抜粋して記載しています
| 項目 | 設定値 | 意味 | 備考 |
|---|---|---|---|
| --dataset-name | random | 入力プロンプトをランダム生成するデータセット | ランダムトークンを生成しベンチマーク用リクエストとして利用 |
| --max-concurrency | 1 | 最大同時実行数 | 並列度を変えてスケール特性を見るためのツマミ ※今回の検証では並列処理はさせない |
| --random-input-len | 1024 | ランダム入力のトークン長 | |
| --random-output-len | 1024 | ランダム出力のトークン長 | |
| --ignore-eos | 有効 | EOS(終了トークン)を無視し、指定長まで生成させる | 出力トークン数を固定し、比較しやすくするため |
※ollamaは、独自APIに加えOpenAI互換API対応でもあるのでvllm benchを用いた測定も可能ですが、vllm benchはHugging Face上のモデル利用を前提としており、トークナイザーとしてHugging Faceのものが使用されていました。
ollamaは独自のモデル管理(GGUF)を行っているため、vllm bench経由での測定では、ollama本来の挙動や性能特性を正確に反映できない可能性があることから、本記事ではvllm benchによるollamaの測定結果については参考値として扱い、結果の解釈には注意が必要です。
ただし、詳細は割愛しますが、ollama公式のベンチツールで測定した結果とそこまで大きな乖離はなかったことも補足しておきます。
5. ベンチマーク結果一覧
これまでの手順で実施したベンチマーク結果を以下に整理します。
| GPU | エンジン | コンテナ | モデル | 重み形式(量子化/精度) | モデル展開サイズ(GiB) | TTFT(ms) | Decode Throughput(tok/s) |
|---|---|---|---|---|---|---|---|
| GB10 | vLLM | nvcr.io/nvidia/vllm:25.12-py3 | openai/gpt-oss-120b | MXFP4 | 65.9287 | 67.73 | 34.57 |
| openai/gpt-oss-20b | MXFP4 | 13.7025 | 49.45 | 45.54 | |||
| nvidia/Llama-3.3-70B-Instruct-NVFP4 | NVFP4 | 39.8080 | 245.97 | 4.51 | |||
| meta-llama/Llama-3.1-8B-Instruct | BF16 | 14.9889 | 81.01 | 13.60 | |||
| meta-llama/Llama-3.2-3B-Instruct | BF16 | 6.0156 | 42.23 | 26.62 | |||
| google/gemma-3-27b-it | BF16 | 51.3784 | 284.59 | 4.03 | |||
| google/gemma-3-12b-it | BF16 | 23.2634 | 134.78 | 7.26 | |||
| SGLang | nvcr.io/nvidia/sglang:25.12-py3 | openai/gpt-oss-120b | MXFP4 | 58.08 | 53.23 | 41.66 | |
| openai/gpt-oss-20b | MXFP4 | 12.57 | 27.72 | 58.99 | |||
| nvidia/Llama-3.3-70B-Instruct-NVFP4 | NVFP4 | 45.02 | 447.79 | 4.48 | |||
| meta-llama/Llama-3.1-8B-Instruct | BF16 | 15.65 | 129.55 | 13.99 | |||
| meta-llama/Llama-3.2-3B-Instruct | BF16 | 6.74 | 74.64 | 27.11 | |||
| google/gemma-3-27b-it | BF16 | 51.10 | 512.02 | 4.00 | |||
| google/gemma-3-12b-it | BF16 | 23.19 | 290.92 | 7.29 | |||
| lmsysorg/sglang:spark | openai/gpt-oss-120b | MXFP4 | 65.72 | 57.62 | 52.01 | ||
| openai/gpt-oss-20b | MXFP4 | 13.72 | 36.74 | 73.98 | |||
| nvidia/Llama-3.3-70B-Instruct-NVFP4 | NVFP4 | 44.98 | 505.07 | 4.10 | |||
| meta-llama/Llama-3.1-8B-Instruct | BF16 | 15.72 | 140.41 | 13.66 | |||
| meta-llama/Llama-3.2-3B-Instruct | BF16 | 6.62 | 79.72 | 26.16 | |||
| google/gemma-3-27b-it | BF16 | 52.30 | 514.13 | 3.84 | |||
| google/gemma-3-12b-it | BF16 | 23.34 | 291.41 | 7.13 | |||
| ollama | ollama/ollama:0.13.5 | gpt-oss:120b | MXFP4 | 60.56 | 243.72 | 40.65 | |
| gpt-oss:20b | MXFP4 | 12.4 | 223.31 | 54.30 | |||
| llama3.3:70b | Q4_K_M | 40.77 | 314.07 | 4.69 | |||
| llama3.1:8b | Q4_K_M | 5.27 | 118.24 | 39.25 | |||
| llama3.2:3b | Q4_K_M | 2.78 | 100.76 | 82.28 | |||
| gemma3:27b | Q4_K_M | 17.55 | 1478.41 | 10.90 | |||
| gemma3:12b | Q4_K_M | 8.7 | 742.46 | 24.56 |
今回の結果を見ると、openai/gpt-oss系モデルが全体として比較的良好な結果となりました。
20B/120BのいずれにおいてもTTFTが短く、Decode Throughputも「30 tok/s以上」と比較的高水準で、DGX Spark(GB10)上での推論用途として、性能と扱いやすさのバランスが非常に良いモデルという印象を受けました。
特に120B(gpt-oss)という大規模パラメーターモデルでも、一定のパフォーマンスを発揮できることを確認できた点は良かったと思います。
この点については、gpt-oss系モデルで採用されているMXFP4形式の量子化が、有効に機能している可能性が高いと思われます。
ollamaについてもllama系小規模モデルを中心に、比較的良好なDecode Throughputが確認できており、おおむね実用的な性能が得られていそうです。
また、実行環境の違いによる影響も一部で確認できました。
特にLMSYS ORG(Large Model Systems Organization)が提供するDGX Spark向けのSGLangコンテナでは、gpt-oss-20B/120BにおいてDecode Throughputが約20%向上しており、実行環境の最適化によって、性能改善の余地はありそうです。
一方で「NVFP4」に対して、個人的にやや期待していた部分もありましたが、今回の検証条件では性能向上は確認できませんでした。
モデルや推論フレームワークとの組み合わせ、あるいはパラメーター設定によって結果が変わる余地はありそうですが、少なくとも今回の構成では、必ずしもNVFP4が優位に働くとは言えない結果となっています。
6. チャットアプリとして実際に使ってみた体感
前章では、vllm benchを用いた数値ベースのベンチマーク結果について整理しました。
一方で、LLM推論環境を評価するうえでは、数値だけでは分からない使い勝手の部分も重要になります。
そこで実際にチャットとして利用した際に、ベンチマークで得られたDecodeThroughput(tok/s)の値がどのような体感につながるのかを試してみました。
ここでは、DGX Spark Playbooksに内にも記載があり、無料で利用できるOSSの「Open WebUI」を利用し、実際にモデルを切り替えながらチャットのやり取りをしました。
なお、Playbookでは下記URLにて「Open WebUI with Ollama」として公開されています。Open WebUIはコンテナ提供されており、ChatGPTライクなチャットインターフェースをすぐに使い始めることが可能で、ollamaと組み合わせることでモデルダウンロードもGUI上で行えます。
オンプレミス推論環境の検討の際には、Webフロントやアプリ開発が一つの検討事項になることも多いと思いますが、Open WebUIを利用することで、検証や実験用途としては十分な機能を手軽に揃えることができるため、初期検討や評価環境としておすすめです。(DGX Sparkの位置づけとも相性が良いですね。)
Open WebUI with Ollama | DGX Spark
6-1. Open WebUIのチャット画面イメージ
Open WebUIのチャット画面イメージを簡単にご紹介します。詳細は触れませんが、バックエンドの推論エンジンとの接続設定(Open WebUI上で設定可)を行えば、Webブラウザー上からすぐにチャット形式でLLMを利用することが可能です。
この画像からは「gpt-oss:120b」モデルが動作していることがわかります。
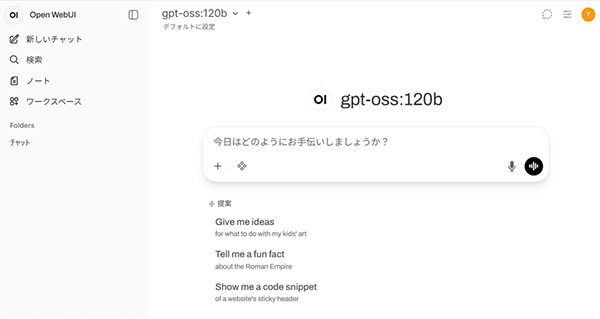
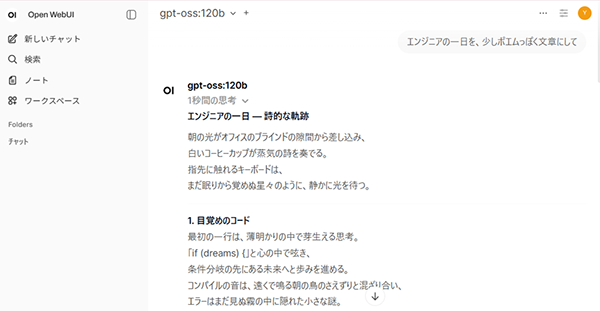
実際に少し長めの文章を出力させてみました。
本例の推論バックエンドは「ollama」です。ベンチマーク結果(Decode Throughput)は先述のとおり「40.65tok/s」であり、チャットとしての体感においては「待ち」を意識することなくスムーズに利用できている印象です。
※静止画のため、生成中のテンポを直接お伝え出来ない点はご容赦ください。
6-2. 体感の目安
あくまで、筆者の環境での超主観的な感想にはなりますが、下記にまとめておきます。
ちなみに、一般的に広く利用されているChatGPTなどは「30~50tok/s」と言われているようです。
| Decode Throughput | チャットとしての体感 |
|---|---|
| ~10tok/s | 明確に遅く感じる |
| 10~20tok/s | 待ち時間を感じ、実用は難しい |
| 20~30tok/s | 少々もたつきを感じるが、まだ実用レベル |
| 30tok/s以上 | ほぼストレスなく利用可能 |
7. まとめ
本記事では、DGX Sparkを用いて、複数の推論フレームワークおよびLLMモデルに対する推論ベンチマークと、実際の利用感の確認を行いました。
DGX Sparkの128GBという大容量メモリを活かし、120Bクラスの大規模なLLMを単体で実行・検証できる点が大きな強みであるとあらためて感じました。
もちろん、DGX Sparkは大規模GPUクラスタの代替ではありませんが、「ローカルで大きめのモデルを動かし、性能や挙動を把握する」という前段検証・評価用途においては、実用性の高いプラットフォームと言えるのではないかと思います。
今回は、LLM推論を中心とした検証に留まりましたが、128GBというDGX SparkのGPUメモリ容量を考えると、画像生成をはじめとした他の生成AIワークロードにおいても検証・評価用途として活用できる余地は十分にありそうです。
特に、
- 推論エンジンや量子化方式の比較
- モデルサイズごとの性能特性の把握
- チャット用途を想定したレスポンス確認
といった観点では、DGX Spark単体で完結した検証が可能であり、オンプレミス推論環境を検討する際の「最初の一歩」として適した選択肢の一つだと感じました。
「どのモデルを、どのフレームワークで、どのように使うか」を考えるきっかけとして、本記事の結果が少しでもヒントになれば幸いです。
※「NVIDIA」「NVIDIA DGX Spark」は、米国およびその他の国におけるNVIDIA Corporation の商標または登録商標です。
※「vLLM」はvLLM Projectの商標です。
※「Ollama」は、米国のOllama Inc.の商標または登録商標です。
※「Hugging Face」は、Hugging Face, Inc.の商標または登録商標です。
※「ChatGPT」は、米国Open AIの商標または登録商標です。