



トレンド
NVIDIA NeMoとは?カスタム生成AI開発を加速するワークフローを徹底解説
2025.12.26

GPUエンジニア

生成AIの活用がビジネス競争力を左右する時代において、自社データを活かしたカスタムAIモデルの内製化に注目が集まっています。しかし、汎用APIでは競争優位性を確立しづらい一方で、ゼロからのモデル開発には膨大なコストと高度な専門知識が必要となり、多くのプロジェクトが実証実験(PoC)の段階で停滞してしまうのが現状です。
この「理想」と「現実」のギャップを埋めるために、NVIDIAが提供しているのがエンタープライズ向け生成AI構築プラットフォーム 「NVIDIA NeMo™」 です。
本記事では、NeMoが数多くの企業に採用されている理由を、5つの主要メリットから解説します。さらに、AI開発の全工程を支える各種ツールのアーキテクチャ、具体的な導入シナリオ、そしてビジネス利用に不可欠なライセンス体系まで紹介します。
【目次】
- NVIDIA NeMoとは?
- NVIDIA NeMoが選ばれる理由:エンタープライズAI開発を加速する5つのメリット
2-1. データ準備から運用まで、一貫したエンドツーエンドのパイプライン
2-2. LLMから音声・マルチモーダルまで、多様なAIモデルを単一基盤で開発
2-3. クラウドからオンプレミスまで、あらゆる環境に対応する柔軟性
2-4. マルチGPU・マルチノードに最適化された、高速な処理性能
2-5. PEFT対応による、高い投資対効果(ROI) - AI開発のワークフローを支えるNeMoの包括的ソリューション
3-1. NeMo Curator
3-2. NeMo Customizer
3-3. NeMo Evaluator
3-4. NeMo Retriever
3-5. NeMo Guardrails
3-6. NVIDIA NIM - NVIDIA NeMoの導入シナリオ:4つのステップで実現するカスタムAI開発
4-1. NVIDIA提供のベースモデルを試す
4-2. モデルをカスタマイズする
4-3. Blueprintsを参考にソリューションを構築する
4-4. NVIDIA AI Enterpriseで本番環境へ展開する - NeMoのライセンスと利用形態
5-1. NVIDIA NeMo Framework
5-2. 商用サポートが含まれる「NVIDIA AI Enterprise」 - まとめ
1. NVIDIA NeMoとは?
NVIDIA NeMoは、企業が自社専用のカスタム生成AIモデルを開発するために設計された、エンドツーエンドの開発プラットフォームです。データ準備からモデルの学習・カスタマイズ、性能評価、安全性確保(ガードレール)、そして本番環境への展開(デプロイ)まで、AI開発のライフサイクル全体をカバーする包括的なツール群を提供します。
また、これらの機能は、必要なものだけを柔軟に組み合わせられるマイクロサービスとしても提供されており、柔軟に開発の効率を向上させることが可能です。

2. NVIDIA NeMoが選ばれる理由:エンタープライズAI開発を加速する5つのメリット
なぜ NVIDIA NeMo は、多くの企業に採用されているのでしょうか。その理由は、単なる個別ツールにはない、AI開発のライフサイクル全体をカバーする包括性にあります。NeMoは、開発効率を大幅に高めながら柔軟な運用を可能にし、企業に持続的な競争優位をもたらします。
ここでは、NeMoが支持される 5つの主要なメリット を順に紹介していきます。
2-1. データ準備から運用まで、一貫したエンドツーエンドのパイプライン
AIモデル開発では、データの前処理、学習、評価、デプロイといった各工程で、それぞれ異なるツールを使うのが一般的でした。しかし、このアプローチはツールの連携やバージョン管理に多大な労力を要します。
NVIDIA NeMoは、この課題を「エンドツーエンドのパイプライン」で解決します。データキュレーション(NeMo Curator)から始まり、カスタマイズ(NeMo Customizer)、評価(NeMo Evaluator)、安全性確保(NeMo Guardrails)、そして本番展開(NVIDIA NIM™)まで、AI開発に必要なすべての工程を一つの統合されたプラットフォーム上で実行可能です。
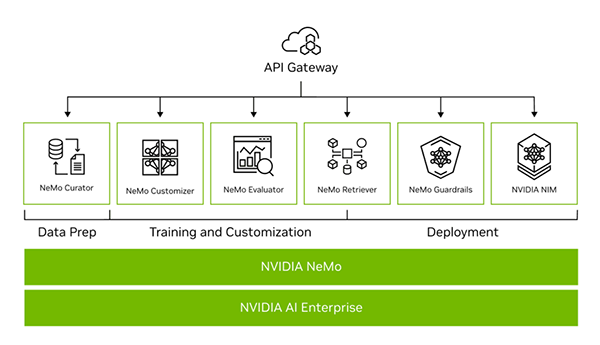
これにより、開発プロセスが大幅に簡素化され、開発者はモデルの本質的な改善に集中できます。
2-2. LLMから音声・マルチモーダルまで、多様なAIモデルを単一基盤で開発
今日のAI開発は、テキストを扱う大規模言語モデル(LLM)だけにとどまりません。音声認識(ASR)、音声合成(TTS)、そして画像と言語を同時に扱うビジョン言語モデル(VLM)など、ニーズに合わせて多様なモデルが活用されています。
NVIDIA NeMoは、これら多様なモデルファミリーを単一のフレームワークでサポートしています。開発チームは、タスクごとに異なる専門的なツールをすべて修得する必要はありません。さらに、Hugging Faceで公開されているような、コミュニティの主要なオープンソースモデルにも幅広く対応しており、既存の資産を活用しながら、最先端のモデル開発を迅速に始めることができます。
2-3. クラウドからオンプレミスまで、あらゆる環境に対応する柔軟性
ビジネスの状況やセキュリティ要件によって、AI開発に最適な環境は異なります。あるプロジェクトはクラウドで迅速に始めたいかもしれませんし、別のプロジェクトは機密データを扱うために自社のサーバー(オンプレミス)で実行する必要があるかもしれません。
NVIDIA NeMoは、特定の環境に縛られない高い柔軟性を備えています。AWSやAzureといった主要なパブリッククラウドから、自社のデータセンター、Kubernetesをはじめとするコンテナ環境まで、あらゆる場所で一貫した開発体験を提供します。
この柔軟性により、企業はインフラを気にすることなく、最適な場所でAI開発を推進できます。
2-4. マルチGPU・マルチノードに最適化された、高速な処理性能
現代の生成AIモデルは巨大化しており、その学習や推論には単一のGPUでは到底太刀打ちできません。
NVIDIA NeMoは、この課題を解決するために、マルチGPU・マルチノード環境での分散処理に徹底的に最適化されています。NVIDIAの「Megatron Core」や「Transformer Engine」といった中核技術を活用し、数百、数千のGPUを効率的に連携させ、学習時間を劇的に短縮します。
また、「TensorRT-LLM」との連携により、学習後の推論プロセスも高速化。開発から本番運用まで、あらゆるフェーズで最高のパフォーマンスを発揮します。
2-5. PEFT対応による、高い投資対効果(ROI)
AIモデルをゼロから学習させるには、莫大な計算コストと時間が必要です。しかし、多くのビジネスニーズは、既存のモデルを少しだけ自社のデータに適応させることで満たされます。NVIDIA NeMoは、PEFT(パラメータ効率の良いファインチューニング) と呼ばれる技術に標準で対応しています。
これは、モデル全体の巨大なパラメータを再学習するのではなく、ごく一部のパラメータだけを追加・更新することで、モデルを効率的にカスタマイズする手法です(例:LoRA, P-Tuning)。PEFTを活用することで、計算リソースと時間を大幅に節約でき、企業にとって投資対効果(ROI)の高いAI開発を実現します。
3. AI開発のワークフローを支えるNeMoの包括的ソリューション
AIモデルを実用化するプロセスは、一般的に「データ収集」「学習・カスタマイズ」「準備・デプロイ」という3つの主要な段階に分けられます。
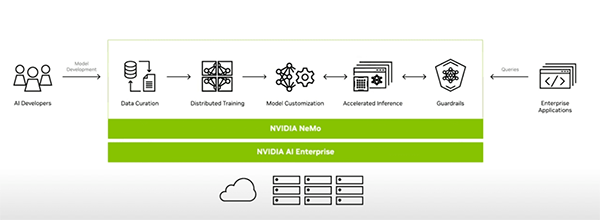
3-1. NeMo Curator(学習データの品質向上)
AIモデルの性能を左右する学習データの品質を、GPUアクセラレーションで高速に向上させるツールです。
大規模データセットからノイズや不適切なコンテンツを除去するデータクレンジング、学習効率を高める重複排除、コンプライアンスを確保する個人情報マスキング、そして不足データを補うデータ拡張といった一連の処理を高速に実行します。
3-2. NeMo Customizer(ファインチューニング)
既存の基盤モデルを、自社データに適応させる(ファインチューニングする)ためのマイクロサービスです。特に、計算コストを大幅に削減できるPEFT(Parameter-Efficient Fine-Tuning)に重点を置いており、LoRAやP-Tuningといった手法を用いて、少ない計算リソースで効率的にモデルを特化させることが可能です。
3-3. NeMo Evaluator(モデル評価)
カスタマイズしたLLMの性能を、客観的な指標で体系的に評価するためのマイクロサービスです。MMLUやBigCodeなど数百種類に及ぶ学術ベンチマークでの自動評価、自社データでの実用的な精度評価、さらには別のLLMを「審査員」とするLLM-as-a-judgeを用いた多角的な評価などにより、モデルの品質を客観的に把握できます。
3-4. NeMo Retriever(RAG構築サポート)
RAG(Retrieval-Augmented Generation)アーキテクチャの構築を支援するマイクロサービス群です。社内のPDFやオフィス文書などをAIが検索可能な形式で取り込み(Ingestion)、ユーザーの質問に対して意味を理解したセマンティック検索で関連情報を抽出します。その情報を根拠にLLMが回答を生成することで、信頼性の高い応答を実現します。
3-5. NeMo Guardrails(ポリシー制御)
LLMが不適切な応答をしたり、定義された役割から逸脱したりすることを防ぐ、オープンソースのポリシー制御エンジンです。会話のトピックを限定するトピックガードレール、有害なコンテンツ生成を防ぐセーフティガードレール、悪意のある外部ツール実行を阻止するセキュリティガードレールといったルールを定義し、安全で信頼できるAIアプリケーションを構築します。
3-6. NVIDIA NIM(推論・デプロイ)
学習済みのモデルを、実際のアプリケーションから利用可能な推論エンドポイントとして展開(デプロイ)するためのマイクロサービスです。TensorRT-LLMで最適化されたモデルをコンテナ化し、業界標準のAPIを通じて簡単にアプリケーションへ統合します。NVIDIA AI Enterpriseの一部として、セキュリティと安定性が保証された本番運用を可能にします。
このように各ツールが連携し包括的に動作する点は、NeMoならではの大きな強みだといえるでしょう。
4. NVIDIA NeMoの導入シナリオ:4つのステップで実現するカスタムAI開発
次に、NeMoの導入シナリオを考えてみましょう。本項では、NVIDIA NeMoを含むNVIDIAソフトウェアスタックを用いたカスタムAIモデルの開発から本番運用まで、以下の4つのステップで進めることを想定し解説します。
- モデルを試す
- モデルをカスタマイズする
- ソリューションを構築する
- 本番環境で運用する
4-1. NVIDIA提供のベースモデルを試す
最初のステップとして、NVIDIAがAPIとして提供している学習済みモデルを試し、その性能を評価してみるところから始めましょう。
• NVIDIA APIカタログ
様々なタスクに合わせて最適化された公式モデルがリスト化されており、目的に合ったモデルを選択するだけで体験することができます。
• NVIDIA NIM
選択したモデルは、NIM(NVIDIA Inference Microservice)を通じてAPIとして提供されます。開発者は複雑な環境構築なしに、数行のコードでモデルを呼び出し、自社のアプリケーションで基本的な動作を簡単に検証できます。
4-2. モデルをカスタマイズする
ベースモデルの性能を確認したら、次に自社のデータやユースケースに合わせてモデルを最適化するフェーズへ移行しましょう。
この段階で、これまで解説してきたNVIDIA NeMoのツール群(NeMo Curator, Customizer, Evaluator, Retriever, Guardrails)が活躍します。これらのツールを組み合わせることで、汎用的なベースモデルを、自社の業務知識を反映した高精度な「専用モデル」へと進化させることが可能です。
4-3. Blueprintsを参考にソリューションを構築する
カスタマイズした専用モデルを、実際のアプリケーションや業務フローに組み込みます。
このステップを加速するのが、AIソリューションの参照アーキテクチャ集であるNVIDIA AI Blueprintsです。RAGを活用したチャットボットや文書要約システムなど、一般的なユースケースのサンプルコードや設計図が提供されており、これらをテンプレートとして活用することで、ゼロから開発する手間を大幅に削減できます。
4-4. NVIDIA AI Enterpriseで本番環境へ展開する
最終ステップとして、構築したAIソリューションを本番環境へ展開し、実運用を開始します。
PoC(実証実験)段階ではNIM単体での利用も可能ですが、ミッションクリティカルな企業ユースケースではNVIDIA AI Enterpriseとの組み合わせが強く推奨されます。NVIDIA AI Enterpriseは、長期的なセキュリティパッチの提供、APIの安定性保証、SLA(サービス品質保証)を含むエンタープライズグレードのサポートを提供します。
これにより、開発したAIモデルを「研究成果」で終わらせることなく、ビジネスの現場で安心して継続的に活用するための体制が整います。
5. NeMoのライセンスと利用形態
NVIDIA NeMoには、利用目的やサポートレベルに応じて、大きく2つの利用形態が存在します。自社の状況に合わせて適切な形態を選択することが重要です。
5-1. NVIDIA NeMo Framework
NVIDIA NeMoの技術基盤であり、誰でも無料で利用を開始できるのが、GitHub上で公開されているオープンソースソフトウェア「NVIDIA NeMo Framework」です。
| 項目 | 詳細 |
|---|---|
| ライセンスと費用 | Apache 2.0ライセンス、無料 |
| 対象ユーザー | 研究者、個人開発者、技術実験・学習目的のユーザー |
| 入手方法 | GitHubからのソースコードダウンロード、NGCコンテナのプル |
| サポートと保証 | 公式サポート、動作保証、SLA等は対象外(自己責任での運用) |
NeMo Frameworkは技術的な探求や初期の検証フェーズにおいて非常に強力な選択肢となります。
5-2. 商用サポートが含まれる「NVIDIA AI Enterprise」
NeMoの便利なマイクロサービス群を、本番環境で運用するための包括的なサポートと保証を提供する商用ソリューションが「NVIDIA AI Enterprise」です。
| 項目 | 詳細 |
|---|---|
| ライセンスと費用 | 年間サブスクリプション(GPU数ベース、価格は構成により変動) |
| 対象ユーザー | 本番環境でAIを商用利用する企業 |
| 主な入手方法 | NVIDIA認定パートナー(オンプレミス)、主要クラウドマーケットプレイス、90日間の無料評価ライセンスあり |
| サポートと保証 | NeMoマイクロサービスの利用権、NVIDIAによる技術サポート、安定稼働・セキュリティ保証、SLA など |
※NVIDIA AI Enterpriseの契約により、NeMo Frameworkに加えてGuardrailsやCustomizer、NIMといったマイクロサービス群を本番環境で利用できますが、一部のモデルやサービスには、製品固有条項やモデルライセンスが追加で適用される場合があります。そのため、「AI Enterprise契約さえあれば全てが無制限に使える」というわけではない点には留意が必要です。
利用形態の比較
ここまで説明した2つの利用形態の主な違いを、以下の比較表にまとめます。
| 比較項目 | オープンソース(NeMo Framework) | NVIDIA AI Enterprise |
|---|---|---|
| ライセンス費用 | 無料 | 有料(GPU数ベースの年間サブスクリプション) |
| 主な用途 | 研究、開発、技術検証 | 本番環境での商用運用 |
| NVIDIAサポート | なし(コミュニティベース) | あり(SLA含むエンタープライズサポート) |
| セキュリティ | 自己責任 | NVIDIAによる継続的なアップデート保証 |
| 最適なユーザー | 個人開発者、研究者、技術評価チーム | ビジネスとしてAIを運用する企業 |
この表から分かる通り、どちらの形態が最適かは、AI活用のフェーズや目的によって明確に分かれます。PoCや研究開発の段階ではオープンソース版が適している一方、ビジネスとして本格的に運用する際には、NVIDIA AI Enterpriseが選択肢となります。
6. まとめ
NVIDIA NeMoは、企業が自社専用の生成AIを効率的に作り、安心して本番運用まで進められるように設計されたフレームワークです。データ準備からモデル学習、評価、安全対策、そしてデプロイまでを一貫してカバーしていることが大きな強みです。特に、開発スピードの向上、業界固有の知識を組み込んだ高精度なカスタムモデルの構築、さらに小規模な試作から大規模システムまで一貫して同じ基盤で動かせるスケーラビリティも備えているため、PoC止まりではなく実際の業務活用につなげられます。
生成AIが急速に広がる今、NVIDIA NeMoは企業が独自のAI資産を築き、競争力を高めるための重要な選択肢になります。研究開発にとどまらず、実際の業務改善や新規サービス創出に直結するソリューションとして、今後ますます注目されるでしょう。
NTTPCは、NVIDIAエリートパートナーとして、お客さまのAI基盤構築をワンストップで支援します。NVIDIA AI Enterpriseの導入や、カスタム生成AI開発基盤の構築に関するご相談など、お気軽にお問い合わせください。
▶︎ お問い合わせはこちら
※NVIDIA、NVIDIA NeMo、NVIDIA NIM、NVIDIA AI Enterpriseは、米国およびその他の国におけるNVIDIA Corporationの商標または登録商標です。
※本記事は2025年10月時点の情報に基づいています。製品に関わる情報等は予告なく変更される場合がありますので、あらかじめご了承ください。NVIDIAが公表している最新の情報が優先されます。